




- @2301_81888214
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
开源大模型如LLaMA,Qwen,Baichuan等主要都是使用通用数据进行训练而来,其对于不同下游的使用场景和垂直领域的效果有待进一步提升,衍生出了微调训练相关的需求,包含预训练(pt),指令微调(sft),基于人工反馈的对齐(rlhf)等,以提高其在特定领域的性能。

本文将以 LangChain 框架为核心,结合 GPT-4o-mini 模型,通过接入工具与消息修剪策略,实现一个具备记忆、调用搜索、执行函数能力的智能体。
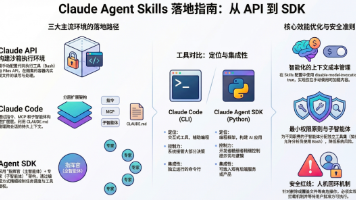
本文作为实战收官之作,将聚焦于如何在 Claude API、Claude Code、Claude Agent SDK 三大平台上真正上手使用 Skills,完成从理论到落地的最后一公里。
MiniMind系列极其轻量,最小版本体积是 GPT-3 的 1/7000,力求做到最普通的个人GPU也可快速训练,这不仅是大语言模型的全阶段开源复现,也是一个入门LLM的教程

大模型应用开发 | Java开发者如何成功转型AI大模型?
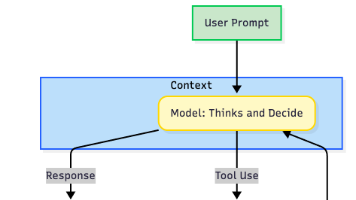
一个 Agent 的核心原理非常简单:它是一个大型语言模型(LLM)在一个循环中运行,并配备了它可以选择使用的工具。
众所周知,大语言模型(LLM)正在飞速发展,各行业都有了自己的大模型。其中,大模型微调技术在此过程中起到了非常关键的作用,它提升了模型的生成效率和适应性,使其能够在多样化的应用场景中发挥更大的价值。

vLLM 是一个高性能的大型语言模型推理库,支持多种模型格式和后端加速,适用于大规模语言模型的推理服务部署。
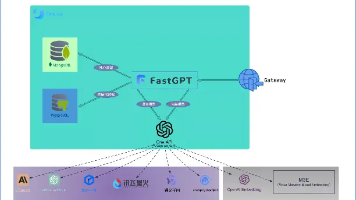
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力,它背后依赖OneApi开源项目来访问各种大语言模型提供的能力。
Ollama 是一个可以在本地部署和管理开源大语言模型的框架,由于它极大的简化了开源大语言模型的安装和配置细节,一经推出就广受好评,目前已在github上获得了46k star。