登录社区云,与社区用户共同成长
邀请您加入社区
这三个是K8s 云原生架构中最核心的三大模块:●Prometheus Operator:监控体系核心(指标监控、告警)●Loki:日志体系核心(轻量日志收集、查询)●MySQL 组复制(MGR):数据库高可用核心(分布式强一致集群)
本文通过港口运维的比喻,系统介绍了云原生核心技术栈:Docker作为标准化容器技术,实现应用封装与隔离;Kubernetes作为容器编排系统,自动化部署与管理容器集群;Prometheus+Grafana构成监控体系,实时观测系统状态。文章重点解析了Docker的镜像分层、容器网络、数据持久化机制,Kubernetes的Pod调度、探针检测等核心概念,并以实际配置示例展示如何实现高效运维。这种"集
如果未针对特定业务(如美团)进行专门“学习”,面对直接相关的问题时,无法给出理想的答案。通过文本向量化模型(如OpenAI的EmbeddingModel),将文本转换为向量,并存储于向量数据库(如Redis)。整合用户问题和检索出的相关知识,形成统一的UserMessage,并发送给大模型。中的内容切分成独立的Segments,每个Segment代表一个问答对。对用户问题进行文本向量化后,在向量数
Prometheus 是一个开源的系统监控和告警工具包,最初由 SoundCloud 开发,现在是 CNCF(云原生计算基金会)的毕业项目。
安装了k8s v1.29,三台机器如下目标: 安装prometheus, 从springboot获取指标,实现告警。springboot自定义一个指标“my-count”, 每访问springboot接口一次,“my-count"加1,当大于10时,给出告警。主要用到prometheus和alertManager这两个服务。大概流程是:1.prometheus去查springboot接口获取“my
Redis Exporter 是 Prometheus 生态中核心的 Redis 监控工具,支持单机、主从、哨兵、Cluster 集群等多种部署模式,能采集连接数、内存使用率、命中率、键空间、集群状态等全量指标。
global:alerting:- targets:labels:介绍一下如下:scrape_interval: 15s #每隔15秒向目标抓取一次数,默认为一分钟evaluation_interval: 15s #每隔15秒执行一次告警规则检查,默认为一分钟scrape_configs指定的是prometheus要监控的目标,这里是整个prometheus的核心部分,在srape_config中
普罗米修斯监控部署
本文详细介绍了在Linux系统中搭建Prometheus监控系统和Grafana可视化平台的完整过程。主要内容包括:1)下载并配置Prometheus,创建专用用户和启动服务;2)部署node_exporter采集节点数据,配置多服务器监控;3)安装Grafana并进行服务配置。文档提供了详细的命令操作、配置文件修改说明及效果截图,最终实现通过Prometheus采集服务器指标数据,并通过Graf
Metrics 的类型如下:常用的如 Counter,写过 mapreduce 作业的开发人员就应该很熟悉 Counter,其实含义都是一样的,就是对一个计数器进行累加,即对于多条数据和多兆数据一直往上加的过程。Gauge,Gauge 是最简单的 Metrics,它反映一个值。比如要看现在 Java heap 内存用了多少,就可以每次实时的暴露一个 Gauge,Gauge 当前的值就是heap使用
注意:这里添加的一定要在 /opt/prometheus/prometheus.yml文件中操作,否则会导致后续prometheus中没有node节点,grafana表盘中无数据。点击Endpoint目标的值,再从exporter具体能抓到的数据,随便复制一个值就好,比如go_gc_pauses_seconds_count。访问:http://IP地址:3000,默认账号/密码:admin/adm
prometheus监控redis需要使用redis_exporter组件,本文包含redis_exporter的安装、prometheus配置、grafana配置、告警规则文件配置。外发告警配置(邮件告警、企业微信告警)不在本文描述,可参考中告警信息配置。
参考kube-prometheus部署。
我整理的一些关于【Docker】的项目学习资料(附讲解~~)和大家一起分享、学习一下:https://edu.51cto.com/surl=QsXoR2使用 N9E Docker 部署 Prometheus 的完整指南引言在现代云计算和微服务架构中,监控和性能分析是非常重要的组成部分。Prometheus 作为一款开...
我们上一小节对Prometheus做了一个简单的介绍,本小节我们就来介绍下Prometheus的安装。Prometheus支持通过二进制包、Docker 容器、Kubernetes Operator(如 Prometheus Operator)来进行安装。
一、部署prometheus采集系统数据的工具1.1 部署node_exportenode_exporter 是prometheus的一部分,用来装在被监控的服务器上下载地址:https://prometheus.io/download/#1.解压安装包tar-zxvfnode_exporter-1.7.0.linux-amd64.tar.gz#2.启动默认监听9100端口建议使用...
关系型 mysql,oracle,sql server,sybase,db2,access等非关系型(nosql) key-value memcache redis etcd文档型 mongodb elasticsearch列式 hbase时序 prometheus图形数据库 Neo4j这里平均值写3就行了,因为要测试mysql连接数保存后,进行验证,在终端多连接几台mysql此时查看手机信息和邮
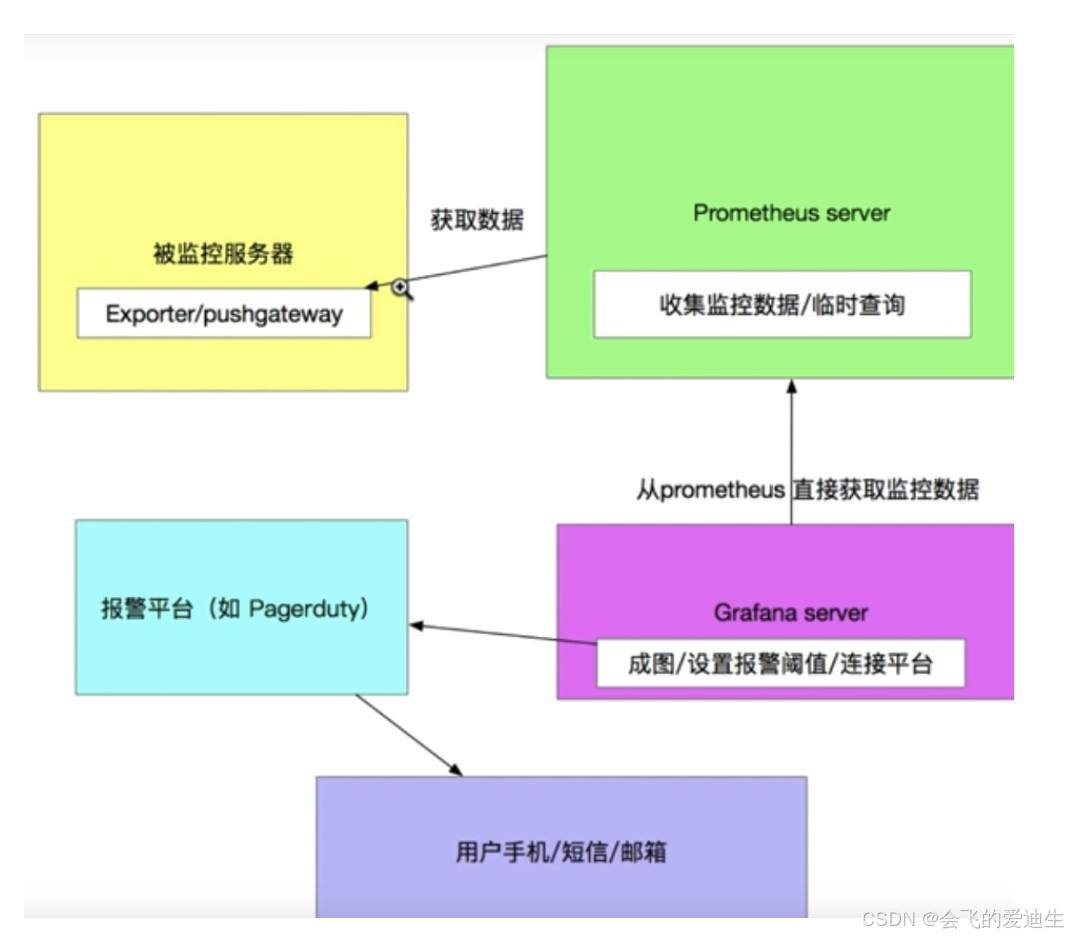
grafana:看板工具,所有采集的性能数据都会展示在这个看板上,官网:linkPrometheus: 监控系统,数据的采集、存储、查询等主要功能都是在它这里,参考文档:linknode_exporter:其是Prometheus的一个采集组件,可以用来采集机器上的数据,并暴露接口给Prometheus,以此将数据传过去。这是prometheus官网的架构图,可以参考这个看一下。
(使用 Values 文件)直接使用 helm install会采用 Chart 的默认配置。要自定义(例如设置持久化存储、配置抓取规则、修改 Grafana 密码等),你需要一个自定义的 values.yaml文件。编辑 custom-values.yaml文件,根据你的需求修改配置。
我们除了可以直接使⽤社区提供的Exporter以外,还可以基于Prometheus提供的Client Library创建适合⾃⼰的Exporter程序,⽬前Promthues社区官⽅提供了对以下编程语⾔的⽀持:Python 、Go、Java/Scala、Ruby等。同时还有第三⽅实现的如:Bash、C++、Lua、Node.js、PHP、Rust等。node exporter主要用于采集被监控主机
【代码】Prometheus实战教程:k8s平台手动部署Grafana。
g.Add(select {return nilreturn nil},},开启一致性哈希环变更监听处理这个服务的节点变更了(节点宕机、扩容)就对哈希环进行重置consul中watch 服务中节点变化遍历所有的service和变更chan的map,开启watch。
安装手册便于大家安装
倒排索引(英文:Inverted Index),是一种索引方法,常被用于全文检索系统中的一种单词文档映射结构现代搜索引擎绝大多数的索引都是基于倒排索引来进行构建的这源于在实际应用当中,用户在使用搜索引擎查找信息时往往只输入信息中的某个属性关键字,如一些用户不记得歌名,会输入歌词来查找歌名;输入某个节目内容片段来查找该节目等等倒排索引源码解析创建索引的过程查找索引的过程优化工作seriesId求交集
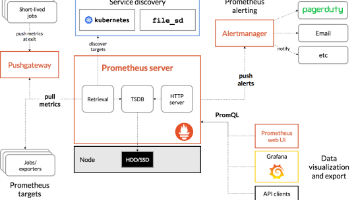
pushgateway部署在客户端后查看 http://xxxx:9091/metrcs/ 页面是没有任何数据的,还需要写脚本抓取数据并推送给pushgateway才能有数据,然后pushgateway再把数据推送给prometheus。• 过去5分钟的数据:rate(node_network_receive_bytes_total{instance=“192.168.1.202:9100”, d
本文介绍通过powershell脚本部署windows_exporter并把指标展示在grafana上。
在不改变原配置的情况下使用java+prometheus自定义nginx的p99指标且暴露接口,并用grafana展示p99耗时数据。2.openresty需要自定的lua脚本、各种的配置和nginx-plus都会改变原先的nginx结构。1.nginx-prometheus-exporter和nginx-vts 两种是无法暴露这个指标的。
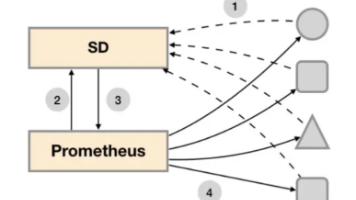
简介如图: SD模块是专门负责发现需要监控的target信息,prometheus去SD模块订阅该信息,有target信息会推送到Prometheus,然后Prometheus拿到target信息后通过pull http 协议去拉取该指标的数据。静态服务发现机制,配置简单,但是监控目标是写死在了配置文件中,如果要新增、修改、删除监控节点时,需要每次都去修改配置文件,然后再通知prometheus重
Prometheus v3.5.0 作为一款长期支持的稳定版本,适合需要持续运行和长期维护的生产环境。推荐用户尽快升级以享受性能提升、稳定性增强以及新功能带来的便利。备份现有规则和配置文件;关注 Prometheus 组件如 Alertmanager、Grafana 等的兼容性;评估实验性功能的使用需求和风险;关注集群规模和监控指标变化,合理调优采集频率和存储设置。本次版本全面提升了 Promet
本文详细剖析了Prometheus告警系统的完整流程:1)数据采集阶段由Node Exporter暴露指标,Prometheus定时拉取;2)规则计算阶段将数据存入TSDB并周期性评估告警规则;3)告警触发阶段根据条件状态变更发送告警至Alertmanager;4)告警处理阶段完成去重、分组等操作后发送通知。配置部分包含告警标签管理(relabel配置)和Alertmanager设置,通过YAML
监控平台包含基本组件:grafana、prometheus、node-exporter、alertmanager、loki、alloy,实现对服务器的监控,对Java应用的监控,对服务器异常的报警,对Java服务异常的报警,日志的抽取和查看
本文介绍了使用kube-prometheus在Kubernetes集群中部署完整的Prometheus监控方案。基于Kubernetes v1.32.5环境,选择kube-prometheus release-0.16版本,部署内容包括:通过NodePort暴露Prometheus、Grafana和Alertmanager服务;为Prometheus启用basic-auth认证;配置多副本部署并集
它们是独立运行的程序,负责从第三方服务(如 MySQL、Redis)采集原始数据,并将其转换为 Prometheus 要求的格式,通过一个 HTTP 端点(通常是。: Prometheus 自带的一个简单的Web界面,主要用于执行 PromQL 查询和调试。最主流的可视化工具,可以接入 Prometheus 作为数据源,创建丰富、炫酷的监控大盘。时序数据库**中,再通过灵活的查询语言实现监控和告警
自定义报警使用钉钉推送消息安装配置方法修改 alertmanager 配置,接入 dingtalk-hook# 先将之前的 secret 对象删除 $ kubectl delete secret alertmanager-main -n monitoring。
【代码】Prometheus监控。
取指定时间范围内所有数据点,取平均值作为结果。:取指定时间范围内的最近两个数据点计算速率。:画出的线比较毛刺,更能够反映出真实的情况。:画出的线比较平缓,有削峰的作用。
Pushgateway作为Prometheus监控系统的中间组件,采用被动推送方式接收监控数据。文章详细介绍了Pushgateway的安装配置、数据推送方法(单条/多条数据、脚本推送)、数据删除操作,以及Prometheus集成配置。同时阐述了Prometheus的四种自动发现机制(静态配置、文件、DNS、Consul)及其实现步骤。最后系统讲解了PromQL查询语言,包括数据类型、选择器、操作符
在prometheus解压后,就自带一个prometheus.xml。
再131 132 133 这三台节点上都这么干132133。
普罗米修斯是一个开源的,可以容器化部署(pod),部署在k8s集群中,也可以直接部署在宿主机的二进制的方式部署。在k8s集群当中,一般都是用普罗米修斯来对集群进行监控。普罗米修斯:开源的服务监控系统和时序数据库数据通过时序数据库来进行收集,展示数据模型,存储,以及提供插叙的接口。核心组件:prometheus server 从静态配置的监控目标,以及基于服务发现,自动从目标中拉取数据,保存到数据中
(1) 选择一个报警表盘——会多出一个Alert——创建报警规则(table方式的表盘不支持报警)https://www.bboy.app/2020/07/01/prometheus备份迁移/(2)增加一个D的报警策略:对B监控设置报警规则,表示平均值>1时出发告警,点击下面run。(1) 选择alerting——Contact points——编辑默认报警方式。(2) 填写收件人和发送测试内容—
它在本地存储所有报废的样本,并对这些数据运行规则,以汇总和记录现有数据中的新时间序列,或生成警报。这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。由于grafana没有使用持久存储
promethus+周边组件搭建监控
这篇文章基于我们公司的架构分析,架构不具备普适性,但其中的优缺点可以作为参考。Zabbix + Prometheus 双栈落地 AIOps 方案
pushgateway的简单使用
启动成功之后,前往网页输入:http:192.168.190.148:3000(http://本机ip:3000)A、pkill prometheus##终止Prometheus进程(因为第③步启动了Prometheus)E、systemctl status prometheus.service##查看Prometheus状态。D、systemctl start prometheus.servic
安装ubuntu20.04修改源安装搜狗。
prometheus 运维中遇到的问题
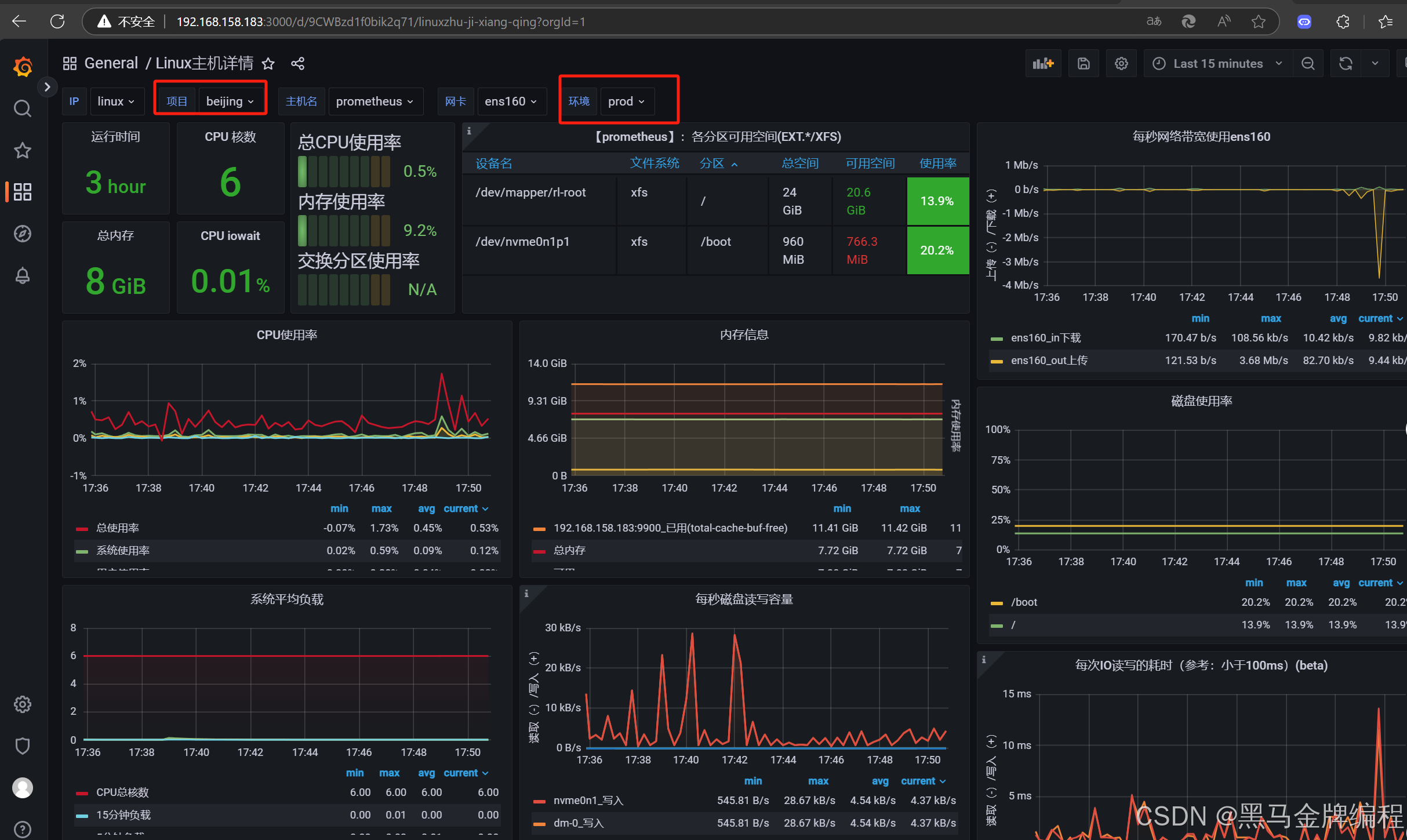
基于Prometheus+Grafana实现Linux操作系统的监控与可视化
打开,找到安装,其中需要下载prometheus,启动里面的脚本文件,可以直接自己创建脚本文件。脚本1:这个脚本屏蔽了下载geographiclib的步骤,这个可以直接执行可能无法下载,后续可以将下载好的文件直接拷贝到对应文件夹。脚本2:这个需要放置在src目录下,进行mavros和mailing下载。
prometheus
——prometheus
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区