- @aolan123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果你错过了2012年的微信公众号,也错过了2015年的短视频,那么一定不要错过2025年的AI Agent(智能体)。若2012年开始写公众号,2015年拍短视频,只要用心认真,持续优化,并坚持下来,结果一定不会差。在我看来,实现财务自由问题并不大。而今天,如果你不研究和学习AI,未来可能会面临失业的风险,至少会让你在未来的竞争中处于不利的位置。而AI Agent是AI的升级版,使用门槛更低,甚
AI领域发展特别块,春节期间大家还在被Deepseek刷屏,前几天就又被Manus刷屏,很多人已经感受到了AI发展的速度。这里面Manus的火爆,核心就是他作为一款Agent终于拉开了AI Agent的竞争序幕。年前我们发布的2025年AI预测,Agent就是2025年AI竞争的主要领域。不过,很多朋友对AI Agent的工作原理和开发方法还存在很多疑问,包括很多人经常把AI和Agent混淆,经常

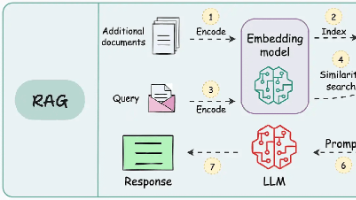
本文详细介绍了企业级RAG系统的完整实践架构,涵盖数据工程、文档嵌入、索引建立、向量数据库、检索前后处理及内容生成等环节。系统阐述了从Naive RAG到Agentic RAG的技术演进路径,提出模块化、自适应、多源融合等企业实践关键思路,并展望了更深度的业务集成、多模态RAG等未来发展方向,为企业构建智能知识服务系统提供全面指导。
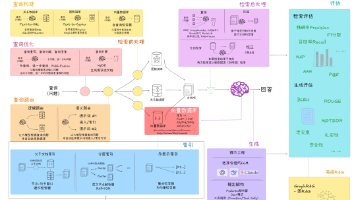
本文详细介绍了企业级RAG系统的完整实践架构,涵盖数据工程、文档嵌入、索引建立、向量数据库、检索前后处理及内容生成等环节。系统阐述了从Naive RAG到Agentic RAG的技术演进路径,提出模块化、自适应、多源融合等企业实践关键思路,并展望了更深度的业务集成、多模态RAG等未来发展方向,为企业构建智能知识服务系统提供全面指导。
DeepSeek回应网信办AI内容标识要求,承诺对AI生成内容添加"AI生成"标识。文章详细解析了DeepSeek V3/R1模型的训练过程,包括预训练和优化训练两个阶段,介绍了训练数据的来源和处理方式,以及模型推理过程。同时,讨论了AI的局限性和风险,以及DeepSeek的应对措施,强调了模型的开源特性和用户权利保护。
这篇文章介绍了基于大模型的AI智能测试分析系统,用于解决电信级系统测试复杂问题。系统通过深度解析测试用例、智能语义映射和构建语义索引,实现测试用例与代码的智能关联。结合依赖关系识别、模式分析和业务语义理解,快速定位问题并提供可解释解决方案。强调数据质量、专家参与和持续迭代的重要性,展示了从"人找问题"到"AI找问题,人做决策"的转变,为软件测试智能化提供实用指南。

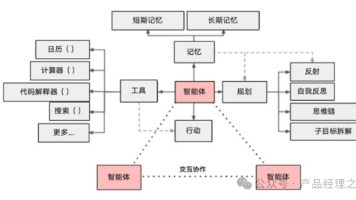
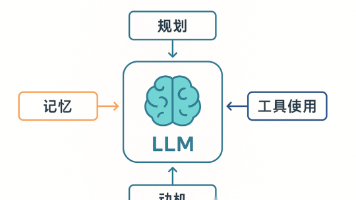
文章深入剖析了AI Agent的技术架构与挑战,指出Agent由大模型、规划、记忆和工具调用四部分组成。虽然Agent被寄予厚望,但当前仍面临幻觉、上下文限制、稳定性等硬伤。规划本质是提示词工程加搜索策略,工具调用存在覆盖面和稳定性问题,记忆系统也有局限。作者认为,Agent最有希望在内容娱乐和个人效率领域率先落地,每个技术环节都既是挑战也是机遇。
文章系统阐述了在Agentic AI技术快速发展背景下,如何构建可靠、高效且可落地的AI Agent应用。随着LLM和工具调用标准化,核心竞争力已转向提示词工程、工作流设计和知识库构建三大领域。详细介绍了系统提示词设计、使用DSL描述工作流、RAG与关系型数据库在知识库中的应用,以及安全防护策略。最后提出AI项目确定方法,强调应先确定业务问题,快速验证,持续迭代。

本文系统综述自进化AI智能体新范式,提出安全三定律与四阶段演进模型,构建统一优化框架,分类介绍单/多智能体优化技术及领域应用,并开源EvoAgentX框架。该技术使AI智能体能根据环境反馈自主优化提示、记忆、工具及协作拓扑,实现终身学习,为科研、医疗等领域提供可持续AI解决方案。

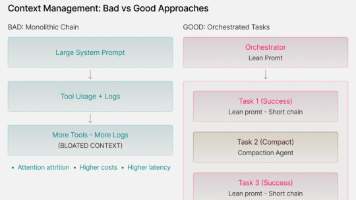
文章分享了构建高效AI Agent的六条原则:1)打磨清晰具体的System Prompt;2)合理拆分上下文避免过载;3)设计简洁明了的工具集;4)建立反馈闭环验证结果;5)利用LLM进行错误分析;6)从系统层面排查问题。强调高效Agent需依靠扎实的系统设计和软件工程方法,而非神奇提示词或酷炫框架。