- @weixin_58753619
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
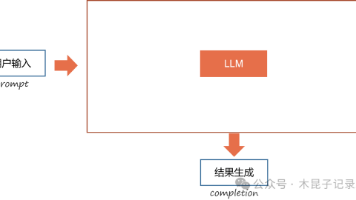
你提问→直接去向量数据库搜相似度最高 4 篇文档→丢给 DeepSeek 大模型直接回答,**一步到位,一锤定音
Claude Code、Codex 等 Coding Agent 产品的成功,已经证明了 Harness 的重要性。Blog系统梳理 **Harness Engineering** 的设计模式、优化层级,以及从 ACE 到 MCE 再到 Meta-Harness 的演进脉络。

Claude Code、Codex 等 Coding Agent 产品的成功,已经证明了 Harness 的重要性。Blog系统梳理 **Harness Engineering** 的设计模式、优化层级,以及从 ACE 到 MCE 再到 Meta-Harness 的演进脉络。
随着大语言模型(LLM)的广泛应用,如何让模型突破训练数据的限制、减少“幻觉”并回答复杂关系问题,成为业界关注焦点。本文将系统介绍最新的GraphRAG(基于图的检索增强生成)技术,从原理、架构到应用与未来挑战,全面解析知识图谱与大模型如何共创“可检索、可推理、可解释”的AI系统。

AI领域每隔一段时间都有新的概念和技术出来:年初DeepSeek火热带动深度推理模型,五一前阿里推出的Qwen3就升级为混合推理模型;3月份manus展示号称全球首款通用型智能体,到现在OpenAI和阿里也都有类似的通用Agent;Anthropic去年11月提出MCP标准,今年逐渐得到各大厂商的认可以后,Google今年4月份又提出A2A协议;Google去年底推出的DeepResearch研究
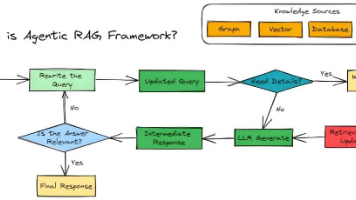
检索增强生成(RAG)彻底改变了AI系统访问和利用外部知识进行推理的模式。然而,随着应用场景复杂性的不断提升,传统RAG方法的局限性也日益凸显。如今,RAG正从单一的线性流程,进化为能够根据查询复杂度和上下文,动态调整检索与生成策略的智能自适应系统。
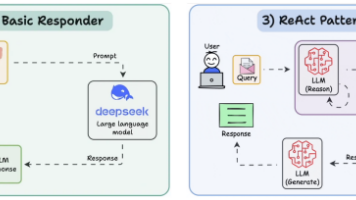
在构建智能体(Agent)的浪潮中,我们面临一个核心挑战:如何让Agent从一个简单的“问答机”,转变为一个能够自主规划、调用外部工具并解决复杂任务的“问题解决者”?**ReAct(Reasoning and Acting)** 模式正是为此而生,它提供了一种强大的范式,赋予大型语言模型(LLM)融合**内在思考**与**外在行动**的能力。
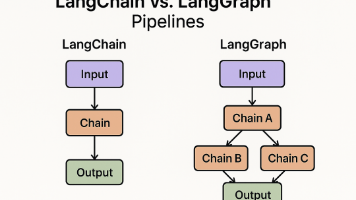
LangChain 和 LangGraph 出自于同一个团队,都被设计用于与 LLM 集成并协同工作,两者常被混淆。但顾名思义,两者有着显著的区别:
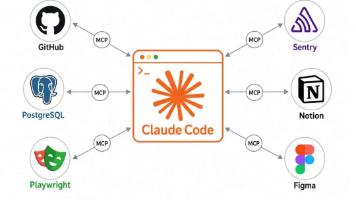
大多数时候,Claude Code 干的活基本都在你本地的代码和文件范围内。但在有时候,在真实开发场景里,信息是散的:需求躺在 GitHub issue 里,数据存在数据库里,线上报错堆在 Sentry 上,设计稿挂在 Figma 里。要让 Claude 用上这些,你只能一遍遍打开对应工具、复制内容、粘进对话框——干的全是人肉搬运的活。
有 G 友在评论区留言:这个文件既然这么重要,能不能单独写一篇来讲?非常可以,而且真值得单独讲!