




- @2301_81940605
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
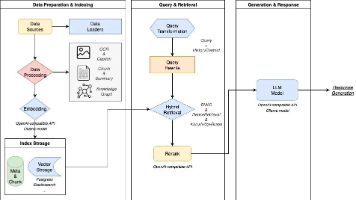
WeKnora 作为腾讯自研 RAG 框架,兼顾多格式文档处理、知识图谱自动抽取与存储、混合检索与扩展,架构清晰,功能实用。适合企业知识管理、智能问答等多种应用场景。项目仍有优化空间,值得持续关注。
【AI大模型】大语言模型与军事的结合
LangGraph是基于LangChain的智能体编排框架,它将 Agent 系统建模设计为(有向图)流程图,每个节点表示一个计算步骤进行状态的更新,每条边表示状态转移路径,适合处理复杂流程或多Agent 协作系统。
今天,我们就为大家带来了几个热门且最新的 GitHub 开源 LLM 大语言模型WebUI框架项目推荐。这些项目不仅能够帮助你快速构建自己的应用,还能让你体验到最前沿的技术成果。
本文主要针对想要或者正在从事大语言模型、知识库、搜索增强生成(RAG)的研发、产品和测试同学,在面试中会遇到什么样的问题?
本文将为你提供一份详细的“小白教程”,手把手教你如何在本地环境中部署Dify开源平台,并结合本地RAG知识库,打造属于你自己的智能体工作流。
拥有25年的分析开发经验,并获得了可扩展机器学习领域的博士学位。他的卓越贡献遍布众多期刊、会议、书籍和专利之中。其著作颇丰,包括《应用因果推断》、《可解释的人工智能》、《机器学习中的Transformer》、《深度学习与自然语言处理及语音识别》、《精通Java机器学习》以及《机器学习:Java开发者端到端指南》等。目前,他担任Smarsh公司的首席分析官,负责引领通信人工智能领域的数据科学与研究工

今天要介绍的RAGFlow,正是一款将前沿RAG与Agent能力深度融合的开源引擎——无论是个人搭建知识库,还是企业级部署,它都能帮你快速将复杂数据转化为生产级AI系统。

在今天的分享中,我将分享如何通过API来调用ollama服务,通过整合ollama API,将AI能力集成到你的私有应用中,提升你的职场价值!
Ollama是一款专注于简化大型语言模型本地部署和运行的开源框架,基于Go语言实现,支持跨平台运行,并以“开箱即用”为核心理念,适合个人开发者和轻量化场景。
