登录社区云,与社区用户共同成长
邀请您加入社区
android9 编译报错。
OpenClaw 上线数周暴露近 1000 个未认证实例、512 个漏洞(8 个高危),单次提问触发 19 轮 LLM 调用消耗 784 万 tokens。本文基于 AI Observe Stack(OpenTelemetry + Apache Doris + Grafana)搭建 AI Agent 可观测系统,实现安全审计、成本分析和行为追踪。
Apache Doris 定义 AI 时代实时分析三大范式:面向内部的分析、面向客户的分析、面向智能代理的分析。比亚迪查询提升 10 倍、申通 90% 任务从 10 分钟降至 1 分钟、京东日均 100 亿行、百度上万 QPS 亚秒级——本文拆解每个范式的配置要点和落地实践。:Apache Doris · 实时分析 · 三大范式 · SelectDB · BI 仪表板 · 用户画像 · AI Ag
单头注意力仅能捕捉单一维度的语义关联,表征能力有限,而多头注意力将特征向量拆分至多个独立注意力头,每个头独立学习不同的语义特征,分别捕捉语法结构、词汇搭配、上下文逻辑、远距离关联等不同维度的信息,最后将多组特征拼接融合,形成更全面、更精细的全局语义表征。从传统机器翻译的简单注意力,到Transformer的多头自注意力,再到当前稀疏注意力、滑动窗口注意力等优化方案,注意力机制的迭代升级直接推动了大
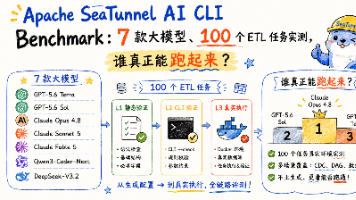
本次实验在统一的 100 个 SeaTunnel ETL 任务上,对 7 个模型进行测试。任务覆盖 20 个 Tier 1 基础同步任务、45 个 Tier 2 转换/CDC/参数约束任务,以及 35 个 Tier 3 复杂 DAG 任务;验证依次经过 L1 静态配置校验、L2 CLI/OptionRule 校验和 L3 Docker 化真实执行环境验证。L1 静态验证结果L1 用于验证模型能否生
如果AI真的普及了"绝对理性"的购物方式,它会瞬间扒开所有商品的底裤,把流量全部导向极致性价比的标品,直接摧毁平台赖以生存的广告竞价体系。抖音电商的崛起本身就是最好的证据,2024年抖音电商GMV达到3.5万亿,2025年更是突破4万亿大关,其中超过七成来自"兴趣电商",即用户在刷短视频时被内容激发出的非计划性消费。它天生是一个"参数党"和"比价狂魔"。当对话框里买不出GMV,当0.9%的增速戳破
在开发抖音小程序时,很多开发者都希望能接入智能对话能力,让用户在小程序内就能获得即时答疑、内容推荐或个性化服务。然而,从环境搭建到最终真机上线,中间涉及权限配置、密钥管理、接口调用、上下文记忆以及合规过滤等多个关键环节,任何一个步骤疏漏都可能导致调试失败甚至审核被拒。尤其是当面对高并发场景或复杂的鉴权机制时,缺乏系统性的实操指南往往会让开发过程变得曲折。这篇文章将基于实际开发流程,一步步拆解如何从
table-name框架特异性逻辑一致性给出明确Schema。
下面是我很早以前写的一篇文档,贴出来。1.Nginx1.1.安装Nginx 的中文维基 http://wiki.codemongers.com/NginxChs 下载Nginx 0.6.26(开发版)(请下载最新版本)tar zxvf nginx-0.6.26.tar.gz./configure,注意了类似checking for *** ... not
防火墙GE0/0/1 配置Trunk,允许VLAN2、3标签通过。VLAN3子接口 生产区PC2、PC3网关。VLAN2子接口 办公区PC1网关。# DMZ区域接口,连接LSW2。# PC1 办公区 VLAN2。# PC2 生产区 VLAN3。# PC3 生产区 VLAN3。# 安全区域绑定子接口。
本文针对工业Linux实时系统中的IRQ中断延迟问题,提出四大优化方案。首先介绍IRQ延迟对EtherCAT总线、机器人控制等场景的影响,分析其成因包括长ISR硬中断、中断随机扩散、冗余中断等。核心优化手段包括:1) PREEMPT_RT中断线程化,将耗时逻辑转为可抢占线程;2) irqaffinity中断绑核隔离;3) 屏蔽闲置外设中断;4) 内核参数调优。通过cyclictest测试验证,全套
这次开源仍然很有价值。开发者现在可以检查 Agent 如何读取文件、拼装上下文、调用 Shell、执行工具、加载 MCP 和保存会话,也可以修改源码、构建内部版本,并把模型端点替换成本地推理服务。
【已解决】org.apache.shiro.UnavailableSecurityManagerException
摘要:作者分享了解决 Apache POI 导出 Excel 时遇到的 NoSuchMethodError: UnsynchronizedByteArrayOutputStream.builder() 问题的过程。该问题源于 commons-io 库的版本冲突,导致运行时加载了旧版本。文章提供了三种解决方案:推荐升级 commons-io 至 2.15.1、排除旧传递依赖(不推荐)和使用 POI
默认端口号是8080.可以在apache安装目录下的conf下的server.xml,用记事本打开,修改8080端口号为8081,以后端口号就是8081,也可以不改。对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。在apache-tom
tomcat.util.scan.DefaultJarScanner.jarsToSkip=\ 值后面加",*"更改tomcat配置文件catalina.properties。
异常描述:the request was rejected because no multipart boundary was found。比如:如果你后端使用的是@RequestBody接受数据,那么,你的前端就必须传json格式的数据,而不是form-data表单格式的数据。解决方案:查看自己的前端请求数据类型和后端接口接受类型是否一致。错误分析:multipart表单解析错误。
## 2. 在[pom.xml](file://D:\SUM\代码\demo251001\pom.xml)中显式指定插件版本。这个问题是由于Maven无法解析`maven-jar-plugin`插件导致的。如果您在国内,可以在Maven的`settings.xml`中配置阿里云镜像源以提高下载速度。检查您的Maven `settings.xml`文件,确保仓库配置正确,可以访问中央仓库。通常情况下
本文介绍了如何下载和配置Apache Maven 3.6.1版本。主要内容包括:Maven 3.6.1的下载地址(Apache存档网站)、配置国内镜像(使用阿里云镜像加速下载)以及设置本地仓库路径。文章提供了详细的步骤说明和截图指导,解决了官网最低版本为3.8而无法直接下载3.6.1版本的问题,并解释了配置国内镜像的必要性。适用于Windows和Mac系统用户,帮助开发者快速搭建特定版本的Mave
apache seatunnel 2.3.12版本记录
(修改证书及etcd、token文件等配置信息)【token生成方式:(token.csv文件中的token是在主节点上生成的,本部署文档提供token.csv模板,只需替换token.csv文件第一行第一个token串即可。对于 kube-scheduler 是 10251,变成 10259。kublet 启动时查找配置的 --kubeletconfig 文件是否存在,如果不存在则使用 --bo
针对Tomcat出现"org.apache.tomcat.util.net.NioEndpoint"相关的"打开文件过多(Too many open files)"问题,修改系统级配置后需重启Tomcat生效。若问题持续出现,建议结合应用日志和lsof -i:<端口>命令进一步分析具体泄漏源
请注意,在安装和配置DataX和DataX-Web时,需要根据具体情况进行调整,如版本号、文件路径和配置文件内容等。同时,建议参考官方文档或相关资源以获取更详细的安装和使用说明。根据实际情况修改配置文件中的数据库和DataX路径等信息。默认情况下,DataX-Web会在。是你的数据同步任务配置文件。替换为实际的版本号。替换为实际的版本号。
4.若依中验证登录(如果数据库表中存在该用户即可生成token授权登录)3.从前端拿到code值换取Access Token。
處理springboot升級3.5.x導致的org.apache.tomcat.util.http.fileupload.impl.FileCountLimitExceededException: attachmen問題
在调用以下方法的时候,会提示org.apache.commons.io.output.UnsynchronizedByteArrayOutputStream.builder()错误。但在官网的版本提示中。所以需要改为以下版本。
Target(ElementType.FIELD)//该注解作用于字段上@Retention(RetentionPolicy.RUNTIME)//运行时保留,保证在运行时通过反射拿到。
【代码】idea启动项目报错org.apache.commons.exec.ExecuteException: Process exited with an error: 1 (Exit value: 1)
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制
你是否曾在SpringBoot的海洋中迷失方向?面对琳琅满目的starter模块,是否感到无从下手?别担心,今天我们就来一次深度探究,揭开spring-boot-starters的神秘面纱,让你的应用开发之路更加顺畅!
win+s搜env回车打开环境变量,新建一个变量名:JAVA_HOME,值:为你的jdk解压后的目录。如C:\Program Files\Java\jdk-22\bin。在bin文件夹下找到startup.bat和shutdown.bat,右击在记事本中编辑。新建一个:变量名为:CATALINA_HOME,值为:你的apache-tomcat安装目录。第一个是java jdk目录,第二个是解压后的
在配置nginx作为反向代理和负载均衡,同时配置python脚本接收文件上传参数的情况下,可以在nginx.conf文件新增一个server。具体操作和步骤如下。
Apache Doris是一个开源的实时数据分析引擎,专为海量数据的快速查询和分析而设计。它具有极速查询(秒级响应)、实时数据更新、简单易用(标准SQL)和高性价比等特点。典型应用场景包括实时报表、用户行为分析、日志监控和广告数据分析等。相比传统方案,Doris能实现秒级响应的实时查询,支持灵活的多维度分析和高并发访问。美团、京东、字节跳动等互联网公司已广泛应用。适合数据量大、需要实时分析的企业,
基于PHP的论坛系统,通过集成帖子分类管理、论坛信息管理、举报信息管理和贴公告管理等功能,为用户提供了一个高效、便捷的交流环境。该系统不仅允许用户轻松发表观点、参与讨论,还提供了丰富的管理功能,使管理员能够精准地监管论坛内容,维护良好的交流秩序。本文将深入探讨基于PHP的论坛系统的设计与实现过程,包括系统架构的搭建、功能模块的开发、数据库的设计以及关键技术的运用等方面,旨在为读者呈现一个完整、详尽
数据仓库简介,Apache Hive简介
精选集展示了Apache DolphinScheduler在互联网、云计算、智能制造、AI研发等领域的深度应用,通过容器化部署、流批统一调度、数据血缘治理、多系统协同等方案,解决了企业数据调度中的弹性、稳定性与扩展性难题。社区持续推动开源生态创新,为企业构建高可用、智能化的调度平台提供实践指南。完整案例详见各章节链接,或访问Apache DolphinScheduler官网。
对于集群部署,需要配置 `spark-defaults.conf` 或通过 `--master` 参数指定。- 在 spark-submit 中运行: `spark-submit your_script.py`- 例如: `spark-submit --master yarn your_script.py`- 增加 executor 内存: `--executor-memory 4G`- 增加 d
Apache Tomcat作为Java Web应用的核心容器,其分层架构设计通过server.xml配置文件实现精细化管理。配置示例展示了连接器优化、线程池调优、集群部署等关键参数设置,包括HTTP/AJP/HTTPS连接器的性能参数、Session复制机制以及JNDI资源定义。高级特性部分演示了自定义阀门实现访问日志增强、过滤器处理性能监控,以及完整的电商平台部署方案,涵盖负载均衡、静态资源处理
RocketMQ是一款金融级开源消息中间件,由阿里巴巴研发并贡献给Apache基金会。它通过四大核心组件(NameServer、Broker、Producer、Consumer)实现高可靠的消息传递,支持事务消息、顺序消息等高级特性。5.0版本引入Proxy组件实现云原生化架构升级,优化了多语言SDK和流处理能力。相比Kafka和RabbitMQ,RocketMQ在可靠性与性能间取得平衡,适用于电
这篇就当是一次复盘:从“我以为是流式,不会堆内存”到慢慢意识到——你以为的“流”,其实是很多层 buffer 和 batch 堆起来的。
🎉哇塞!《2025 年 Apache SeaTunnel 案例精选集》 闪亮登场啦!免费领取通道开启,限时 7 天,手快有手慢无哦,宝子们冲呀!
过去一年,Apache DolphinScheduler 已深入更多企业生产环境,为复杂任务调度提供解决方案。社区精心整理了应用实践,汇编成《2025 年 Apache DolphinScheduler 案例精选集》,现已 重磅发布,限时 7 天免费领取!
本文系统梳理 Apache DolphinScheduler 3.3.2 各服务(master/worker/api/alert/standalone)目录、JVM、数据源、注册中心、存储、Quartz、环境变量及日志等关键配置项、默认值与作用,为部署调优提供一站式参考。
apache
——apache
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区


 智能体开发者社区
智能体开发者社区

 AI编程社区
AI编程社区







 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区
 DAMO开发者矩阵
DAMO开发者矩阵


 MCP技术社区
MCP技术社区