登录社区云,与社区用户共同成长
邀请您加入社区
环境说明:小车系统 Ubuntu22.04 + Humble,推荐:Windows11 + WSL2(自带 WSLg,直接弹出 Rviz2 图形界面,不用额外 VcXsrv)
Rviz2 不是独立绿色软件,它属于 ROS2 生态组件,强依赖 ROS2 的消息库、DDS 通信层、Qt、ROS2 基础运行时。rviz2.exe。
分布式事务概述
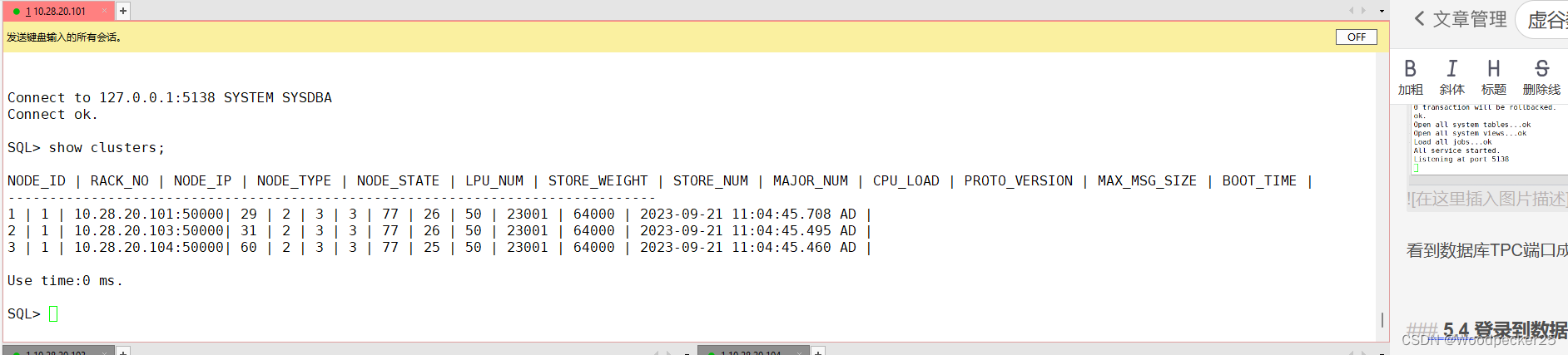
本篇讲述分布式部署安装。单机版的部署我们按Windows和Linux不同的操作系统进行讲述,分布式部署需要多个服务器,所以本篇主要讲述Linux下三节点的虚谷数据库分布式集群部署。
本文深入分析了Spring Cloud Alibaba生态中Seata框架的两种分布式事务模式:AT模式和TCC模式。AT模式通过自动解析SQL生成回滚日志实现事务管理,对业务代码侵入小;TCC模式则基于Try-Confirm-Cancel三阶段设计,提供更灵活的事务控制但需手动实现补偿逻辑。文章详细对比了两种模式的实现原理、适用场景及性能特点,并给出了在Spring Cloud Alibaba项
ROS2(Robot Operating System 2)的核心设计目标之一是支持分布式通信,允许节点(Nodes)在不同设备或进程中运行,通过中间件(DDS)实现高效的数据交换。分布式通信涉及节点发现、消息传递和服务调用等机制。
MinIO 是高性能、开源的分布式对象存储系统,完全兼容 Amazon S3 协议,适合存储图片/视频等非结构化数据。:分布式部署需确保所有节点时间同步(
win10+python3.7.3安装ray库pip install -i https://mirrors.aliyun.com/pypi/simple/pytest-runnerpip install -i https://mirrors.aliyun.com/pypi/simple/ray使用ray库计算100次的延迟1秒import rayimport timeimport numpy as
在全球化和技术革命的双重推动下,企业正面临前所未有的市场竞争和运营压力。为了适应这种变化,企业纷纷开始了的进程,希望借助技术力量提升效率、推动创新并保持竞争优势。尽管数字化转型的趋势已不可逆,但如何真正落地实施、如何确保从业务到技术的深度融合、以及如何规避转型过程中的风险,依然是许多企业的核心难题。《世界级企业架构》白皮书为企业提供了(Enterprise Architecture, EA)的框架
冀北地区作为国家可再生能源示范区,分布式光伏装机容量已突破1100万千瓦,占统调装机容量的72.3%。为应对大规模分布式电源接入带来的电网波动性问题,“四可”装置(可观、可测、可调、可控)成为关键技术支撑。
本文主要记录如何在ubuntu当中安装配置hadoop的单机模式,具体分为安装jdk、shh、hadoop和运行hadoop五个步骤。
1.背景介绍在分布式系统中,数据库分布式是一个重要的技术领域。分布式事务和分布式锁是数据库分布式中的两个核心概念,它们在分布式系统中起着至关重要的作用。本文将深入探讨这两个概念,揭示它们之间的联系,并提供具体的最佳实践和实际应用场景。1. 背景介绍分布式系统是一种由多个独立的计算机节点组成的系统,这些节点通过网络相互连接,共同完成某个任务。在分布式系统中,数据库分布式是一个重要的技术领...
redis lua实现分布式锁
文章目录背景技术JMeter分布式运行原理
当提到文件系统,大部分人都很陌生。但我们每个人几乎每天都会使用到文件系统,比如大家打开 Windows、macOS 或者 Linux,不管是用资源管理器还是 Finder,都是在和文件系统打交道。如果大家有自己动手装过操作系统的话,第一次安装的时候一定会有一个步骤就是要格式化磁盘,格式化的时候就需要选择磁盘需要用哪个文件系统。维基百科上的关于文件系统的定义是:简而言之,文件系统管理的是某种物理存储
文章摘要: 公司订单系统因全局锁设计不当,导致核心接口性能急剧下降,TPS从8,000暴跌至200,响应时间激增至8秒。问题根源在于订单处理流程被全局锁包裹,锁持有时间过长,引发Redis CPU占用率100%、数据库连接池耗尽等问题。通过分析事故原因,提出四大优化准则:锁粒度拆分、异步处理解耦、缓存优化策略和防御性编程。优化后,系统QPS提升至7,500,响应时间降至210ms,Redis CP
今天看到了一篇关于分布式事务我们是否真的需要的文章,记录一下,欢迎讨论原文链接在这里分布式事务–我们是否真的需要我们不断的拆分schema,说了为了下一步的分库做准备,但是由此带来的代价也是显而易见的,我们的分布式事务在不断的增多。我们期望利用分布式事务来保证数据的一致性,但是其带来的影响也是不容忽视的。摘录他人语分布式事务提供的ACID保证是以损害系统的可用性、性能与可伸缩性为代价的。只有在参与
能不能设计这样一个方案:在获取锁时,先设置一个过期时间,然后启动一个“守护线程”,定期检查锁的剩余时间。关键点在于,每个客户端在释放锁时,执行的是“盲目”操作,没有检查锁是否仍然“归自己所有”。简而言之,由于这两条命令不是原子的(不能保证一起成功),存在过期时间设置失败的风险,从而导致同样的死锁问题。例如,该操作“最慢”可能需要 15 秒,但我们只设置了 10 秒的过期时间,这就造成了锁过早过期的
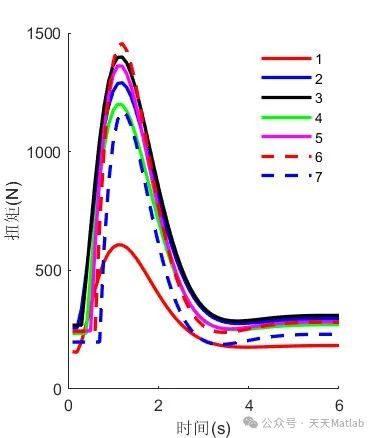
近年来,随着自动驾驶技术的发展,多车辆协同控制成为了研究热点。其中,异构车辆的协同控制由于其复杂性更具挑战。本文针对单向拓扑结构下异构车辆的控制问题,提出了一种基于分布式模型预测控制(DMPC)的方法。该方法将每个车辆的控制问题分解为局部优化问题,并通过信息传递机制实现车辆之间的协调。通过仿真验证了该方法能够有效地控制异构车辆,并能够适应不同的交通状况和车辆特性。关键词: 分布式模型预测控制,异构
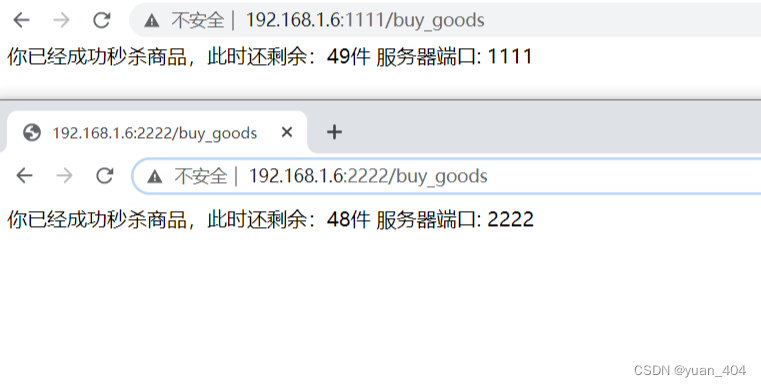
在多节点的分布式系统中,控制多个客户端对共享资源的访问,确保同一时刻只有1个客户端能操作资源,避免数据错乱。• 比如库存只剩1件,2个线程同时查到“库存≥1”,都去扣减,最后库存变成-1,超卖了!• 核心:用“租约(Lease)”和“原子事务”实现,锁绑定租约,租约到期自动释放;:尽量缩小锁的范围(比如只锁库存扣减,不锁整个订单流程),能不用锁就用乐观锁;:分布式锁没有“银弹”,重点是平衡一致性、
Eureka 的作用Eureka 是 Netflix 开源的服务发现框架,是 Spring Cloud 体系中的核心组件之一。Eureka Server 充当服务注册中心,服务实例向其注册自己的信息,并定期发送心跳以表明存活状态。默认下线判断机制默认情况下,Eureka Server 根据服务实例发送心跳的频率来判断服务是否存活。如果服务实例在一定时间内没有发送心跳,Eureka Server 会
本文将讲述把tracker和storage部署到不同的机器上搭建环境:Linux系统:Centos 8.0.64搭建tracker的ip:公网ip:119.45.114.65 内网ip:10.206.0.4搭建storage的ip:公网ip:118.195.129.27 内网ip:10.206.0.11步骤一 安装fastdfs参考单机版安装FastDFS文件服务器安装搭建(Linux
目标:一行代码调用,简单粗暴。基操:自动加锁,自动解锁,自动处理异常,自动处理锁超时等。
在文章正式开始之前,我分享下我以前负责过的一个系统,它的架构如下:每次当我查问题的时候,我都能把问题初步定位在,但为了能给业务方交代,我需要业务方面(日志信息就是铁证)。一个请求肯定是被这8台机器内的某一台处理,但具体是哪一台,我不知道。所以,我需要上每台机器上 grep 一把日志,然后才能找出对应的日志证明我的分析。有的时候,可能也需要一起参与进去,就排查一个问题,人都傻了了(翻看日志的时间占用
矿用本安型GUD960行程传感器又称GUD960液压支架位置感应开关,行程传感器GUD960采用干簧管技术,将液压支架推移油缸的机械行程转化为电流信号,是完成推溜、拉架、拉溜等功能的保证。是一种允许在瓦斯、煤尘爆炸危险环境中使用的本安型距离检测蒂娜子设备,它是推移千斤顶活塞杆移动行程的检测单元,安装在液压支架推移液压缸中,反映支架或推动杆所处的位置,是控制过程的重要参数来源,推移千斤顶活塞杆位置决
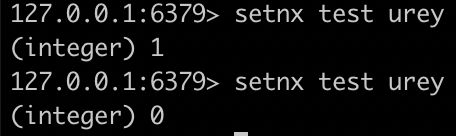
synchronized 锁:单机版 OK,上 nginx分布式微服务,单机锁就不 OK,分布式锁:取消单机锁,上 redis 分布式锁 SETNX如果出异常的话,可能无法释放锁, 必须要在 finally 代码块中释放锁如果宕机了,部署了微服务代码层面根本没有走到 finally 这块,也没办法保证解锁,因此需要有设置锁的过期时间除了增加过期时间之外,还必须要 SETNX 操作和设置过期时间的操
自己的项目因为会一直抓取某些信息,但是本地会和线上经常一起跑,造成冲突。这其实就是我们常说的分布式集群的问题了,本地和线上的服务器构成了集群以及QPS为2的小并发(其实也不叫并发,不知道拿什么词形容?)。首先,分布式集群的问题大家都知道,会造成数据库的插入重复问题,会造成一系列的并发性问题。解决的方式呢也大概如下几点,百度以及谷歌上都能搜到的解决方式:数据库添加唯一索引设计接口幂等性依靠中间件使用
elk环境搭建filebeat程序安装filebeat配置修改filebeat.yml修改如下:# 监控日志文件地址paths:- d:/_tmp/log/*.log# 对于行不是以日期开头,都归到上一行multiline.pattern: ^\d{4}([-]\d{2}){2}\s\d{2}([:]\d{2}){2}[.]\d{3}multiline.negate: truem
一:什么是事务?1.1)什么是事物?事务是逻辑上的一组执行单元,要么都执行,要么都不执行.eg: 张三给李四转1000元钱, 涉及到二个操作张三的账户-1000 李四的账户+1000上诉二个步骤要么一起成功,要么一起失败. 不存在张三的钱扣了,李四没收到转账.1.2)事物的特性(ACID)什么是ACIDACID是指数据库管理系统DBMS中事物所...
Seata 通过灵活的事务模型,为分布式系统提供了高可用的事务保障。无论是追求快速上线的初创项目,还是对一致性要求严苛的金融系统,Seata 都能找到合适的解决方案。在微服务架构中,订单支付需调用支付服务、库存服务和积分服务,若其中一个服务失败,如何保证数据的一致性?传统的单体事务(ACID)无法跨越服务边界,而分布式事务的复杂性让许多开发者望而生畏。:整合 Kafka 事务消息,实现跨系统事务。
另一种常见的方法是通过自定义 HTTP 头来传递跟踪信息。当请求进入 Nginx 时,我们可以从客户端传来的 HTTP 头中获取跟踪 ID 等信息,如果不存在,则生成一个新的跟踪 ID 并添加到后续的请求头中,以便后端服务能够获取到。以下是一个通过end在这个示例中,如果客户端没有传递X-Trace-ID头,我们会生成一个新的跟踪 ID 并添加到请求头中。通过以上的探讨,我们了解到在 Nginx
分布式事务解决方案之可靠消息最终一致性什么是可靠消息最终一致性事务可靠消息最终一致性方案是指当事务发起方执行完成本地事务后并发出一条消息,事务参与方(消息消费者)一定能 够接收消息并处理事务成功,此方案强调的是只要消息发给事务参与方最终事务要达到一致。 此方案是利用消息中间件完成,如下图: 事务发起方(消息生产方)将消息发给消息中间件,事务参与方从消息中间件接收消息,事务发起方和消息中间件 之间,
具体逻辑就算请求进来之后先从redis中拿ip,如果redis中没有ip则去执行一个添加ip的操作,看上去这个操作没什么问题,但是并发高的时候会有很多请求都去执行这个操作,这个时候就需要用到分布式锁了,只有加锁成功的请求才去执行这个操作,其他请求可以等待或者先返回一个错误码,上代码。最近有一个python实现代理池的项目,其中获取代理这个地方需要用到分布式锁,
随着无人机技术的不断发展和应用,无人机编队协同作业成为了无人机领域的一个热门研究方向。无人机编队协同作业可以提高作业效率、降低成本,并且可以应用于军事侦察、灾难救援、农业植保等多个领域。因此,如何实现无人机编队协同作业成为了无人机领域的一个重要问题。本文将讨论基于领航者的分布式编队控制算法实现三无人机编队协同作业的问题。首先,我们将介绍无人机编队协同作业的背景和意义,然后将详细介绍基于领航者的分布
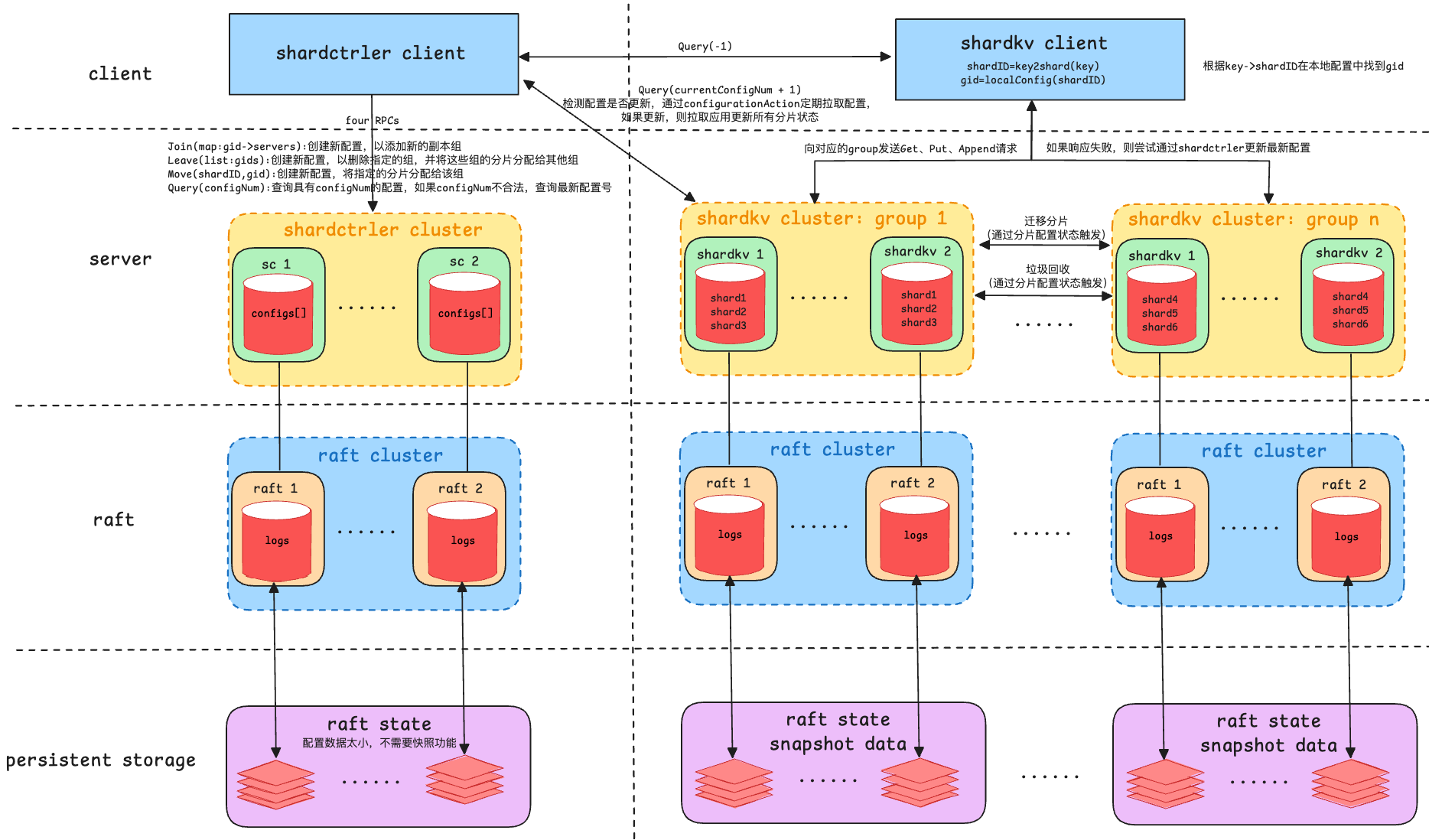
本实验要求构建一个键 / 值存储系统,该系统能够将键 “分片” 或分区到一组副本组上。分片是键 / 值对的子集,例如所有以“a”开头的键可能是一个分片等,通过分片可提高系统性能,因为每个副本组仅处理几个分片的放置和获取,并且这些组并行操作。系统有两个主要组件:一组副本组和分片控制器。每个副本组使用 Raft 复制负责部分分片的操作,分片控制器决定每个分片应由哪个副本组服务,其配置会随时间变化。客户
分布式
——分布式
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵

 深开鸿 技术专区
深开鸿 技术专区