- @datian1234
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
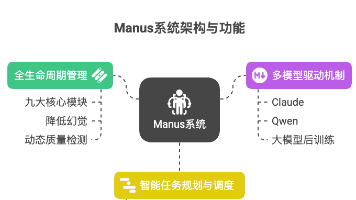
在人工智能和大模型技术飞速发展的今天,Agentic AI(智能体AI) 正成为产业界和开发者关注的焦点。而在这股浪潮中,Manus 作为一个备受瞩目的大模型智能体产品,以其卓越的性能和使用体验脱颖而出。那么,Manus究竟拥有哪些核心技术,使其能够迅速成为全球热点?今天,我们就来深度剖析Manus背后的技术奥秘。
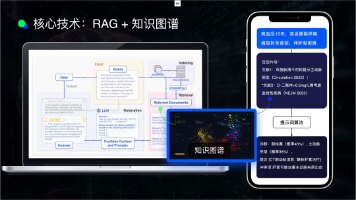
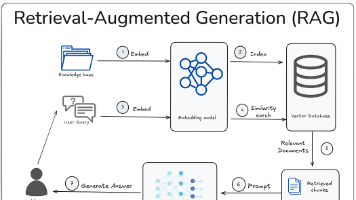
文章详细解析了大模型核心技术Langchain、向量化与RAG的区别与应用。通过RAG技术链路(采集/清洗→切分→向量化→建索引→召回→重排→拼上下文→生成→评测)和咖啡豆案例,展示了知识检索系统的构建过程。文章探讨了向量检索的局限性,提出"向量路由+结构化知识库"的混合架构,解决了"语义相似≠答案相关"的问题,为构建高效智能问答系统提供了新思路。
本文详细剖析了RAG系统中22种分块策略,从基础(按换行符、定长、滑动窗口)到高级(基于文档层级、关键词、实体、主题等)方法。作者强调分块是决定RAG系统成败的关键因素,不同数据类型和场景需采用不同策略,旨在帮助AI工程师解决检索增强生成中的痛点,提升系统准确性和回答质量,避免模型"幻觉"问题。
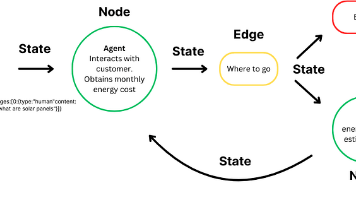
本文介绍如何使用 LangGraph 构建高级 AI 智能体,通过太阳能板节能计算示例展示完整实现。LangGraph 支持循环计算、状态管理和多步任务执行,核心包括状态、节点和边三大概念。文章详细展示了从环境配置到工作流定义的全过程,帮助开发者创建智能、可适应的 AI 系统。
本文系统介绍了Prompt工程作为AI产品经理的核心竞争力,详细讲解了Prompt的基本概念(系统提示词与用户提示词)、核心技巧(参考资料、样例、指令的使用)及不同方法(Zero-Shot、One-Shot、Few-Shot),强调了上下文窗口的重要性,提供了Coze平台实操方法,讨论了模型选型和效果评估,并给出了从模仿开始的实战建议,帮助读者掌握与大模型交互的关键技能。
本文详细介绍了LangGraph框架的使用方法,从基础概念(State、Node、Edge)开始,逐步引导读者构建简单的线性工作流,再到实现具备决策能力的智能Agent。文章提供了两种构建Agent的方法:使用create_react_agent简化流程和手动构建以获得完全控制权。通过完整的代码示例和实践指导,读者能够掌握构建复杂、有状态、可控的AI应用的核心技能。
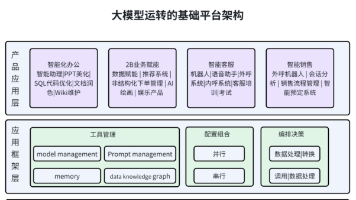
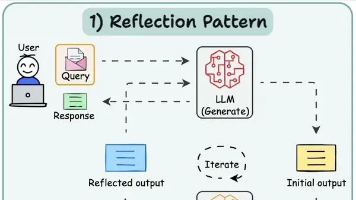
本文全面综述了AI智能体的分类体系、开发模式、产品形态与功能模块,以及生产落地中的挑战与解决方案。详细探讨了反思模式、工具模式、ReAct模式、Planning模式和Multi-Agent模式等不同开发模式的特点与应用场景,并针对私域知识注入、可信规划、推理可解析性等关键挑战提出了包括RAG、思维链提示、反思与自我批判等解决思路,为AI Agent的工程实践提供了系统性的指导。
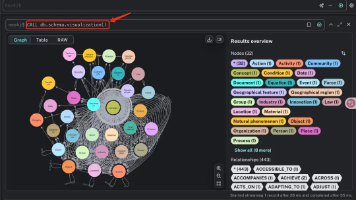
本文详细介绍了使用LangChain和Neo4j构建图RAG管道的完整流程,包括从PDF文件提取文本、构建知识图谱、优化检索设置以及使用QAEvalChain评估系统准确性。通过滑雪领域的真实案例,演示了图文档生成、Cypher查询优化和答案评估的全过程,为开发者提供了实用的图RAG应用构建指南。
文章提出AI产品经理应回归产品本质,避免陷入技术迷雾。首先,产品核心是解决用户问题而非展示技术先进性;其次,需从"工程师思维"转向"农夫思维",拥抱AI的不确定性;最后,必须关注成本与价值平衡,经得起ROI拷问。优秀的AI产品经理应是用户问题和商业价值的专家,而非技术本身。

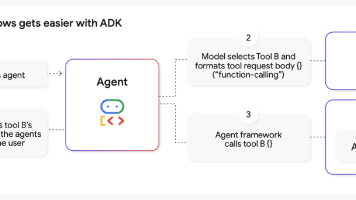
谷歌《Startup Technical Guide: AI Agents》白皮书提供完整AI Agent技术路线图,涵盖ADK开发框架、三层数据架构、ReAct编排模式及AgentOps评估体系。文章详解从原型到生产的部署策略,通过多行业案例展示AI Agent在客户服务、内容管理等领域的价值,为开发者提供企业级AI Agent构建的完整技术栈和最佳实践。