- @2401_85327249
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近我和一个律师亲戚聊AI时,问了我应该怎么对现在律师事务所庞大的文档做AI检索,从技术上讲用现在的LLM+RAG可以满足需求,但细想不太对劲,因为这里面涉及到很多专业知识,还有律师的专有思维路径,一个不懂律师业务的程序员肯定是做不好的,于是有幸跟他们合伙人进行了深入沟通,合伙人说了一堆但我总结下来就这么一句话
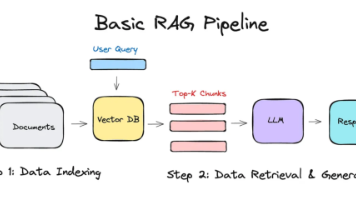
本文探讨了GraphRAG(检索增强生成)技术的实现方法,指出开发者在构建GraphRAG系统时往往过度依赖复杂的图数据库、查询语言和分析工具。作者强调,生成式AI的用例与传统图分析场景根本不同,大多数GraphRAG应用只需要进行局部邻域探索,而不需要复杂的全图分析。文章建议采用以向量存储为核心、按需添加图功能的简化架构,避免不必要的技术复杂性。
近一年来,开源大模型快速演进,个人用户也能搭建属于自己的本地问答系统(RAG)。工具五花八门,每一个都声称一键部署,但你点进去后,往往看到一堆让人头大的名词:Qwen1.5-7B-Q4_K_M-GGUF?bge-m3-int4-awq?reranker?embedding?gguf?fp8??别急,这篇文章不讲操作步骤,只做一件事,通俗解释这些你即将遇到的关键术语。理解它们,是你真正开始纯本地RA
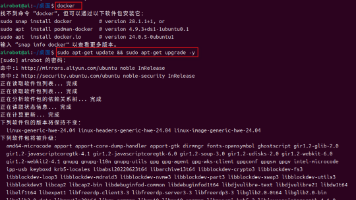
文主要介绍如何在Ubuntu操作系统环境下,零基础快速安装Docker环境、安装Ollama、安装本地大模型DeepSeek-R1和大模型可视化工具Open WebUI,快速在本地搭建一款专属AI智能小助手。
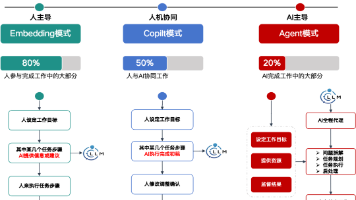
AI Agent的任务规划能力的突破,我向来认为这是决定Agent是否真的能从原有技术体系跳出,被定义为跨代变革的里程碑。不像现如今的各种散落的单点升级,它是能把业务能力串起来,实现业务流重组的存在。业务的构成、运行机制,如果没有发生变革,其实都是补丁式的更新。至少在我看来,是这样的。这有意义,但也仅限于此了,并不有趣。
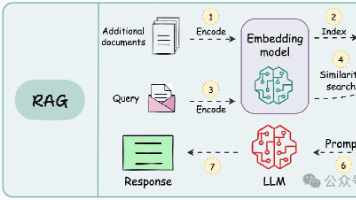
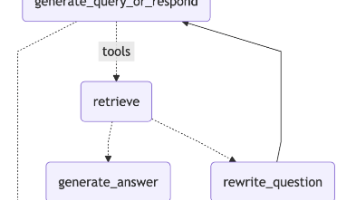
在本篇文章中,我们将通过LangGrah构建一个检索代理。我们让大语言模型(LLM)能够自主决定是从向量库中检索上下文,还是直接响应用户。大概的流程是:获取并预处理用于检索的文档;对这些文档进行语义搜索索引,并为代理创建一个检索工具;构建一个具备代理能力的RAG系统,使其能够自主决定何时使用检索工具。
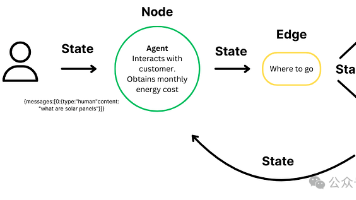
在 AI 世界中,检索增强生成(RAG)系统已广泛用于处理简单查询,生成上下文相关回答。但随着 AI 应用复杂度不断提升,我们迫切需要一种能执行多步推理、保持状态和具备动态决策能力的智能体系统。
AI Agent-人工智能代理,是人工智能领域中的一个重要的概念,学会理解并使用它,是学习大模型应用开发的必经之路。本篇我将用通俗易懂的方式为各位同学介绍一下AI Agent,目的是让大家轻松上手AI Agent,打开一扇大语言模型进阶之门。
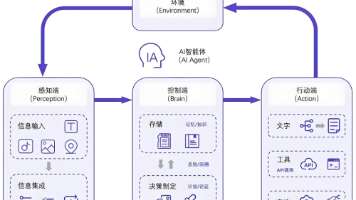
本文介绍了基于LangChain框架的AI Agent开发实践,对比了SequentialChain和Agent两种实现方式。SequentialChain采用固定顺序执行,适合确定性任务;而Agent通过ReAct模式实现动态决策,能处理复杂问题。文章通过高考信息查询案例,展示了如何使用LangChain的顺序链执行固定流程,以及如何利用Agent进行问题拆解和多表查询汇总,帮助开发者根据实际场
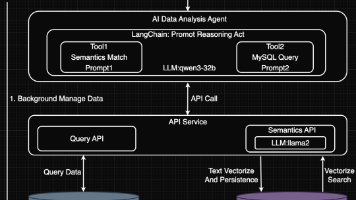
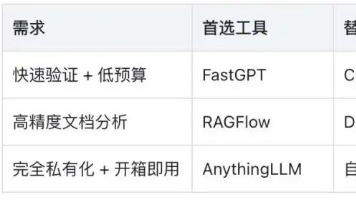
AnythingLLM:桌面版开箱即用,但本地模型需RTX 3060+GPU,混合模式依赖API稳定性(如DeepSeek R1宕机时体验下滑)。RAGFlow:Docker启动需调整系统参数(如vm.max_map_count),16GB内存门槛高,但企业级文档处理效果突出。