




- @2401_82469710
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近看了很多的 Agent 项目, 如果想要自己开发发现还是 Langchain 框架最适合我这样的小白。记录一下今天跑的一个 Demo
分享一些适合大语言模型入门同学的开源课程,对转行或者新入门的同学非常友好(个人感受)。
本文将全面梳理LLM及其生态的最新趋势、关键技术、典型实践项目和行业应用,为技术人员和关注AI、编程、产品与商业创新的读者,提供一份权威、系统的实战参考。

本文手把手教你利用Dify平台和阿里通义千问多模态大模型,快速构建一个智能发票识别Agent。零代码基础也能上手,提升工作效率10倍以上!从注册到部署,全流程详解。快来解锁你的AI生产力吧!
手把手教你用当下最火的 LangChain 框架,构建一个能思考、会决策、还能使用工具的 AI Agent。从入门到实战,一篇文章让你彻底搞懂!
传统测试效率低、覆盖不全、成本高昂?本文通过我们团队构建的智能测试工作流,展示4个专门AI Agent如何协作:从自动生成测试用例到智能执行监控,从结果分析到报告生成。6个月实践数据显示:测试效率提升73%,缺陷发现率提升85%,测试成本降低45%。
📈 15分钟构建AI工作流:LangGraph+Dagre自动排版全解,大模型入门到精通,收藏这篇就足够了!
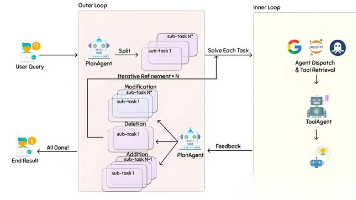
还在惊叹大模型?不如用LangChain+DeepSeek亲手打造更强大的AI应用!本文从核心概念、使用方法、竞品对比到快速上手,附带简易版RAG,一文讲透,小白也能看懂。
如何用 AI 智能体开启副业之路?零基础入门指南,大模型入门到精通,收藏这篇就足够了!
n8n 早在 2020 年左右就被程序员玩过一波,当时很多人拿它做网站自动发邮件、消息转发之类的“流程自动化”。但那时候 AI 还没这么卷,大家也没觉得多有用。
