登录社区云,与社区用户共同成长
邀请您加入社区
Affinage 示范了领域专家(生物学家)如何将自身对数据质量的严苛要求(如“只认直接实验,不认表达相关性”)转化为可扩展的 AI 生产力。它不仅提供了一个超越 UniProt 的全基因组动态知识库,更确立了 AI Agent 时代预构建结构化数据图谱的优秀范式。谁应该继续阅读原论文:从事 Bio-AI、LLM RAG 设计、数据标注自动化,以及关注特定未解基因机制的生物医学研究者。谁只看导读即
本文摘要集包含三篇论文的研究成果:1)金属表面缺陷自适应分割算法,通过多方向灰度波动分析等方法实现高精度分割,但存在处理时间长和细节丢失问题;2)改进变换网络的域自适应语义分割网络,利用虚拟图替代真实数据降低标注成本,提出分阶段训练策略和MaskNet;3)基于时空域自适应高阶有限差分的声波叠前逆时偏移方法,相比传统有限差分法具有更高精度和稳定性,频散更小。三篇论文分别针对工业检测、计算机视觉和地
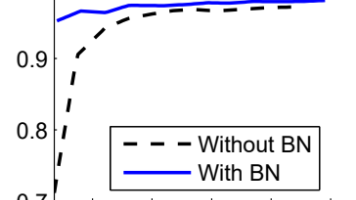
通俗来说:网络训练时,前面层的参数会不断更新,导致后面层的输入分布一直在变。后面的层就像一个学生,老师每天都换不同难度的教材,学生永远跟不上进度,学习效率自然极低。第一层网络是语文老师,第一次考试出的题很难,全班平均分50分第二层网络是数学老师,根据50分的平均分调整了自己的教学计划结果第二次语文老师出的题很简单,全班平均分90分数学老师的教学计划完全失效,只能重新调整这样循环下去,网络永远在"追
本文提出一种研究生快速发表论文的方法,采用"模块缝合+故事包装"策略。首先进行1个月基础准备,包括学习深度学习和数据集处理;然后选择近2-3年性能适中的baseline模型;接着从不同论文中提取模块进行组合改进,并编造涨点解释;最后用LaTeX撰写论文。该方法强调无需超越sota,通过合理选择对比模型和模块组合即可完成论文发表,适合时间紧迫且创新性要求不高的场景。
本文集聚焦于领域自适应算法的最新研究进展,涵盖多个应用场景。主要内容包括:基于梯度权值追踪的剪枝算法解决无监督领域自适应中的过拟合问题;掩蔽图像一致性算法提升目标识别性能;元模型优化方法改进运输托盘设计;深度学习在医学图像分析中的域自适应应用;以及融合类重平衡策略的睡眠分期算法提高分类准确率。这些研究通过创新算法设计,在各自领域取得了显著效果,准确率提升最高达13.27%,展示了领域自适应技术的广
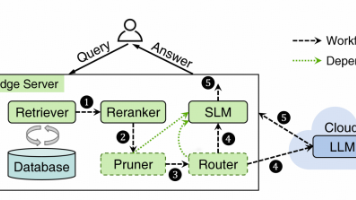
该研究针对边缘计算环境下大模型部署的痛点,提出了一种全新的云边协同 RAG 框架,在提升回答质量的同时,显著降低云端 API 调用成本,并保持较低平均延迟。此次合作论文入选 ICDE 2026,不仅证明了平凯星辰在 AI 与数据库交叉领域的科研深度,也为 RAG 技术在工业界的高效落地提供了新的范式。未来,平凯星辰将继续深化与高校的产学研合作,推动云边协同技术在分布式数据库及 AI 基础架构中的应
这与简单 early fusion、middle fusion 或单一参考模态校正有明显差异。
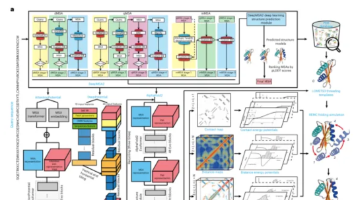
《Nature Biotechnology》最新研究提出混合蛋白质结构预测方法D-I-TASSER,结合深度学习与物理模拟,显著提升预测精度。该方法在单/多结构域蛋白质预测中均优于AlphaFold系列,CASP15盲测表现突出,尤其对复杂多结构域蛋白提升显著。成功预测81%人类蛋白质结构域,与AlphaFold2结果高度互补。研究证明深度学习与物理模拟融合的策略可突破现有技术瓶颈,为结构生物学难
3.未来的科研规划一般老师都会要求写一份研究生阶段的规划安排,如果没有要求也可以提前想一想,因为导师很可能会在组会上cue 到一另外可以思考一下自己想做的研究方向,这也是第一次组会老师常问的问题加分小tip: 第一次出场穿“好学生装”化伪素颜妆现场带纸笔,老师点评时记录要点?第一次开组会见导师和师兄师姐,自我介绍是少不了的,简要介绍一下自己的本科院校、专业以及做过的研究,说说自己的家乡、兴趣爱好等
Seedream 3.0 Technical Report:一篇读懂字节 Seedream 3.0 的图像生成系统升级
Seedream 2.0:一篇读懂中文图像生成模型的真正主线
DALL·E 2 的真正转折:一篇读懂 CLIP Latents 如何重写文本生成图像
摘要:近期AI领域多项突破性研究聚焦大模型架构优化与安全风险。
本文基于公开小数据集 `SMS Spam Collection`,复现无源码论文的深度学习实验流程,完成了数据处理、`CNN/LSTM/GRU` 模型训练、多随机种子结果对比及图表整理,适合作为论文复现、课程作业和科研入门的参考资料。
本文基于 UCI HAR Dataset 复现一篇无官方源码的人体行为识别论文,完成了数据接入、CNN baseline 与 ConvBLSTM-PMwA 实现,并补充了多随机种子结果。过程中也解决了小文件 I/O 和 torch 共享内存限制等工程问题,适合作为时序深度学习论文复现参考。
5️⃣讨论(Discussion):阅读讨论部分以了解作者对研究结果的解释、发现的意义以及可能的局限性。9️⃣批判性思考:不仅仅接受论文的观点和结论,还要思考其方法的合理性、实验设计的完备性以及数据的可信度。3️⃣方法(Methodology):详细阅读方法部分,了解作者采用了哪些方法来解决研究问题,以及实验的设计和执行。6️⃣结论(Conclusion):结论部分会对研究的主要结果进行总结,并强
摘要 这篇阅读笔记聚焦于Jiang等人2026年发表在《Energy Advances》上的综述论文,系统梳理了电池组热失控传播(TRP)从机理到设计优化的全链条研究。文章指出当前研究存在从单体热失控向系统级传播研究的认知缺口,强调了TRP作为"多米诺效应"的工程危险性。综述采用机理→建模→缓解→优化的递进结构,核心观点包括:TRP不能从单体行为线性外推;建模需权衡精度与效率;防护需多层次协同设计
相信不少科研人都有过这样的经历:对着下载文件夹里几十篇文献,明明每篇都扫过几眼,真要动笔写综述时,却不知道怎么把这些零散的内容按主题归类,更别说梳理出领域研究的演进脉络,搭建起严谨的论证逻辑。熬夜整理半天,要么是内容杂乱无章,要么是漏掉关键研究,进度始终卡在第一步,文献越多,焦虑感越强。对于被文献梳理难题卡住的科研人来说,借助智能工具能让我们从繁琐的整理工作中解脱出来,把更多精力投入到真正的研究思
策略梯度基础:RL 的目标是最大化期望回报JθmaxθEπθ∑t0TrtJθmaxθEπθ∑t0Trt。根据策略梯度定理,这可以通过估计梯度∇θJθEπθ∇θlogπθat∣stAπθstat∇θJθEπθ∇θlogπθat∣stAπθstat)]来实现。优势函数。
本文对基于深度学习的命名实体识别(NER)进行学习,撰写学习报告(代码结构、模型结构等),并设计一个实际场景调用,记录自己的理解与体会。
本文是对Yao & Kowal(2025)SOC综述的系统性阅读笔记。论文以深度学习架构为主线,梳理了从LSTM/GRU到CNN/TCN再到混合模型的技术谱系,分析了各架构在SOC估计中的适用场景与局限。笔记还整理了公开数据集、优化策略(迁移学习、注意力机制)以及PINN、多任务学习等前沿方向,并结合BMS工程约束,提出了三层SOC估计工程路径。最后将SOC、SOH、TR三篇综述关联,构建了BMS
本次作业学习的是基于深度学习的 NRE 模型。NRE 的全称是 Neural Relation Extraction,即神经关系抽取。关系抽取是自然语言处理中的一个重要任务,它的目标是从普通文本中识别两个实体之间的语义关系,并将非结构化文本转化为结构化知识。
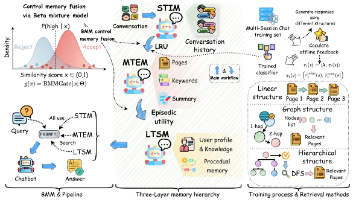
前面已经阅读了 Mem0、A-MEM、MemoryOS、LightMem、Zep 等不同类型的 Agent 记忆系统。Mem0 将对话提取为事实,并管理事实的增加、更新和删除;A-MEM 将记忆组织为相互关联的笔记网络;Zep 使用带有时间信息的知识图谱;MemoryOS 使用类似操作系统的分层存储与淘汰机制;LightMem 更关注长期记忆的成本和效率。它们都在尝试解决同一个问题:如何让 Age
在机器学习领域,论文阅读是研究者获取前沿知识的核心途径。随着arXiv每日新增论文超过200篇,传统线性阅读方式已无法应对信息爆炸。高效的论文阅读方法基于认知科学原理,通过问题驱动和选择性聚焦等技术,将阅读效率提升3-5倍。关键策略包括建立个人知识管理系统、使用结构化略读技巧和主动输出机制。这些方法特别适合处理数学密集型论文,并能有效提升信息留存率。对于机器学习从业者和研究者而言,掌握这些技巧可以
李沐的深度学习论文精读GitHub仓库"paper-reading"(3.3万Star)系统整理了67篇核心论文,覆盖CNN、Transformer、生成模型等10余个方向,配套32个精讲视频。该资源以计算机视觉为重点,按时间线梳理了AlexNet到Sora等里程碑工作,同时包含NLP和分布式训练等关键技术。特色在于体系化分类、实战化讲解(结合代码/直觉而非纯公式),适合深度学习学习者系统补课。目
法律与合规稀疏注意力分层处理。
NotebookLM(现已更名为Gemini Notebook)和知芽,虽然都做“基于个人文档的AI问答”,但产品逻辑完全不同:NotebookLM:Google出品的轻量级AI笔记工具。免费、多模态输入、与Google生态整合好。但国内无法直连,中文支持薄弱,产出止于摘要和简报。知芽:国产AI知识管理与创作工具。国内直连、全中文优化、支持知网题录导入和B站视频转录。引用可信度极高,能产出带GB/
摘要: 随着生成式AI和大型语言模型的快速发展,AI辅助编程正深刻改变软件开发模式。本文系统研究了AI辅助编程在企业中的应用,涵盖工具选型、安全治理、组织变革及落地实践。通过分析国内外20余款主流工具(如GitHub Copilot、Cursor、通义灵码等),提出企业评价体系(EACEM),并探讨数据安全、国产化替代及伦理治理等关键问题。研究表明,AI不会完全替代程序员,而是推动“人机协同”模式
本文总结了2026年ICML会议上关于图神经网络与大语言模型(LLM)结合的相关研究,聚焦图基础模型、多模态属性图、知识图谱问答等方向。收录了33篇论文,涵盖图对齐、提示学习、结构学习等关键技术,展示了图神经网络在不同数据模态和实际任务中的应用进展。部分工作提出了创新性方法,如双向对齐的潜在图扩散模型、多模态图基础模型的分治策略等,为图学习领域提供了新的理论框架和实用工具。
ROPE本身是给 q k 矩阵注入了绝对位置信息,用文本的q去查询每个vision token的 k,那么最后得出的注意力本身其实是不仅是文本对于vision token的注意力,还会掺杂着一些位置信息(这个我之前看过有大佬在写数学公式推导,但是的确没看太明白),所以把ROPE去掉,那么存在的就是文本引导下的注意力分布,规避了位置的影响。计算相同位置相邻帧的差值,给差值(可以理解成变化率)进行排序
系列包是NVIDIA GPU CUDA 专用包,仅提供 Windows/Linux x86 平台版本,Mac ARM (M1/M2/M3) 芯片无对应安装包,所以 pip 找不到该版本。原因:CUDA 仅 NVIDIA Windows/Linux,macOS 不支持,安装直接失败。使用 Python3.11 在当前目录创建虚拟环境。
通过使用临床级别的PRKAB1激动剂,研究在多个临床前模型中成功重启了肠道谱系程序,瓦解了由Wnt/YAP驱动的干性,并选择性清除了CDX2低表达的癌症干细胞。研究发现,PRKAB1激动剂能够恢复CDX2表达,触发分化程序,选择性清除CDX2低表达的肿瘤干细胞,并在多种临床前模型中验证了其疗效。PRKAB1敲低后,PF的疗效完全丧失,证实了其靶点特异性。:PF治疗在CDX2低表达模型中一致性地恢复
之所以选择做ribosome profiling的数据,有三个理由:一是身边有人做过这个技术,合作者中的张静博士是这方面的专家,我从她处了解到很多实验上的流程和数据处理的基本知识。我做的题目是测序数据的标准化问题,也承接了我上一个课题,即合成生物学的标准化问题。具体的测序数据来自于核糖体印记技术(ribosome profiling),说的细节一点,该技术是对核糖体保护的mRNA片段进行深度测序,
论文阅读
——论文阅读
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 AI编程社区
AI编程社区









 AI Agent技术社区
AI Agent技术社区





 openEuler 社区
openEuler 社区

 DeepSeek技术社区
DeepSeek技术社区


 AtomGit AI 社区
AtomGit AI 社区





