




- @2401_85328934
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
提到AI应用工程师,很多人会误以为是“专搞模型训练的算法专家”,其实不然。简单来说,他们是将AI技术从“实验室”推向“实际场景”的核心角色,像一座桥梁,连接起前沿的AI模型与企业的真实需求。
AI Agent正成为科技界新风口,OpenAI创始人、比尔·盖茨等大佬纷纷预言其将颠覆人机交互和软件行业。黄佳新书《大模型应用开发 动手做AI Agent》系统讲解了Agent的四大特性(自主性、适应性、交互性、功能性)和四大组件(感知器、知识库、决策引擎、执行器),结合儒家思想提出"博学-审问-慎思-明辨-笃行"的方法论。全书通过7个实战项目(如自动化办公、智能调度等),手
Github项目上有一个[大语言模型学习路线笔记],它全面涵盖了大语言模型的所需的基础知识学习,LLM前沿算法和架构,以及如何将大语言模型进行工程化实践。这份资料是初学者或有一定基础的开发/算法人员入门活深入大型语言模型学习的优秀参考。这份资料重点介绍了我们应该掌握哪些核心知识,并推荐了一系列优质的学习视频和博客,旨在帮助大家系统性地掌握大型语言模型的相关技术。

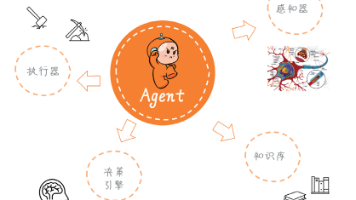
AI智能体是由模型、工具和编排层构成的智能系统,具备自主感知、决策和执行能力。与传统AI助手(如DeepSeek)仅提供简单建议不同,智能体能完成多步骤复杂任务,如详细旅行规划(含实时天气、酒店推荐等)、办公自动化(会议总结、PPT生成)、生活服务(智能记账)及内容创作(视频生成)。其核心优势在于通过"观察-思考-行动"的工作流程,主动调用工具获取实时信息并执行操作,实现效率革

在投身AI应用开发学习前,先锚定岗位核心身份,才能让后续的学习之路不偏航。如今频繁出现在招聘启事里的“AI应用开发工程师”,也常被称作大模型应用开发工程师,堪称连接前沿大模型技术与商业价值的“桥梁型”人才。

文章探讨了通用型AI Agent与Workflow的对比,指出Workflow在业务规模化、成本控制和效率方面更具优势,最佳方案是两者结合。详细介绍了Workflow的5种常见模式:提示词链、路由、并行化、协调器-工作器、评估器-优化器。通过合理选择和结合这些模式,可构建高效、可控的大模型应用系统,在实际业务中创造更大价值。
如果你是一位普通的Java、前端或后端程序员,是否感觉技术日新月异,职业前景充满不确定性?脉脉人才智库数据显示,AI新发岗位量同比增长超过10倍,而精通AI的程序员相比纯传统技术栈开发者,薪资溢价可达 30%-50%。
微软新开源智能体框架统一AutoGen与Semantic Kernel,结合多智能体编排与企业级功能。支持Python和.NET,提供声明式工作流、可观测性、安全治理及开放标准。让AI智能体从原型直接进入生产环境,已被毕马威等企业采用,有望成为企业AI智能体的事实标准。

本文介绍阿里开源的Qwen3Guard安全审核大模型,包括生成式(Qwen3Guard-Gen)和流式检测(Qwen3Guard-Stream)两个版本,详细讲解了本地部署流程和API使用方法。作者推荐使用0.6B版本,仅需1.5GB存储空间,适合消费级显卡,可集成到工作流中实现提示词和回复的双重安全审核,有效降低AI应用安全风险。

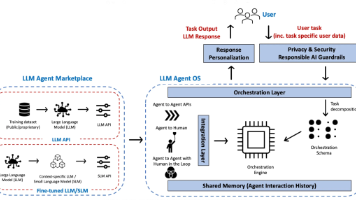
文章介绍了AI Agent发展的两大核心标准MCP和A2A。MCP(模型上下文协议)负责垂直整合,解决代理如何调用工具和数据的问题;A2A(代理到代理协议)负责水平整合,解决代理间协作和对话问题。两者互补而非替代:MCP帮助单个代理获取外部资源,A2A促进多代理协作交流。这两大协议共同构成了未来复杂可扩展多代理系统的关键基础设施。
