




- @DEVELOPERAA
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2个月转型AI产品经理,拿下25K的offer!把握这几点,你也可以做到!
建议收藏!人人都能学会的企业级AI知识库搭建教程(附8大踩坑指南),大模型入门到精通,收藏这篇就足够了!

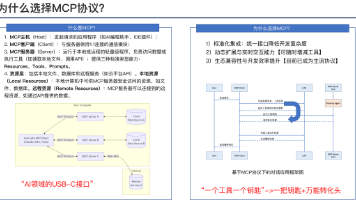
最近主导了一款ai agent系统的开发,在定架构的时候选择了MCP协议,在期间遇到不少坑点,记录顺分享一下相关内容。
DeepSeek系列引来了低调更新,目前DeepSeek官网线上已更新到了V3.1版本(不选择深度思考,模型名为DeepSeek-V3.1-Base)

本文将详细介绍如何将 DeepSeek v3.1 集成到 Claude Code 中,实现高效的 AI 辅助编程。

阿里开源迄今迄今为止最强大的开放代理代码模型 Qwen3-Coder-480B-A35B-Instruct 和对标 Claude Code 的 Qwen Code。

Ollama 为本地部署大模型的框架,DeepSeek-R1-0528-Qwen3-8B 已上架 Ollama,感兴趣的读者可尝试安装 Ollama,在本地部署运行 DeepSeek-R1-0528 模型。
本文主要介绍了当前构建基于大语言模型的应用时最主流的 RAG 的核心思想、基本工作流程,RAG 与 LlamaIndex、GraphRAG、 RAGFlow 之间的关系与区别以及RAG学习建议与技术选型。
Unsloth是一个支持Llama系列、DeepSeek R1系列更快速,更少占用内存的微调库。
在这部分,我会详细介绍如何利用 AI Coding 工具优化开发流程;第二部分主要讲述使用 Claude Code 方面的经验,Claude Code 作为一款先进的 AI 编程助手,在此次实践中发挥了重要作用。