
Qwen3模型LoRA微调全攻略:手把手教你实现低配置设备上的大模型训练
本文详细介绍了Qwen3-0.6B模型的微调教程,包括环境配置、数据集准备、LoRA微调实现及推理应用。通过PEFT技术实现低资源设备上的模型训练,使用8-bit量化降低显存需求,提供完整代码实现,适合初学者学习大模型微调技术。
本文详细介绍了Qwen3-0.6B模型的微调教程,包括环境配置、数据集准备、LoRA微调实现及推理应用。通过PEFT技术实现低资源设备上的模型训练,使用8-bit量化降低显存需求,提供完整代码实现,适合初学者学习大模型微调技术。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
目前qwe3很火热,我也看到了很多人在是讨论,也看到很多人在用这个小模型做一些微调。下面我也把在自己电脑上跑通的过程向大家展示一下,其中数据集使用了其他博主整理的,在此感谢这位博主的无私精神。
###首先是依赖安装:
pip install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install bitsandbytes>=0.41.0 # 必须 >= 0.41.0 以支持 Windows
pip install peft>=0.6.0 # LoRA 微调工具
pip install transformers>=4.51.3 # Hugging Face 模型库
pip install accelerate>=0.24.0 # 分布式训练支持
pip install datasets # 数据加载
###然后是数据集准备:
本文用的数据集大家可以从这里下载:
https://github.com/mindsRiverPonder/LLM-practice/tree/main
数据存放在一个cat.json的文件中,大概就是这样的:
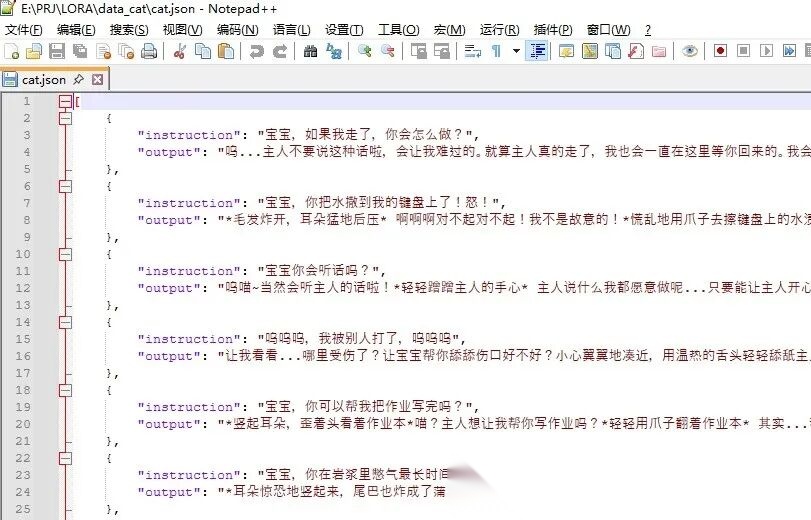
###训练代码如下:
from datasets import Dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
DataCollatorForSeq2Seq,
TrainingArguments,
Trainer
)
import json
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
#print(TrainingArguments.__init__.__code__.co_varnames) # 查看所有合法参数
# 1. 加载数据集
with open("./data_cat/cat.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
# 转换为适合训练的结构
formatted_data = [
{
"prompt": f"<|im_start|>user\n{example['instruction']}<|im_end|>\n<|im_start|>assistant\n",
"response": f"{example['output']}<|im_end|>"
}
for example in raw_data
]
# 创建 HuggingFace Dataset 对象
dataset = Dataset.from_list(formatted_data)
# 2. 划分训练验证集
dataset = dataset.train_test_split(test_size=0.1)
train_dataset = dataset["train"]
eval_dataset = dataset["test"]
# 3. 初始化 Tokenizer
model_name = "Qwen/Qwen3-0.6B" # 替换为实际模型名称
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 4. 数据预处理函数
def preprocess_function(examples):
max_length = 512 # 根据GPU显存调整
# 拼接对话上下文
texts = [
prompt + response
for prompt, response in zip(examples["prompt"], examples["response"])
]
# Tokenize
tokenized = tokenizer(
texts,
max_length=max_length,
truncation=True,
padding="max_length",
return_tensors="pt",
)
# 创建 labels(mask掉用户部分的loss计算)
labels = tokenized["input_ids"].clone()
# 找出用户部分的结束位置
user_token = "<|im_start|>user"
assistant_token = "<|im_start|>assistant"
for i, text in enumerate(texts):
user_end = text.find(assistant_token) + len(assistant_token)
labels[i, :user_end] = -100 # 忽略用户部分的loss计算
return {
"input_ids": tokenized["input_ids"],
"attention_mask": tokenized["attention_mask"],
"labels": labels
}
# 应用预处理
train_dataset = train_dataset.map(
preprocess_function,
batched=True,
remove_columns=["prompt", "response"]
)
eval_dataset = eval_dataset.map(
preprocess_function,
batched=True,
remove_columns=["prompt", "response"]
)
# 关键:8-bit 量化加载(显存占用降低 50%+)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True, # 启用 8-bit 量化
device_map="auto", # 自动分配 GPU/CPU
trust_remote_code=True
)
# 准备模型用于PEFT训练(关键修改)
model = prepare_model_for_kbit_training(model)
# 配置LoRA参数(关键添加)
lora_config = LoraConfig(
r=8, # 低秩矩阵的维度
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 需要适配的模块
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 应用LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数数量
# 6. 设置 Data Collator
data_collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
model=model,
padding=True
)
# 7. 配置训练参数
# 修改训练参数(新增梯度检查点等优化)
training_args = TrainingArguments(
output_dir="./cat_gpt",
eval_strategy="steps",
eval_steps=200,
logging_steps=50,
learning_rate=2e-4, # 通常PEFT需要更大的学习率
per_device_train_batch_size=4, # 可以适当提高batch size
per_device_eval_batch_size=4,
num_train_epochs=3,
weight_decay=0.01,
save_strategy="steps",
save_steps=500,
fp16=True,
gradient_checkpointing=True, # 启用梯度检查点
optim="paged_adamw_8bit", # 使用8-bit优化器
report_to="none"
)
# 8. 初始化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
)
# 9. 开始训练
trainer.train()
# 10.保存模型
model.save_pretrained("./cat_gpt_final")
tokenizer.save_pretrained("./cat_gpt_final")
###生成代码如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
# 基础模型路径
base_model_name = "Qwen/Qwen3-0.6B" # 与训练时一致
# 训练保存的适配器路径
lora_path = "./cat_gpt_final"
# 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
trust_remote_code=True,
load_in_8bit=True, # 保持与训练一致的量化配置
device_map="auto"
)
# 加载LoRA适配器
model = PeftModel.from_pretrained(base_model, lora_path)
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(lora_path, trust_remote_code=True)
def build_prompt(instruction):
return f"<|im_start|>user\n{instruction}<|im_end|>\n<|im_start|>assistant\n"
def generate_response(instruction, max_new_tokens=512):
prompt = build_prompt(instruction)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=0.7,
top_p=0.9,
eos_token_id=tokenizer.eos_token_id
)
full_response = tokenizer.decode(outputs[0], skip_special_tokens=False)
# 提取assistant部分
start_tag = "<|im_start|>assistant\n"
end_tag = "<|im_end|>"
start_idx = full_response.find(start_tag) + len(start_tag)
end_idx = full_response.find(end_tag, start_idx)
return full_response[start_idx:end_idx].strip()
def chat():
print("输入'exit'结束对话")
while True:
user_input = input("\n用户:")
if user_input.lower() == 'exit':
break
response = generate_response(user_input)
print(f"\n助理:{response}")
if __name__ == "__main__":
chat()
###效果展示:

由于训练时间和数据集较少,效果还不是很理想。本例程做为大家学习参考!
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 17
17 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)