




- @weixin_44292902
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
大数据人工智能相关课程培训,人工智能培训及咨询,合作抠抠526346584
OpenCLAW 是一款开源的AI智能体,由彼得·斯坦伯格开发,核心定位是“可执行、可定制的数字助理”,区别于传统仅能对话的AI,它能真正落地执行各类任务,是企业降本增效、个人提升效率的实用工具,也是本次培训的核心内容载体。
但除非你认为SM真得打不满,否则尽量不要在KV维度上做切分,因为如此一来,不同的block之间是没法独立计算的(比如对于O的某一行,它的各个部分来自不同的block,为了得到全局的softmax结果,这些block的结果还需要汇总做一次计算)。我们再看右图,它表示BWD下thread block的结构,每一列对应一个worker,这是因为BWD中我们是KV做外循环,Q做内循环,这种情况下dK, d

如果说,ChatGPT-4就像是金庸小说里的降龙十八掌,四平八稳,十分可靠,力大砖飞,那Kimi就像是小李飞刀,在长文本理解方面为我留下深刻印象,把它用对地方,依然可以做到出奇制胜。在过去的一个月里,我交叉利用Kimi和我自己的ChatGPT-4订阅,感受着两者在科研辅助上的差别,得出一个结论:尽管在一些方面仍然不如ChatGPT-4,但是Kimi在自己的长处——长文本理解——确实做得很有特色。重

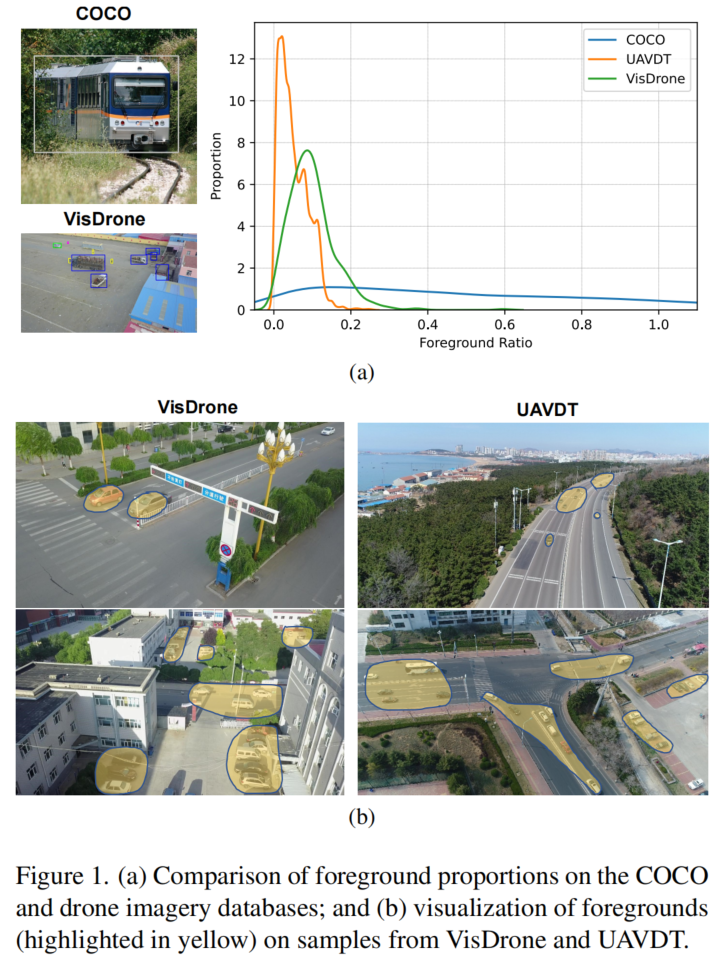
目标检测是计算机视觉任务的核心问题之一,其有效性在很大程度上取决于损失函数的定义。传统的目标检测损失函数依赖于边界框回归指标的聚合,例如预测框和真实框(即GIoU、CIoU、ICIoU等)的距离、重叠区域和纵横比。然而,迄今为止提出和使用的方法都没有考虑到所需真实框与预测框之间不匹配的方向。这种不足导致收敛速度较慢且效率较低,因为预测框可能在训练过程中“四处游荡”并最终产生更差的模型。在本文中,提
我们对世界的体验是多模态的 —— 我们看到物体,听到声音,感觉到质地,闻到气味,尝到味道。模态是指某件事发生或经历的方式,当一个研究问题包含多个模态时,它就具有多模态的特征。为了让人工智能在理解我们周围的世界方面取得进展,它需要能够同时解释这些多模态的信号。例如,图像通常与标签和文本解释相关联,文本包含图像,以更清楚地表达文章的中心思想。不同的模态具有非常不同的统计特性。这些数据被称为多模态大数据
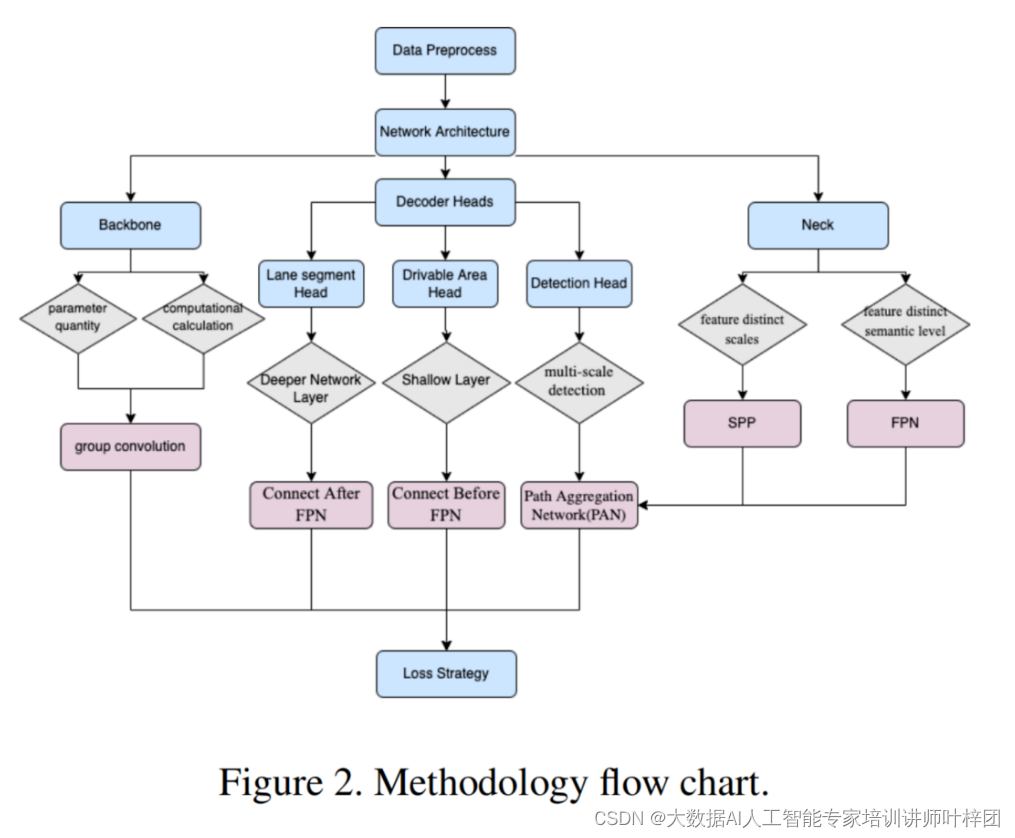
尽管计算机视觉和深度学习取得了长足的发展,但基于视觉的任务(如物体检测、分割、车道检测等)在低成本自动驾驶的应用中仍然具有挑战性。最近已经努力建立一个强大的全景驾驶感知系统,这是自动驾驶的关键组成部分之一。全景驾驶感知系统通过摄像头或激光雷达等常见传感器,帮助自动驾驶车辆全面了解周围环境。基于相机的目标检测和分割任务通常在场景理解的实际使用中因其低成本而受到青睐。目标检测在提供交通障碍物的位置和大
深度神经网络(如细胞神经网络和Transformer)的最新进展显著提高了在公共基准(如COCO)上的目标检测性能。相比之下,为无人机平台设计检测器目前仍然是一项具有挑战性的任务。一方面,现有的研究热衷于设计复杂的模型,以在高分辨率无人机图像上达到微小目标的高精度,这在计算上很不划算的。另一方面,无人机配备的硬件往往受到资源限制,这对轻量级部署模型提出了快速推理和低延迟的迫切需求。为了解决准确性和

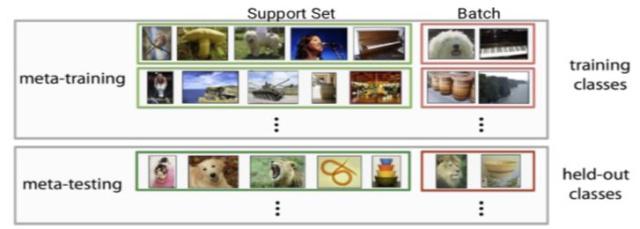
因此面向泛化性的表达是有益的。Meta Learning,又称为 learning to learn,在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。在人类的快速学习能力的启发下,研究人员希望机器学习模型在学习了一定类别的大量数据后,对于新的
这种集成有助于将数据有效地摄取到 Neo4j Vector Index 中,简化了 RAG 应用程序中的数据摄取和查询,并能够构建有效的 RAG 应用程序,通过利用结构化和非结构化数据提供实时、准确且与上下文相关的答案。例如,如果我们使用向量相似性搜索来检索前三个结果,则摘要将重复三次。例如,如果我们想要创建一个问答系统,根据提供的上下文生成答案,同时还提供它用作上下文的文档,我们可以使用以下代码