
大模型应用开发必备,RAG技术详解与工具选型:LlamaIndex、GraphRAG、 RAGFlow
文章详细介绍RAG(检索增强生成)的核心思想、工作流程及优势,解析三种主流RAG工具的区别与选型:LlamaIndex作为功能强大的开发框架,提供高度定制化能力;GraphRAG利用知识图谱增强复杂问题处理;RAGFlow则是开箱即用的平台,特别适合处理复杂文档。针对不同需求人群提供了学习路径和技术选型建议,帮助开发者根据自身需求选择合适的RAG解决方案。
前言
本文主要介绍了当前构建基于大语言模型的应用时最主流的 RAG 的核心思想、基本工作流程,RAG 与 LlamaIndex、GraphRAG、 RAGFlow 之间的关系与区别以及RAG学习建议与技术选型。
- RAG 检索增强生成(Retrieval-Augmented Generation)
首先, RAG 不是一个工具,而是一种技术范式或架构思想。
1.1.RAG 核心思想:
让大语言模型在回答问题时,能够参考并引用给定的、特定的、最新的知识库,而不是仅仅依赖其训练时学到的、可能已经过时或不够详细的知识。
1.2.为什么需要 RAG?
-
解决知识滞后问题: LLM 的知识截止于其训练数据。 RAG 可以接入最新的文档、数据库、新闻等,让模型“与时俱进”。
-
减少幻觉: LLM 有时会“一本正经地胡说八道”。 RAG 强制模型基于检索到的真实内容进行回答,大大降低了编造信息的风险。
-
增强专业性和可解释性:可以针对特定领域(如法律、医疗、公司内部文档)构建知识库,使回答更具专业性。同时,可以给出答案的来源(引用),方便用户验证。
-
保护数据隐私:可以将私有数据(如公司内部资料)通过 RAG 体系提供给模型,而无需将这些敏感数据用于公开的模型训练。
1.3.RAG 的基本工作流程:
一个经典的 RAG 流程,包含两个主要阶段:
1.3.1. 索引阶段:
Step1.加载:从各种数据源(PDF,Word,TXT,数据库等)加载数据。
Step2.分块:将大文档分割成更小的、有意义的文本块。
Step3.向量化:使用嵌入模型将每个文本块转换成一个向量(一串数字),这个向量代表了文本块的语义。
Step4.存储:将这些向量和对应的原始文本块存入一个专门的向量数据库中,以备后续检索。
1.3.2. 检索与生成阶段:
Step1.用户提问:用户输入一个问题。
Step2.问题向量化:使用同样的嵌入模型,将用户问题也转换成一个向量。
Step3.相似性检索:在向量数据库中,计算问题向量与所有文本块向量的相似度,找出最相关的TopK个文本块。
Step4.构建提示:将检索到的相关文本块和用户的原始问题组合成一个精心设计的提示。
Step5.生成回答:将这个提示输入给 LLM,让 LLM 基于提供的上下文(检索到的文本块)来生成最终答案。
- LlamaIndex
LlamaIndex 就好比是 RAG 的“瑞士军刀”或“引擎”,它是一个专门为构建 RAG 应用而设计的、功能极其强大的 Python/C++ 数据框架。如果说RAG是“造一辆车”的理念,那么 LlamaIndex 就是提供发动机、变速箱、底盘、方向盘等所有核心零部件和组装工具的“工具箱”。
LlamaIndex 开源项目在GitHub上,现在关注度已高达43.6K星数,在文章末尾处我已附上传送门,强烈推荐感兴趣的小伙伴们关注一波,尤其是想深入了解RAG底层工作原理源码的作为开发人员。
2.1.LlamaIndex 的核心
LlamaIndex 的核心是 “数据连接”,提供了从数据 ingestion(摄取)、indexing(索引)、querying(查询)到 evaluation(评估)的全套工具链,让你能够轻松地将任何数据源与 LLM 连接起来。
2.2. LlamaIndex 的主要功能模块
(1)数据连接器:支持从数百种数据源(本地文件、云存储、数据库、 API、 Web 等)读取数据。
(2)数据索引:提供了多种高级索引结构,远不止简单的向量索引。
----向量存储索引:最基础的 RAG 索引。
----树索引:将文档构建成树状结构,可以从上到下或从下到上检索,适合总结性任务。
----关键词表索引:提取关键词,实现精确匹配。
----知识图谱索引:可以构建实体和关系图,是 GraphRAG 的基础之一。
(3)查询引擎:提供了灵活的查询接口。你可以定义复杂的查询策略,比如先进行向量检索,再进行关键词检索,最后将结果融合。
(4)检索后处理:对检索到的结果进行重新排序、过滤或转换,以提高相关性。
(5)代理与工具:可以将 RAG 系统作为一个工具,集成到更大的 LLM 代理中,让代理能够自主决定何时以及如何查询知识库。
(6)评估工具:提供了一套完整的评估框架,用于衡量你的 RAG 系统表现如何(如回答的忠实度、相关性等)。
2.3.LlamaIndex 的特点
----灵活性极高:几乎可以定制 RAG 流程的每一个环节。
----功能全面:覆盖了从数据到评估的整个生命周期。
----社区活跃:是 RAG 领域最流行的框架之一,拥有丰富的文档和社区支持。
3.GraphRAG
GraphRAG 是 RAG 的“进化版”,同样也是一种技术范式,是 RAG 的一种高级实现方式,它利用了知识图谱来增强检索。如果说 RAG 是“关键词匹配”的升级版(语义匹配),那么 GraphRAG 就是“理解实体关系”的升级版。
3.1.GraphRAG 核心思想
传统 RAG 在处理复杂、多跳、需要理解实体间关系的问题时表现不佳。例如,当你问 “《流浪地球》原著作者的另一部知名作品是什么? ”,传统 RAG 可能需要先检索到“刘慈欣”和“流浪地球”,再检索“刘慈欣”和“三体”,这个过程是割裂的。而 GraphRAG 在索引阶段就将知识构建成一个知识图谱,其中节点代表实体(如“刘慈欣”、 “流浪地球”),边代表实体间的关系(如“作者”、 “作品”)。
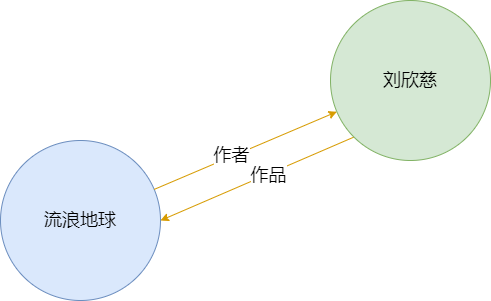
3.2.GraphRAG 的工作流程:
3.2.1. 索引阶段:
Step1.文档处理:同样需要加载和分块。
Step2.知识图谱构建:这是最关键的一步。使用 LLM 或专门的 NLP 模型从文本中抽取实体和关系,然后构建成一个图结构。
Step3.图存储:将构建好的知识图谱存入图数据库(如 Neo4j, NebulaGraph)中。
3.2.2. 检索与生成阶段:
Step1.用户提问:用户输入问题。
Step2.图查询:将问题转化为图查询。例如,上述问题会被转化为“找到节点‘流浪地球’,找到其‘作者’关系指向的节点,再从该节点出发,找到其‘作品’关系指向的其他节点”。
Step3.子图检索:从知识图谱中检索出与问题相关的子图(一个由节点和边构成的小网络)。
Step4.生成回答:将检索到的子图信息作为上下文,交给 LLM 生成答案。
3.3.GraphRAG 的优势
-
处理复杂问题:擅长回答需要多步推理、理解实体间关系的问题。
-
更高的准确性和可解释性:答案基于明确的实体和关系,逻辑链条清晰,更容易追溯来源。
-
发现隐含知识:图结构可以揭示文本中未直接明说的隐含关系。
3.4.GraphRAG 与 LlamaIndex 的关系
LlamaIndex 提供了构建 GraphRAG 的工具(如 KnowledgeGraphIndex),你可以使用LlamaIndex 来实现 GraphRAG 的流程。
微软开源了一个名为 graphrag 的项目,它提供了一套完整的、端到端的 GraphRAG 解决方案,包括从文本构建图的管道和查询引擎。graphrag 开源项目在GitHub上的关注度已高达27.2K星数,在文章末尾处,已附上传送门,感兴趣的小伙伴们可以自行查阅。
- RAGFlow
RAGFlow 是一个开源的、基于深度文档理解的 RAG 引擎和平台。如果说 LlamaIndex 是给你零件让你自己组装,那么 RAGFlow 就更像是一辆已经组装好,并且带有漂亮仪表盘和操作界面的“成品车”。
4.1.RAGFlow 的核心
RAGFlow 的核心是提供一个开箱即用的 RAG 平台,特别强调对复杂文档的理解能力。它不仅有后端引擎,还提供了一个非常友好的 Web UI,让非技术人员也能轻松上手。
RAGFlow 开源项目在GitHub上,目前的关注度高达62.2K星数,对于零基础小白想要快速应用RAG的小伙伴们,这里我强烈推荐,在文章末尾处,已附上传送门。
4.2.RAGFlow 的主要特点:
(1)深度文档理解:这是 RAGFlow 的最大亮点。它不仅仅做简单的文本分块,而是能够理解文档的布局,比如识别标题、段落、表格、图片,并能从中提取有意义的信息。这对于处理 PDF、扫描件、报告等复杂格式非常有效。
(2)友好的 Web UI:提供了可视化的操作界面,可以方便地上传数据集、创建知识库、进行对话测试、查看答案来源等。
(3)模板化的 RAG 流水线:内置了多种针对不同场景的 RAG 处理模板(如通用、简历、论文、手册等),用户可以根据自己的数据类型选择合适的模板。
(4)系统集成:它本身就是一个完整的应用,包含了 API 服务器、前端界面、后台任务调度等,部署后即可使用。
(5)可扩展性:虽然是开箱即用,但也支持通过 API 和配置进行一定程度的定制。
4.3.RAGFlow 与 LlamaIndex 的关系
RAGFlow 在其底层实现中,也会用到类似 LlamaIndex 或 LangChain 这样的框架思想,但它将这些复杂性都封装在了内部。对于用户来说,你不需要直接调用 LlamaIndex 的API,而是通过 RAGFlow 提供的界面或 API 来使用它已经构建好的 RAG 能力。
5.RAG学习建议与技术选型
如果你是开发者,想从零开始构建一个高度定制化、功能强大的 RAG 应用:首选 LlamaIndex。它给你最大的控制权,你可以自由组合各种索引、检索器和 LLM。需要你有一定的编程基础。
如果你的问题涉及大量实体关系和复杂推理,那么可以在 LlamaIndex 的基础上实现GraphRAG,或者直接集成微软的 graphrag 库。需要你有一定的知识图谱知识基础。
如果你是企业或个人,想快速搭建一个知识库问答系统,特别是你的数据主要是PDF、 Word 等复杂文档,且希望有友好的管理界面:首选 RAGFlow。它能让你在几分钟内启动一个功能完备的 RAG 系统,而无需编写大量代码。它的深度文档理解能力是其杀手锏。特别适合零基础小白入门RAG。
如果你只是在学习或了解 RAG:先理解 RAG 的基本思想和工作流程,然后了解 LlamaIndex 和 GraphRAG 分别解决了 RAG 中的什么问题(前者是工程化和灵活性,后者是处理复杂推理),最后体验一下 RAGFlow,看看一个成熟的 RAG 产品是什么样的。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐


 8
8 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)