




- @qingkahui24689
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
今天给大家介绍一篇清华大学的时间序列预测最新工作,提出了统一的Transformer时序预测模型,能同时处理单变量和多变量时序预测,并将时序预测的上下文长度首次扩充到千级别。构建类似NLP领域的统一大模型是时序预测领域近期研究的焦点。虽然前序已经涌现很多工作,但是这些建模方法只能处理最多几百长度的上下文序列,比如根据历史200个数据点预测未来时刻的序列值。而NLP中的建模可以利用千级别甚至万级别的
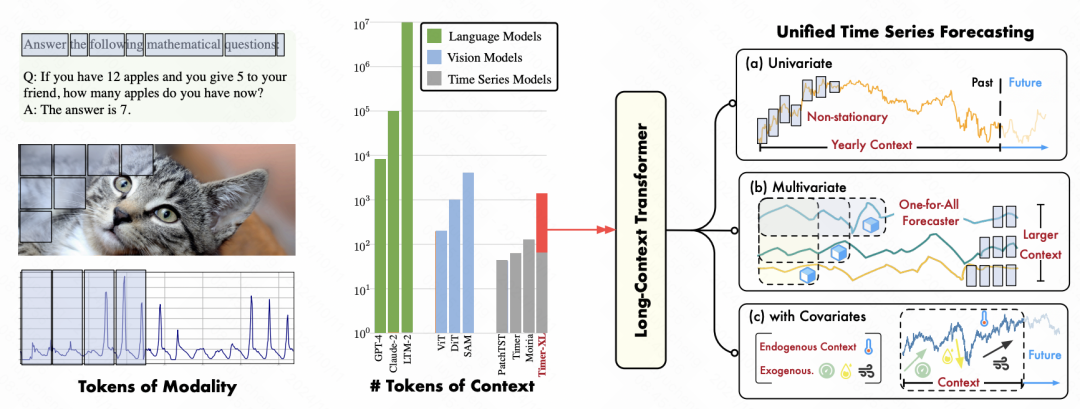
导读 向量数据库是高效处理和准确检索高维数据的基石,对于生成式 AI 技术而言至关重要。本文将分享向量数据库的架构设计和实现中的关键点。主要分为五个方面:向量数据库背景介绍Milvus 整体架构设计性能的关键-索引面向 AI 持续进化01向量数据库背景介绍1. 什么是向量数据我们经常会遇到一些非结构化数据,比如图片、视频、语音、文本等,它们通过模型被向量化,进而有助于模型的理解、训练和推理。向量,
本文可谓是千呼万唤使出来,很多同学问我,AI方向的知识多而杂,哪些该重点学习?学习路径又是怎么样的呢?今天,我将自己的学习路径及我所参考的资料全部免费分享出来,愿大家的AI学习进阶之路上多一些“温度”。在我学习人工智能的过程中,主要有以下两个途径:AI知识大体可以分为5个模块,接下来我会依次介绍每个模块的学习路径,最后给大家推荐几个我入门时做过的项目,帮助大家快速入门人工智能。在AI领域,目前大部

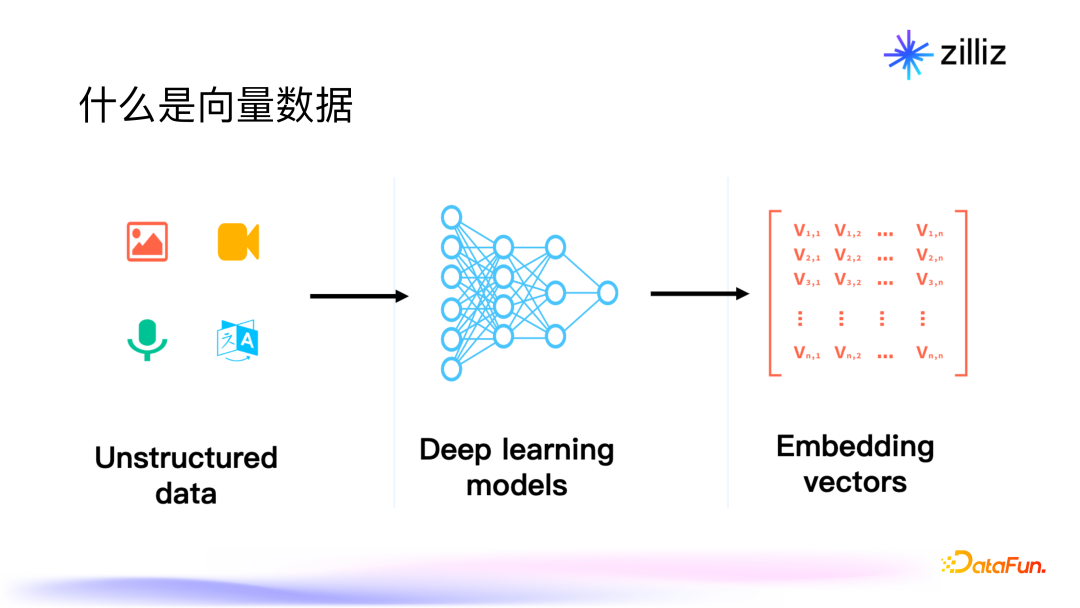
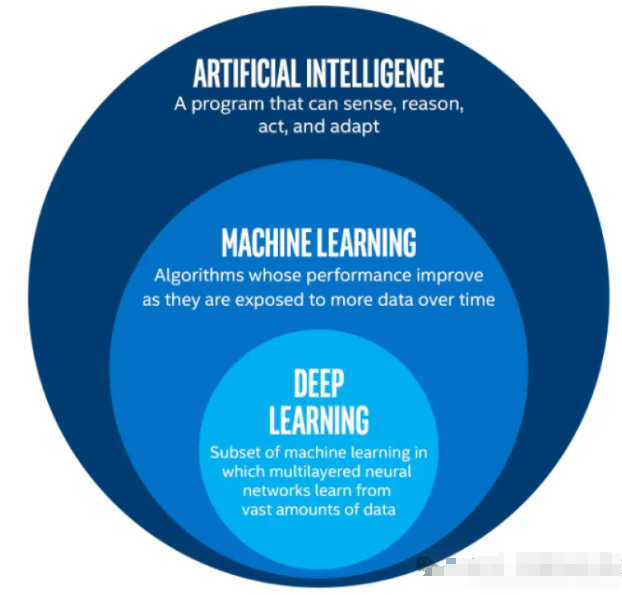
通俗来说,人工智能就是让计算机像人类一样思考、学习和做出决策。通过利用各种技术(如机器学习、深度学习、专家系统等),人工智能系统可以处理和分析大量数据,自主地学习和优化算法,从而完成各种复杂的任务。人工智能的应用非常广泛,包括但不限于语音识别、图像识别、自然语言处理、智能推荐、智能客服等。具体的,从技术层面来看(如下图),现在所说的人工智能技术基本上就是机器学习(含深度学习)方面的技术。机器学习、
随着数据时代的到来,数据分析师变得越来越热门。数据分析师几乎覆盖了所有的行业,从数据类公司、咨询公司到物流、传媒公司等,处处都渗透着数据分析的内容。也是由于数据分析人才缺口大、行业薪资高、职业寿命长、行业薪资高等优点,吸引了越来越多的人转行数据分析师。良禽择木而栖,转行是为了追求更好的工作和生活,这是无可厚非的,但是对于转行这种可能会关系到我们未来的职业和生活的大决定,一定要慎重,我们在转行之前要

最近有很多同学想要学习大模型,于是我根据多年的学习经验,总结了一些适合你从 0 到 1 的入门经验,分享给大家呀

何为数据分析?数据分析流程是啥?指用专业的统计分析方法对大量数据进行分析,并加以详细研究和概括总结,提取有价值的信息,形成有效的分析结论,从而影响业务决策。

近日,中国人工智能学会发布了《中国人工智能大模型技术白皮书》。白皮书全面梳理了大模型技术的发展历程、关键技术、生态发展、应用实践等方面的最新进展,并对其未来趋势做出展望。大模型技术,以其广阔的应用前景和巨大潜力,无疑成为了技术发展的焦点。然而,随之而来的挑战亦不容忽视:可靠性、可解释性的难题需要我们去攻克,数据质量与数量的提升成为迫切需求,应用部署成本的降低与迁移能力的增强同样重要,而安全与隐私保

摘要: 本文探讨AI智能体的记忆优化策略,针对大模型上下文窗口限制导致的对话丢失和算力冗余问题,系统梳理8类主流记忆机制:全量记忆、滑动窗口记忆、相关性过滤、摘要压缩、向量库检索、知识图谱存储、分层记忆及类操作系统内存管理。通过对比不同策略的优劣(如全量记忆无损但成本高,摘要压缩高效但可能失真),帮助开发者根据业务场景定制方案。文档附有技术图解和学习资源,涵盖大模型Agent全套开发资料,可供从业
摘要: 本文探讨AI智能体的记忆优化策略,针对大模型上下文窗口限制导致的对话丢失和算力冗余问题,系统梳理8类主流记忆机制:全量记忆、滑动窗口记忆、相关性过滤、摘要压缩、向量库检索、知识图谱存储、分层记忆及类操作系统内存管理。通过对比不同策略的优劣(如全量记忆无损但成本高,摘要压缩高效但可能失真),帮助开发者根据业务场景定制方案。文档附有技术图解和学习资源,涵盖大模型Agent全套开发资料,可供从业