- @python1234_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
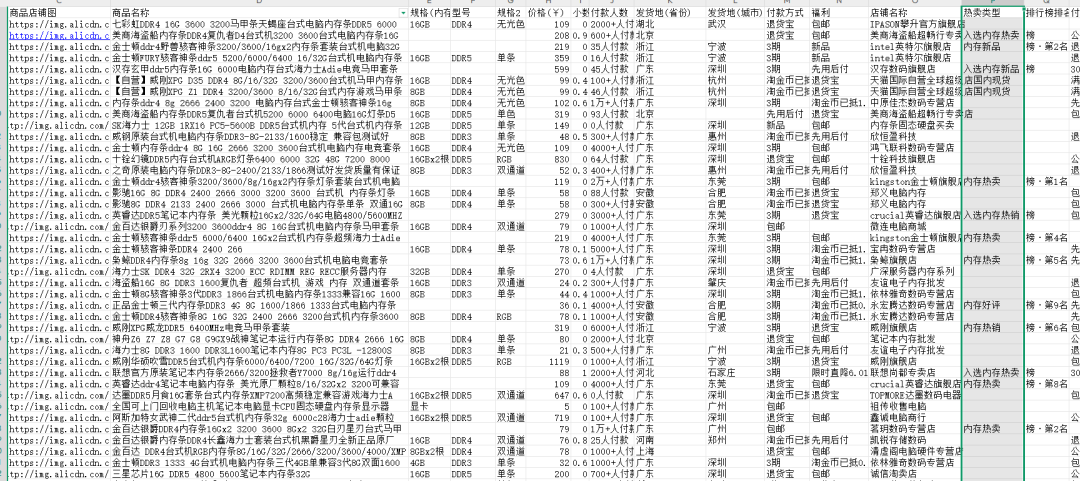
搭建之后也关系到你的虽然fastgpt支持直接导入Excel,但是,导入知识库的,导致知识库问答效果不佳。优化知识库的问答效果不是一蹴而就的,需要经过反复调整,反复测试。而且是多维度的优化。语言模型、索引模型、重排模型、RAG的方式、数据的质量、知识库的参数、大模型的参数等等都会对知识库的问答效果产生影响。数据预处理我们先达成共识,在知识库把数据转换为向量之前,对原始文件做的数据清洗、整理、优化叫
我们这里选择直接部署docker,简单方便,docker部署忽略docker镜像地址: https://hub.docker.com/r/ollama/ollama# 拉取docker镜像# AMD显卡# 英伟达显卡# cpu onlyopenweb ui参考仓库地址:https://github.com/ollama-webui/ollama-webui-lite我们可以使用Ollama提供的创

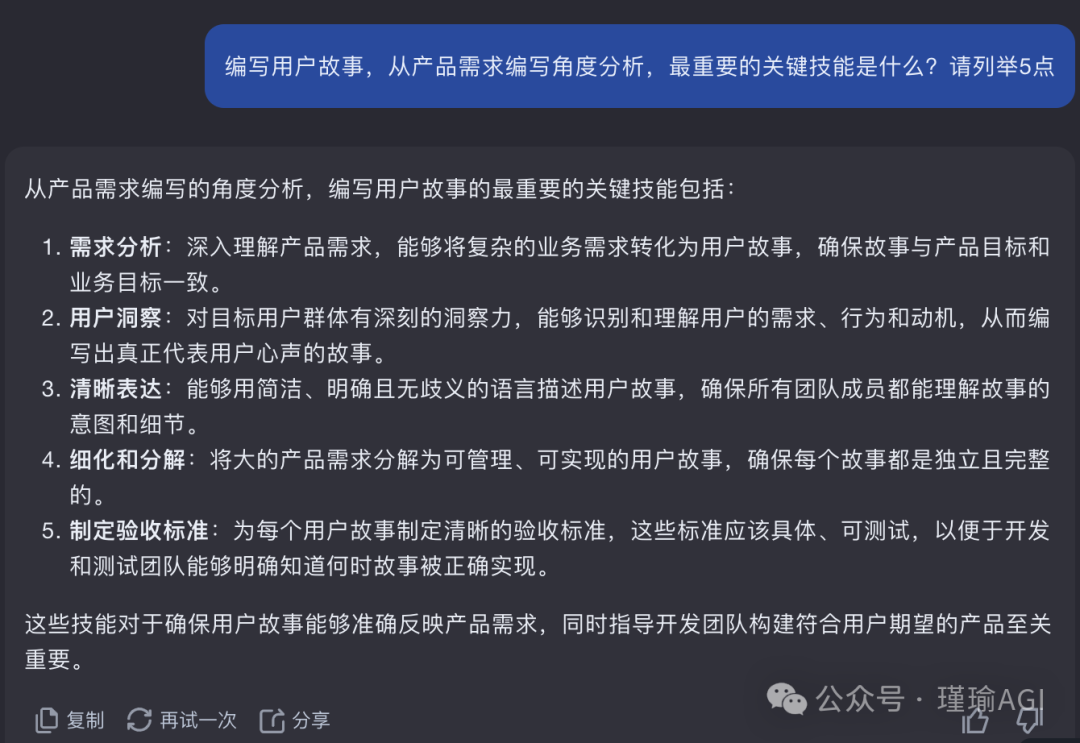
在AI时代,可能人人都可成为产品经理。之前我们聊过如何使用kimi协助完成产品需求文档,如何写竞品分析报告,这一篇我们聊聊用户故事,如何使用kimi协助撰写产品需求文档中的用户故事。在此之前我们先了解下什么是用户故事?**用户故事(User Story)**是敏捷软件开发中的一种高效工具,用于捕捉产品功能的简短描述。它是从最终用户的角度来描述产品功能的一种方式,通常遵循一个简单的模板:“作为[角色
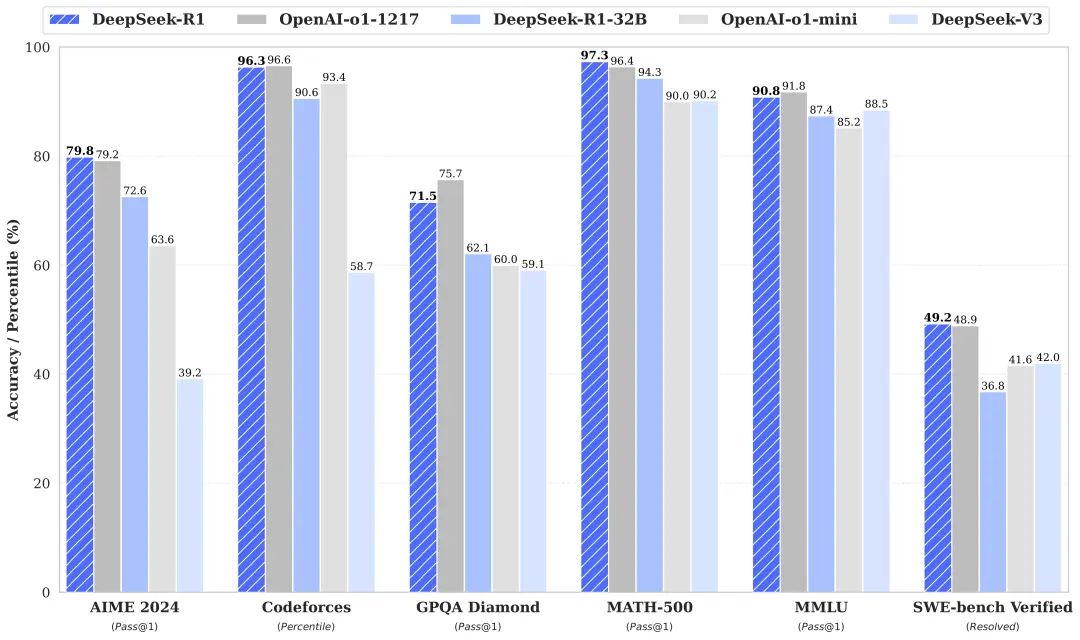
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效
有时,Ollama 可能无法如你所愿运行。解决问题的一个好方法是查看日志。(使用 docker ps 可以找到容器的名字)如果你是在终端里手动运行 ollama serve,那么日志会显示在该终端上。在 Windows 上运行 Ollama 时,日志的存放位置有一些不同。Ollama 内置了多个为不同 GPU 和 CPU 向量特性编译的大语言模型(LLM)库。Ollama 会尝试根据你的系统能力选

本文聊聊 LLama-Factory,它是一个开源框架,这里头可以找到一系列预制的组件和模板,让你不用从零开始,就能训练出自己的语言模型(微调)。不管是聊天机器人,还是文章生成器,甚至是问答系统,都能搞定。而且,LLama-Factory 还支持多种框架和数据集,这意味着你可以根据项目需求灵活选择,把精力集中在真正重要的事情上——创造价值。使用LLama-Factory,常见的就是训练LoRA模型

大模型/大模型,全称叫大规模语言模型大规模语言模型/(Large Language Model,简称 LLM)。你可以把它理解成一个超级聪明的"大脑"/超级聪明的"大脑"/它读过了互联网上几乎所有的文字它学会了人类的语言习惯和知识它可以像人一样和你聊天、帮你写文章、回答问题大模型,就是一个读遍全网知识、经过海量训练、具备超强理解和生成能力的"超级大脑"。大模型,就是一个读遍全网知识、经过海量训练、
🇨🇳 国内模型:通义千问(Qwen):阿里出品,综合能力强DeepSeek:深度求索,代码和推理出色Kimi:月之暗面,长文本处理优秀文心一言:百度出品,中文理解好🌍 国外模型:GPT-4:OpenAI,行业标杆Claude:Anthropic,安全性和长文本优秀Gemini:谷歌,多模态能力强近期科技圈传来重磅消息:行业巨头英特尔宣布大规模裁员2万人,传统技术岗位持续萎缩的同时,另一番景象
回想起来,Transformers库最大的价值不是让我们变懒了,而是降低了AI的门槛。以前只有大厂才能玩得起的深度学习模型,现在个人开发者也能轻松上手。这种技术民主化的趋势,正在重塑整个行业的格局。不过话说回来,工具再好,基础还是要扎实。理解Attention机制、掌握模型调优技巧、知道何时该用什么模型,这些"内功"才是真正的核心竞争力。毕竟,会用锤子不等于会盖房子,你说对吧?
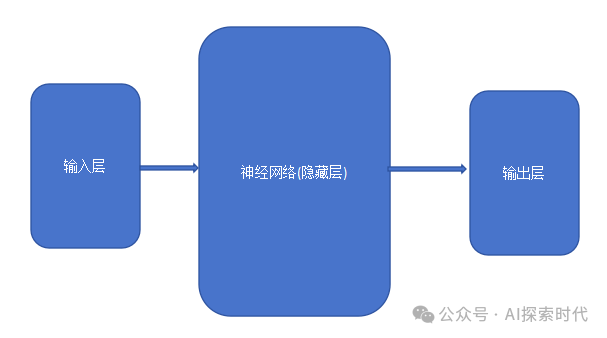
根据不同的任务,神经网络也分为不同的类型,比如分类任务,文本处理任务,图片处理任务等。根据不同的网络架构也有不同的实现方式,比如全链接层就需要所有神经元参与计算。在由多层网络组成的隐藏层中,每一层的输入都是上层的输出,每一层的输出就是下一层的输入。简单来说,神经网络就由其三大组件(输入层,隐藏层和输出层)组成,每一层根据不同的任务都会有不同的实现,重要的就是其泛化和扩展的能力。最后,经过损失函数计