- @Y525698136
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2025年的一个深夜,我习惯性地打开电脑处理一些工作。身为一个从大厂转型的自由职业者,夜晚往往是我效率最高的时段。
作为一个亲历多次技术变革的普通工程师,我深知技术原理常常是应用的最大障碍。今天,我将揭开AI Agent的技术面纱,用通俗易懂的方式解释其核心原理和构建方法。
每一次技术范式转移,都会造就新王者。AI Agent不是工具那么简单,它是新一代生产力革命的引擎,是认知、能力与组织方式的重塑器。行动比理解更重要。如果你能提早融入这股浪潮,也许下一个10年,你将站在时代的更高处,见证新的世界格局。无论你是学生、职场人士、创业者,还是决策者,拥抱Agent,是一次必然选择。
在本地运行大语言模型:使用 Ollama 导入模型详解 🚀
首先作为一位有3年从业经验、从零自学上岸的大模型算法工程师,3年前,我也和很多朋友一样,对LLM充满好奇但不知从何入手。
本文主要介绍了为企业管理者、产品经理、技术负责人和开发者提供一套从概念到技术变革的系统性框架,帮助小伙伴们成功地将AI Agent从概念转化为实际价值。
最近主导了一款ai agent系统的开发,在定架构的时候选择了MCP协议,在期间遇到不少坑点,记录顺分享一下相关内容。
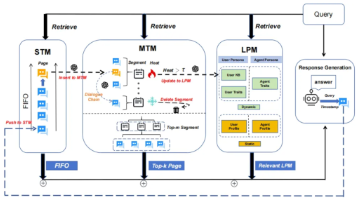
本文将深入讲解如何在 FastAPI AI 聊天应用中设计和实现多模型厂商架构,让你的应用能够灵活切换不同的 AI 提供商,提升系统的可靠性和成本效益。
本文将深入介绍如何在 FastAPI AI 聊天应用中实现用户历史消息功能,当用户切换助手,刷新页面时,都可以保留当前会话历史消息。
AI Agent旨在自主推理、规划和采取行动。为了有效运作,构建AI Agent应该遵循一些基本原则,可使AI agent在实际应用中更加可靠、智能且实用