




- @lvaolan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
经常有朋友问我,如何打造一个商用 AI Agent(智能体)?是选择 Coze?Dify?还是 LangGraph ?过程中有哪些注意事项?我的数据应该存储在哪里?为什么某些网页用这个工具无法抓取到内容?
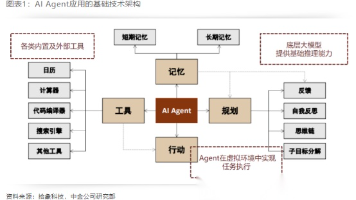
AI Agent是AI的升级版,使用门槛更低,功能更强大,能独立思考并拆解任务执行。未来许多岗位将受到AI Agent的影响甚至被取代。AI Agent = 大模型 + 规划 + 记忆 + 工具,但目前仍面临数据获取、多工具协同、信任和责任归属等挑战。未来发展空间巨大,3-5年可能迎来跨越式发展,每个人都有弯道超车的机会。当下学习和使用AI Agent至关重要。
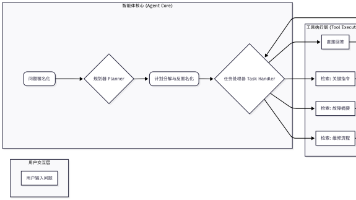
文章详细介绍了构建Agent驱动的生产级RAG系统全流程,包括数据预处理、多策略分块、智能体规划、思维链推理及自动化评估。通过工业设备维修手册案例,展示了使用LangChain、LangGraph和RAGAS等工具实现从原始数据到高质量智能问答系统的技术细节与开发思路,为开发者提供了实用的参考。
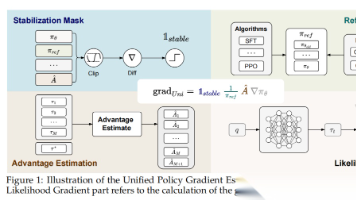
清华大学等机构研究人员提出统一策略梯度估计器(UPGE),将大语言模型后训练的监督微调(SFT)和强化学习(RL)方法统一到一个理论框架中,并基于此开发混合后训练(HPT)算法。该算法通过动态调整SFT和RL损失比例,实现探索与利用的平衡。实验证明,HPT在多个数学推理基准上显著优于传统方法,不仅提高了模型性能,还增强了探索能力,为LLM后训练提供了新思路。
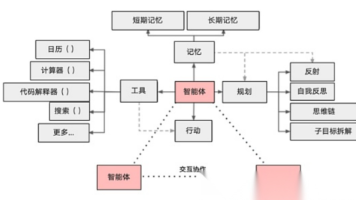
AI智能体整合大模型(大脑)、记忆系统、工具调用和规划能力,实现从被动响应到主动执行和动态优化。技术路线已清晰,产业加速发展,C端注重通用性,B端注重场景化。未来将向智能体协同群演进,构建"智联网",成为通用级生产力,实现跨域协作。
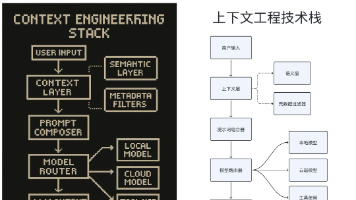
文章探讨了AI Agent在生产环境中成功的关键因素。95%的AI Agent部署失败并非模型不够智能,而是支撑体系不完善。文章详细分析了上下文工程(特征选择、验证、可观测性)、语义与元数据分层架构、治理与信任机制、记忆设计(多层级架构)、多模型推理编排等核心技术。成功的AI Agent都采用human-in-the-loop设计,将AI定位为助理而非自主决策者。未来发展方向包括上下文可观测性、可
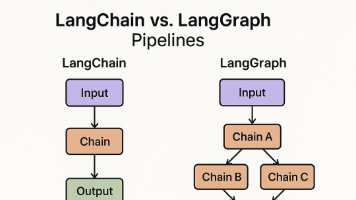
本文详细解析了大模型开发三大框架:LangChain(静态链式)、LangGraph(动态图状)和LangSmith(监控调试),以及RAG、MCP、A2A等辅助技术。文章对比了各框架特性与应用场景,介绍了Context Engineering、分层记忆系统和知识图谱等技术如何提升大模型应用效能,为开发者构建高效AI应用提供全面指导。
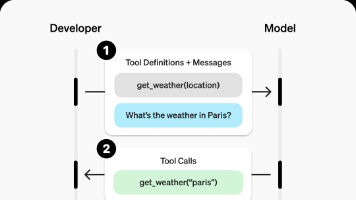
Function Calling技术解决了大型语言模型(LLM)无法执行实际操作的根本局限,通过让模型生成结构化的JSON对象来调用外部函数,实现了从"信息处理器"到"任务执行者"的转变。该技术通过JSON Schema定义函数契约,确保输出可靠性,并支持并行调用、链式调用等复杂场景。Function Calling代表了人机交互向"基于意图的计算"范式演进,使LLM能够与现实世界互动,是构建智能
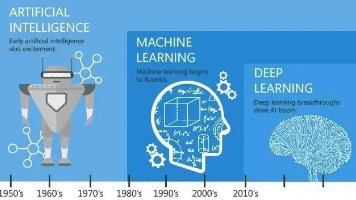
人工智能(AI):机器的“大脑”**人工智能,或者简称 AI,是一种使计算机系统模拟人类智能的技术**。这包括学习(获取信息和规则以使用信息)、推理(使用规则达到近似或确定的结论)和自我修正。
AI Agent是具备自主感知、决策和执行能力的人工智能系统。当前面临四大问题:数据链路不通、上下文支持不足、规划不稳定、评估不准确。这些问题的核心是缺乏完整的知识体系。未来AI Agent的发展关键在于构建面向特定领域的动态知识体系,将分散的知识、经验和诀窍结构化、系统化,使AI Agent能够真正成为解决问题的生产力工具,而非仅是概念热潮。
