- @ytt0523_com
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果你两年前问这个问题,我的回答会是:“先学两年 Python 再说。但 2026 年,情况完全不同了。变化一:工具链成熟了。Claude Code、扣子 3.0、字节 Trae Work……这些工具把原本需要写代码的环节,变成了自然语言对话。小米甚至开源了 AI 编程助手 MiMo Code,让普通人也能用 AI 写 AI。变化二:学习资源爆发了。两年前你学 Agent 开发,得啃英文文档、看国

本文将记录并分享在WSL中通过Ollama和CherryStudio搭建本地大模型,以及将本地模型集成到VsCode的AI助手的具体过程。
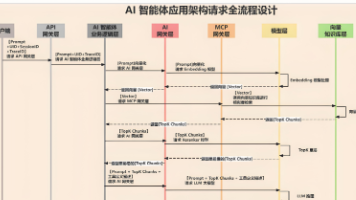
探秘AI 智能体应用架构设计全流程剖析:一次请求到底经过了哪些关键步骤?
【AI 创业避坑指南】100 个核心问题清单,AI 智能体项目从 0 到 1 必看(附收藏指南)

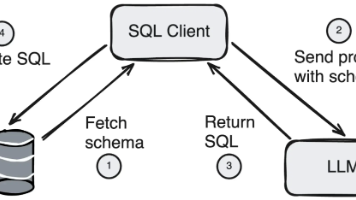
摘要: MCP(模型上下文协议)是Anthropic推出的开放标准,旨在简化大模型(LLM)与外部工具/数据的交互。它通过标准化接口实现“即插即用”功能,降低非技术用户调用工具的门槛。MCP采用客户端-服务器架构,提供资源、提示和工具三类服务,将复杂集成转化为标准化流程(如Text-to-SQL场景)。实际案例中,开发者可通过MCP为AI代理动态扩展能力(如GitHub仓库搜索)。与Functio
在人工智能的应用实践中,**检索增强生成(RAG)系统**已成为处理简单信息查询的成熟方案——它能通过检索外部知识库获取精准信息,快速生成与上下文高度匹配的回答,有效解决了大模型“知识过时”“幻觉生成”等基础问题。然而,随着AI应用向复杂场景(如多步骤任务规划、动态流程协作、长周期决策支持等)深入,仅靠RAG的“单次检索-单次生成”模式已难以满足需求:我们迫切需要一种能实现**多步逻辑推理、实时保
在本篇文章中,我们将基于 LangGraph 构建一个具备自主决策能力的检索代理。这个代理能让大语言模型(LLM)根据用户需求自主判断:是需要从向量库中检索相关上下文辅助回答,还是可以直接响应用户问题。具体实现流程将分为三个核心步骤:准备并预处理用于检索的文档资源,为后续语义理解奠定基础;对文档进行语义搜索索引构建,并开发适配代理的检索工具;搭建融合代理能力的 RAG 系统,使其具备 "何时调用检
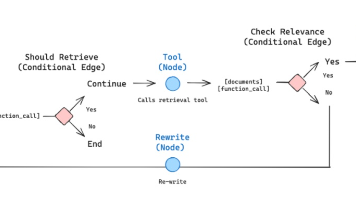
抓住 AI Agent 创业风口!程序员搭建自动化公司实现月入十万的完整指南

LangChain是大模型工程化的主流框架,提供全链路解决方案,覆盖业务编排、工具调用、知识管理和多模型协作。其核心组件包括Chains、Agents、Memory和Tools,支持智能决策、上下文管理和外部接口调用。通过微服务化部署、异步执行和负载均衡,LangChain实现高并发处理和多模型动态路由,优化延迟、吞吐量和成本。该框架降低了企业AI应用门槛,为复杂任务提供可扩展架构保障。学习资料包
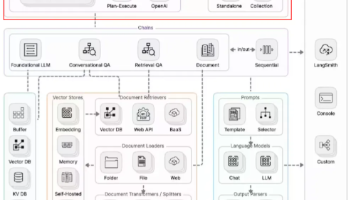
【干货收藏】从入门到实战:AI Agent企业落地全景指南,2025年企业数字化必看手册