




- @YoungOne2333
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在AI浪潮席卷各行各业的今天,AI产品经理的角色变得愈发关键。他们不仅需要洞悉技术与业务的交汇点,还要在复杂的场景中推动AI产品从概念到落地的全过程。那么,如何成为一名优秀的AI产品经理?本文将从两大定律、五要素、技术框架以及产品原则四个维度,拆解AI产品经理的必备能力,帮助你在AI时代脱颖而出。
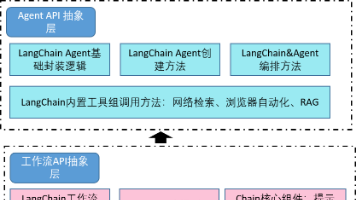
本文详解LangChain Agent API使用方法,通过create_tool_calling_agent和AgentExecutor快速构建智能体。结合天气查询和网络搜索案例,展示多工具串联、并联调用技术,解决传统链式结构不灵活问题。相比底层API,Agent能更智能地规划工具调用,满足复杂需求,帮助开发者高效搭建AI智能体。
Tiny_RAG是一个开源的高可定制RAG系统,专为解决LLM的"知识截止日期"和幻觉问题而设计。项目特色包括混合与集成检索策略提高精准度;答案可溯源增强可信度;高度模块化设计便于开发者定制。只需三步即可在本地部署,适合小白学习和实验RAG技术,社区欢迎贡献。
AI智能体是超越传统生成式AI的先进系统,由LLM、记忆模组、规划模组和工具四大组件构成,能自主推理、规划并执行复杂任务。与传统AI助手相比,它具有更高自主性和学习能力,适用于工作流优化、数据分析、软件开发等多领域应用,是程序员学习大模型技术的重要进阶方向。
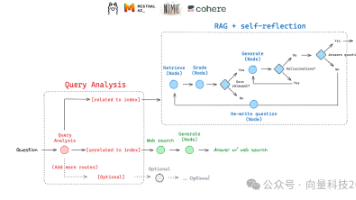
这篇文章介绍了如何使用LangGraph和本地LLM(Ollama + Mistral)构建自适应RAG系统,解决大模型知识更新慢的问题。系统能根据问题类型动态选择Web搜索或向量库检索,实现自我纠错。文章详细展示了环境准备、问题路由、检索评估、答案生成、幻觉检测等组件的实现,并通过工作流将这些组件连接,形成灵活的问答系统。该系统可处理定义类问题、近期事件问题等多种场景,避免"一刀切"的检索策略。
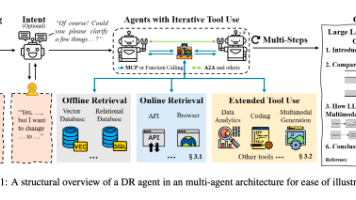
本文系统解析了AI智能体(Agent)的概念、工作机制与关键技术,以深度研究智能体为例,详细介绍了其工作流程、核心组成及实现技术。文章涵盖单/多智能体架构、RAG检索增强、Function Calling与MCP协议、记忆机制等关键技术,并通过商业产品实例帮助读者理解智能体的实际应用。文章旨在帮助读者全面理解智能体的本质,为深入学习AI Agent提供系统性的知识框架。
本文基于Llama模型源码,详细解析了大语言模型(LLM)的架构与计算流程,包括整体流程、TransformerBlock、Attention、FFN和RMSNorm等核心组件。文章通过图文结合方式展示各组件的计算过程和张量形状变化,帮助读者理解LLM内部工作原理。同时指出主流模型架构的相似性,使读者能够通过类比快速理解其他模型并应用相关优化技术。
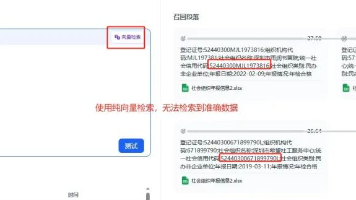
文章分享了政务领域AI实践中的常见问题及解决方案,重点关注知识库检索准确性。分析了文件类型、分段策略和大模型节点位置对检索效果的影响,提出了结构化分割、语义转换等实用方法。同时提供了处理大量文档和解决意图识别不准确的具体策略。内容结合一线实践经验,为AI开发者在政务领域的应用提供了有价值的参考。
DeepSeek推出的DeepSeek-R1系列模型采用创新强化学习策略提升LLM推理能力,包含纯强化学习的R1-Zero和混合训练方法的R1两种模型。该模型在AIME 2024测试中达到79.8%准确率,成本效益优于OpenAI同类模型。文章详细介绍了模型架构、训练方法、性能指标及三种使用方式(网页访问、API调用和本地部署),为开发者提供了从理论到实践的完整指南。

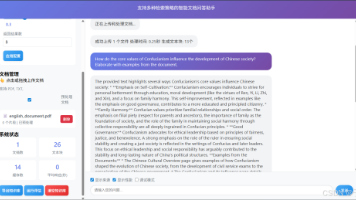
文章介绍了字节跳动方舟知识库的功能与使用方法,这款基于大模型的智能知识库支持超大容量、高吞吐和复杂文档处理,特别是图片OCR和表格解析能力出色。通过杂志、论文和试题三类文档测试,展示了其在辅助阅读、学习和解题方面的强大能力。方舟知识库支持多种文档格式,适合金融研报分析、学术研究和教育题库等多场景应用,能显著提升工作效率,是值得推荐的智能知识库服务。
