- @python12222_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
所有的项目都是基于 TailwindCSS 实现了响应式,同时支持网页端和移动端的显示效果。这期尝试开发的 AI 应用是使用通义千问的大模型 API,开发一个 AI 看舌苔的应用。整个项目的操作流程比较简单,第一屏用户上传自己的舌头的照片, 保存到 OSS 中。然后将 OSS 保存的图片发送给通义千问的大模型(这里采用了 qwen-vl + qwen-max 两个大模型),让大模型生成我们的前端

全球首个完全自主的 AI 软件工程师上线,它是来自 Cognition 这家初创公司的产品——Devin, 这个名字也随即引爆了科技圈。话说 Devin 有多能干?它能实现端到端的完整项目开发。也就是说,只需一句指令,Devin 就可以从零构建出一个完整互联网应用,其他工作还可以自主查找并修复代码中的 bug,甚至是训练和微调自己的 AI 模型。更厉害的是,Devin 还通过了一家 AI 公司的技

在这篇文章中,我们将尽可能详细地梳理一个完整的 LLM 训练流程。包括模型预训练(Pretrain)、Tokenizer 训练、指令微调(Instruction Tuning)、奖励模型(Reward Model)和强化学习(RLHF)等环节。
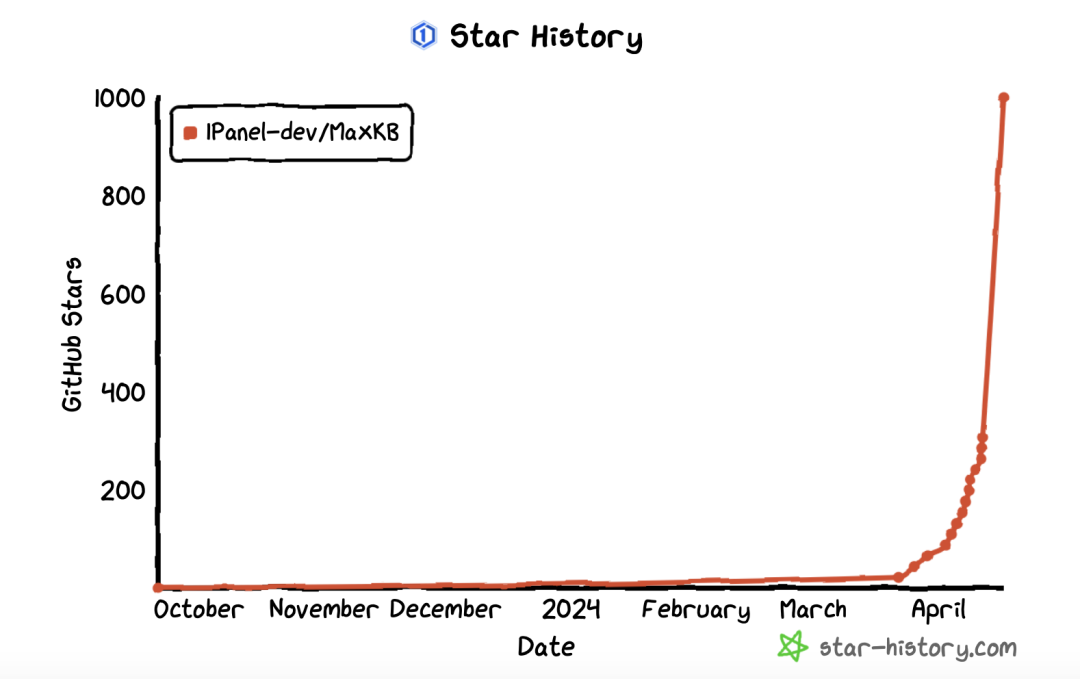
2024年4月12日,1Panel开源项目组正式对外介绍了其官方出品的开源子项目——MaxKB(MaxKB是一款基于LLM(Large Language Model)大语言模型的知识库问答系统。MaxKB的产品命名内涵为“Max Knowledge Base”,为用户提供强大的学习能力和问答响应速度,致力于成为企业的最强大脑。2024年4月16日,MaxKB成功登顶GitHub Trending主
随着ChatGPT流行,大模型技术正逐渐成为AI领域的热点。许多行业大佬纷纷投身于这一赛道,展示了大模型的独特魅力和广阔前景。,前美团联合创始人,发起“AI英雄帖”。,出门问问创始人,打造中国版OpenA。和,前亚马逊员工,师徒俩携手大模型创业。,前京东AI部门负责人,强调大模型并非大公司专属。,前搜狗CEO,认为OpenAI的成功是技术理想主义的胜利。,快手前AI核心成员,投身于大模型赛道。,阿
1、第一部分理解大型语言模型:介绍了 LLM 的基本概念、transformer架构以及训练大型语言模型所需的基础知识。5、第五部分无标签数据的预训练:讨论了如何在没有标签的数据上进行预训练,使模型能够捕捉语言的复杂性和上下文关系。3、第三部分注意力机制编程:深入探讨了注意力机制的原理及其在 LLM 中的应用,并通过代码实现了这些机制。6、第六部分模型微调:解释了如何在特定任务或领域的数据上微调预

我是土生土长的农村人,小时候经常和小鱼小虾打交道,上大学的时候就选择了农学专业,想着毕业之后回老家搞养殖种植。大学期间,我看到了一些关于养殖龙虾、稻田套养的资料,就跟我父母商量,让他们承包一块稻田或者鱼塘,养殖龙虾。但当时我父母坚决不同意,就没有做成这个事情。毕业之后,我想自己承包鱼塘搞养殖,但是没有资金,父母也不愿意支持我,所以最终还是没做成。到了去年过年的时候,我们家那边很多人都已经开始在自己

我是土生土长的农村人,小时候经常和小鱼小虾打交道,上大学的时候就选择了农学专业,想着毕业之后回老家搞养殖种植。大学期间,我看到了一些关于养殖龙虾、稻田套养的资料,就跟我父母商量,让他们承包一块稻田或者鱼塘,养殖龙虾。但当时我父母坚决不同意,就没有做成这个事情。毕业之后,我想自己承包鱼塘搞养殖,但是没有资金,父母也不愿意支持我,所以最终还是没做成。到了去年过年的时候,我们家那边很多人都已经开始在自己
比如搞学术研究,我们问专业领域的复杂问题,它可以快速翻找资料,整理出关键信息,条理清晰地解答,帮我们省下不少时间。采用以KVCache为中心的创新架构,分离预填充与解码集群,充分利用GPU资源,推理吞吐量最高提升525%,响应速度提升3倍。智谱清言通过构建大规模的知识图谱,将海量的信息进行结构化处理,使得模型能够更好地理解和运用知识,为用户提供更准确、更有深度的回答。需要强化多模态能力,数学推理较