- @huang9604
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
下面继续开始第一部分-基础知识;下面演示完整的示例代码及输出的结果;详细的概念定义可以参考每小节对应的官方描述,
Ollama社区也同步新增 Llama3 的支持。接下来,我们将在MacBook Pro上部署Llama3,让大家在本地体验最强开源大模型。
构建本地大模型-ollama-conda的安装和配置,大模型入门到精通,收藏这篇就足够了!
LangChain 是一个以大语言模型(LLM, Large Language Model)为核心的开发框架,旨在帮助开发者高效地将如 GPT-4 等大型语言模型与外部数据源和计算资源集成,构建智能化应用。

在本地玩大模型和智能体,必须有显卡(虽然本人所用的是一张入门级显卡),不然纯靠CPU,执行效率会很差。
作为AI领域的弄潮儿,你是否苦恼于云端大模型API的高昂成本?想在本机零门槛体验顶尖开源模型?这篇保姆级教程将带你解锁「Ollama+DeepSeek R1」黄金组合,文末附程序员专属玩法彩蛋!

AI 的发展经历了多个阶段,从最早的基于规则的专家系统,到如今的深度学习和神经网络驱动的智能系统,使得 AI 具备了更强的学习能力和泛化能力。

对于AI产品经理而言,绘制一张清晰且有效的AI产品架构图是至关重要的。它不仅有助于梳理产品的技术逻辑和数据流,同时也是与团队沟通、向管理层展示产品价值的重要工具。
今天,我将以第一视角拆解:为什么同样是“AI产品经理”,有人月薪3K,有人却能年薪百万?
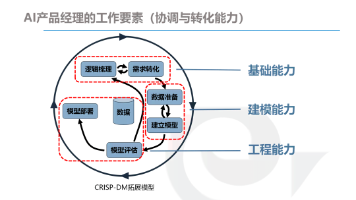
本文从技术认知、产品设计、商业思维到伦理合规,系统拆解AI产品经理的进阶路径,助你抢占AI浪潮的制高点。