- @python1222_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对于任何输入,大语言模型都会给出相应的输出,这些输入都可以成为提示词,通常,提示词由指令和输入数据组成,指令是任务,输入数据是完成的要求,其中指令应该明确,用词不能模棱两可,并可以提供清晰、详细的上下文内容,提供的内容越精确,模型的生成效果也会越好。对于复杂的任务,通过增加背景提示、让大模型扮演角色身份,给定示例,以及输出要求 ,都可以提高输出的效果。其中,背景提示可以是事件的背景,如我正在写一份
之前已为大家呈现深度学习工程师的职业发展情况但如果探索深度学习行业的时候,发觉做工程师不适合自己,想转行,那今天就一起来看看,深度学习工程师转行,能做些什么?如果转行,请选择AI产品经理岗根据深度学习行业中的各级岗位来看,工程师可以有如下方向的转型路径:转型产品经理、转型学术研究人员、转型运营经理而综合考虑,产品经理其实是最适合的转型岗位。原因有二:第一,AI产品的产品经理有很高的技术壁垒,需要了
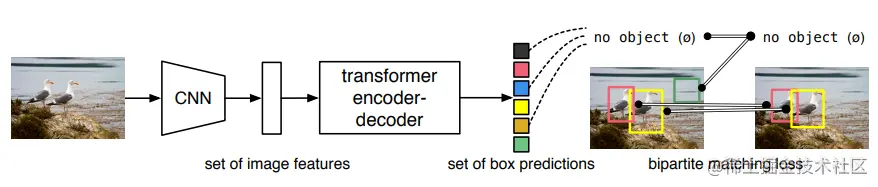
DETR即,是的研究者提出的的视觉版本,可以用于目标检测,也可以用于全景分割。这是第一个将成功整合为检测pipeline中心构建块的目标检测框架。与之前的目标检测方法相比,DETR有效地消除了对许多手工设计的组件的需求,例如非最大抑制、Anchor生成等。这篇论文主要介绍了一种名为“的新框架,它使用了一种基于集合的全局损失,通过二分图匹配强制进行唯一预测,并使用transformer编码器-解码器
根据AI行业不同的职业,如数据分析师、机器学习工程师、AI研究员等,分析了。小到你的日常homework,大到教授、学校所组织的相关Project,,在学习了基本技术后,想要进入到工作中,吴恩达还手把手教你。吴恩达就在书中给出了解答:AI中的数学可以有,但更需要有。这本书不仅胜在够新,符合当下AI行业的职业趋势,也是。☑本书由吴恩达亲撰给想进入AI的萌新,今年全新发布。整本指南共41页,虽是全英文

本文介绍如何在不依赖任何三方服务的情况下,私有化部署和使用大语言模型,以及如何以较低成本让大语言模型使用自己的数据来产生个性化输出。本文偏技术向,读者需要具备一定技术背景,如有不懂之处,欢迎留言交流。
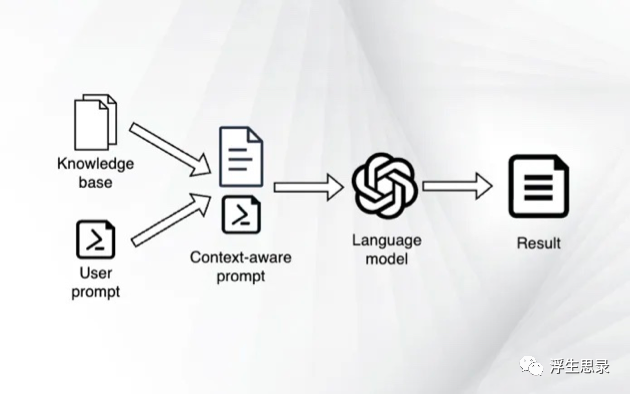
事实上,技术进步能够给我们带来的好处是,变量X的提高使得我们训练模型所需要的时间正在逐步减少,因此对于搭建自有的大模型来说,训练多大的规模参数就需要有多大规模的算力。初代大模型的推出是具有跨时代的意义,这不仅仅是让人们充分利用到大语言模型的便利性,也为更多大语言的推出铺平了道路,例如:ChatGPT训练了几乎所有能在公开渠道找到的数据,包括全部的推特数据(事实上,今年马斯克已经限制了推特API的采

现有RAG模型的评估主要强调三个主要质量分数和四个基本能力,它们共同决定了RAG模型的两个主要目标的评估:检索和生成。质量分数:上下文相关性(Context Relevance)、答案真实性(Answer Faithfulness)和答案相关性(Answer Relevance)。
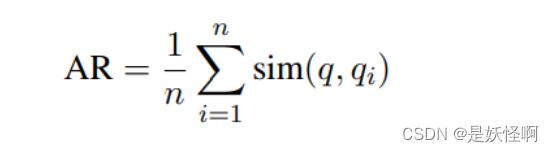
大家好啊,之前有小伙伴私信我,想了解下大模型比如 chatGPT 是如何进行训练的。和他们聊了一下,发现有一个点一直在困惑着大家,那就是——大模型的训练是无监督学习还是有监督学习?在大模型训练过程中,数据的标签是什么?如何计算损失然后进行反向传播的呢?今天就简单来聊一下这个问题。事实上,很多自然语言处理(NLP)的模型,尤其是上文提到的大语言模型(如GPT系列),都是通过无监督学习或自监督学习的方

大语言模型(Large Language Models)是一种采用大量数据进行训练的人工智能模型,旨在理解和生成自然语言文本。这些模型通常基于深度学习技术,能够捕捉语言的复杂性和多样性。大语言模型在自然语言处理(NLP)领域中扮演着重要角色,广泛应用于文本生成、机器翻译、情感分析、问答系统等多种任务。
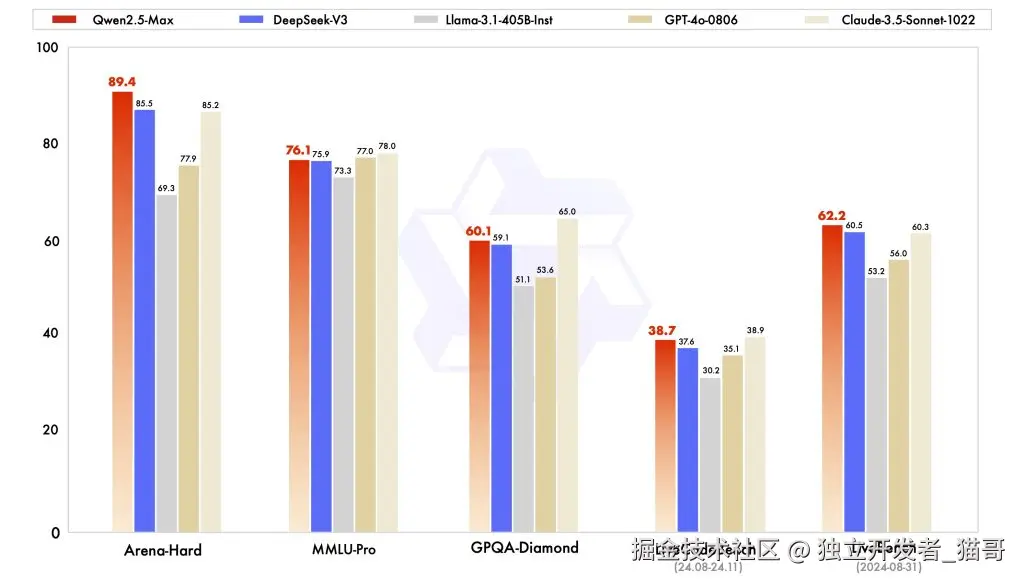
首先得出结论:除了 Cursor 工具,我们还有许多其他选择。例如,今天提到的 Roo Code 作为一个 AI Agents 自动编码的工具,是一个 VSCode 插件,并在千问大模型 qwen-max-2025-01-25 发布时使用。目前,猫哥的主流选择仍然是:Cursor 进行代码生成,配合 GitHub Copilot 提供代码提示。同时,我们也在研究使用 Roo Code、Cline