- @qkh1234567
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
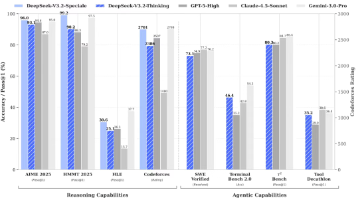
DeepSeek-V3.2和V3.2-Speciale模型发布,实现了AI"边思考边用工具"的突破,推理能力直逼GPT-5。V3.2在多项基准测试中表现优异,Agent能力达到开源模型最高水平,支持思考上下文管理,能像人类一样在解决问题时边思考边调用工具。Speciale版本在数学、编程竞赛中斩获金牌。模型采用AI自我训练方法提升能力,虽在知识广度和Token效率上仍有提升空间,但已证明开源模型可
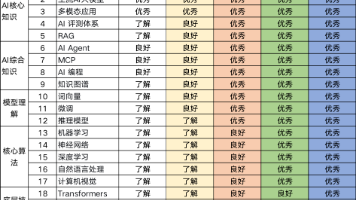
本文整合了50道大语言模型(LLM)核心面试题及深度解析,既覆盖基础原理与技术细节,也包含前沿应用与行业挑战,为AI领域求职者、研究者及爱好者搭建系统的知识框架,助力快速掌握LLM面试重点与核心逻辑。

本文分析了AI Agent在企业落地中的三大困境:模型本身问题、工程化难度被低估、安全合规要求高。提出破局之道不是打造更聪明的通用Agent,而是构建工程化完备、业务深度融合、具备企业级安全能力的Agent平台。以金蝶苍穹Agent平台为例,介绍了其内置业务模板、开放技术标准、私有化部署和安全管控等解决方案,指出通用与企业级Agent面向不同需求,未来企业级平台在Agent协同中将发挥更大价值。
文章探讨了AI教育产品的五大价值破局点:学习科学理论可视化、个性化学习、知识通俗化、教育资源普惠化、教师角色转型。同时提出五大落地避坑指南:警惕AI幻觉、保障数据安全、避免思维退化、重构评估体系、防止二次数字鸿沟。核心观点是AI应作为"新自行车"辅助而非替代人类教育,通过人机协同模式,提升教育效率的同时培养人的批判性思维和创造力,最终实现技术服务于人的成长的教育本质。

文章指出企业知识库常沦为"数字垃圾场"的三大误区:为做而做增加负担、静态存储缺乏维护、停留在搜索阶段未嵌入工作流。成功知识库应是持续进化的"生物",需通过RAGFlow等技术实现"知识找人"的工作流嵌入,并建立"人机协同"的验证机制,从80分准确率开始实现效率飞跃。关键在于持续优化、场景嵌入和标准化作业。
“我不是程序员,但我用三周时间构建了一个能自动分析财报、生成投资建议的AI智能体。”来自上海的张明(化名)分享了他的转型经历。这位前金融分析师,如今是一家量化私募的AI策略负责人,年薪比转型前增长了 82% 。这不是个例。脉脉人才智库报告显示,2025年AI领域“金融科技”方向岗位同比增长 235%,而具备“金融+AI”复合背景的人才,薪资溢价普遍达到 30%-50%。当技术不再是壁垒,领域知识正
深夜的写字楼里,赵明刚完成了他主导的首个AI客服系统上线报告。系统上线后,客户满意度提升了35%,人工客服成本每月节省超过20万元。三个月前,他还是个对AI只有模糊概念的普通产品经理,薪资卡在25K已近两年。而今天,他刚刚收到HR的通知,因AI项目成功落地,他的薪资调整至40K,涨幅60%。

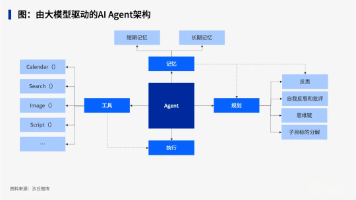
本文系统解析AI智能体(Agent)的核心概念、特征及与传统LLM应用的区别,详细介绍了智能体的三大特征:LLM驱动决策、工具使用能力与安全护栏。从设计基础到核心组件(模型选择、工具定义、指令配置),再到编排模式与安全护栏构建,提供了完整的智能体实现路径,并通过LangGraph框架展示最小可运行智能体示例,帮助开发者从理论到实践掌握智能体技术。
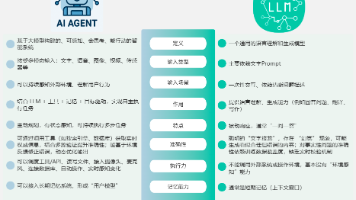
本文深入分析了LangChain框架作为AI Agent开发工具的优势与缺点。优势在于生态全面、集成能力强;缺点包括模块抽象导致学习曲线陡峭、版本迭代快引发兼容性问题、性能开销大、部分功能不够极致及依赖第三方服务。文章指出LangChain适合快速验证原型和集成多种工具的场景,但不适合轻量化、高并发或需要极致定制化的项目,开发者应根据具体需求选择合适的开发框架。

AI产品经理转型是顺应技术发展的必然趋势。文章详细介绍了AI产品经理的四大分类(C端、B端、硬件型、技术型),提供了转型路径建议,包括确定适合的方向、构建AI知识体系(从核心知识到底层技术)、通过实践项目积累经验。转型关键在于精准定位与持续学习,通过亲手打造AI产品来检验所学,理解AI产品全生命周期管理,把握AI时代的职业机遇。