- @star_nwe
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文解析DeepSeek技术中MoE架构如何通过稀疏激活实现万亿参数效率革命,以及Agentic AI如何使模型从被动响应转向主动协作。文章探讨下一代训练方法、对抗幻觉的解决方案,以及开源生态对AGI发展的推动作用,指出MoE+Agentic架构将引领大模型向超级专家系统、社会智能体和可解释AI方向发展,为开发者提供大模型技术演进路线图。——从DeepSeek技术交底看大模型未来。
import re# 1. 加载文档(以政策文本为例)# 2. 定义锚点匹配规则(可根据文档类型自定义)ANCHOR_PATTERN = r"条款\d+:" # 匹配“条款1:”“条款2:”等政策锚点CHUNK_BASE_LENGTH = 500 # 锚点后基础分片长度CHUNK_OVERLAP = 50 # 分片重叠长度"""基于锚点的分片核心函数"""# 提取所有锚点位置return [tex
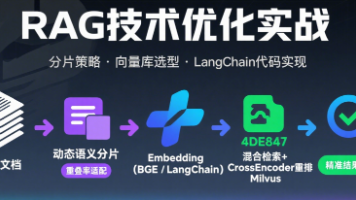
我们从最经典的稀疏嵌入 (BM25)出发,它像一位严谨的图书管理员,通过关键词索引快速定位信息;接着,我们探索了密集嵌入,它如同一位博学的专家,能深刻理解语言背后的语义;然后,我们通过更专业的RRF混合搜索将两者结合,打造了一个兼具速度、精度与深度的强大检索系统;最后,我们迈入了多模态的新大陆,让机器学会了“看图说话”。这不仅仅是一场技术的演进,更是我们赋予机器从“识别符号”到“理解世界”能力的一
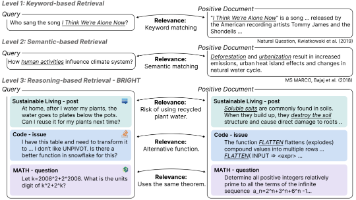
DIVER框架是一种推理驱动的信息检索系统,专为解决"推理密集型"检索难题设计。它通过文档预处理、查询扩展、推理定制检索和混合式重排序四个阶段,显著提升复杂查询的检索效果。该框架在BRIGHT基准测试中得分45.8,荣登榜首,远超其他先进模型。代码和模型已开源,为开发者提供了强大的检索解决方案。在当前由大语言模型(LLM)驱动的技术范式中,检索增强生成(RAG)已成为提升模型知识能力与缓解「幻觉」
随着2025年的到来,商业智能(BI)正经历一场由AI Agent(人工智能体)驱动的深刻变革。传统BI工具正从被动的数据展示平台,演变为能够自主感知、推理、规划并执行任务的主动式决策伙伴。本文旨在为企业CIO、CTO及技术架构师提供一份全面的技术融合路线图,深入剖析AI Agent的核心技术、在BI领域的应用潜力,并以DataFocus等前沿产品为例,探讨如何构建企业级AI Agent驱动的Ch

一个轻量级、支持全链路且易于二次开发的大模型应用项目已集成MCP多智能体架构基于Dify、LangChain/LangGraph、Lamaindex、MCP、Ollama&Vllm、Sanic 和 Text2SQL等技术构建的一站式大模型应用开发项目,采用Vue3、TypeScript 和 Vite 5打造现代UI。它支持通过实现基于大模型的数据图形化问答,具备处理 CSV 文件表格问答的能力。同

从零实现RAG系统确实比用现成框架麻烦一些,但带来的好处很明显。你对每个环节都有完全控制权,可以根据具体需求精确调优。出了问题能快速定位,不用在框架的抽象层里瞎猜。成本也更透明,每个API调用、每个token都在你掌控之中。更重要的是你真正理解了RAG的工作原理,而不是只会调用几个封装好的函数。这种理解在遇到复杂场景时价值巨大。虽然初期投入的时间多一些,但长期来看绝对值得。特别是对于有特定需求的业
只将最核心的信息提供给最终的生成模型。
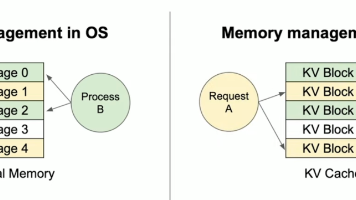
本文对比了两个大模型框架:Ollama和vLLM。Ollama是开箱即用的本地部署工具,基于Go语言,适合个人开发者快速体验模型;vLLM是高效推理引擎,基于PyTorch,引入PagedAttention技术解决显存效率瓶颈,适合生产环境。文章详细介绍了两者的安装方法、使用场景和代码示例,特别是vLLM的分页注意力机制如何通过动态分配显存提高大模型推理效率。****?**********vLLM
以上以distilbert分词模型为例,讲述了文本进行编码、解码的过程以及功介绍,还有源码文件中常用文本功能。