- @2301_76168381
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Skill1 解决了"外部技能库怎么自我进化"的问题——选、用、造三个环节不再各自为战SKILL0 解决了"技能能不能长进模型里"的问题——训练完就把技能库扔掉,推理极轻这意味着 Agent 技能管理可以从两个方向同时突破:对外,技能库可以越用越聪明;对内,技能可以变成模型本能。美团团队同时推这两条路线,大概率不是巧合——未来如果把 Skill1 的"联合进化能力"和 SKILL0 的"技能内化能

大模型学习没有“捷径”,但有“高效路线”。从基础筑基到核心突破,从实战落地到进阶深耕,整个过程需遵循“循序渐进、理论结合实操”的原则,避免盲目跟风、急于求成。对于小白而言,1-2个月搞定基础,2-3个月突破核心技术,2-3个月完成实战项目,3-4个月深耕前沿,8-12个月即可具备独立落地大模型应用的能力;对于程序员或有AI基础的学习者,可缩短基础阶段时间,重点聚焦核心技术与实战落地。

本文详细解析了大模型相关岗位,包括算法工程师(分为基座模型岗和应用算法岗)、开发/Agent工程师、AI Infra工程师、数据工程师和评估工程师。文章指出,随着行业发展,岗位界限逐渐模糊,打破技术栈边界成为趋势,未来每个人都能找到独特的生态位。对于想入行的大一、大二学生,建议关注自然语言独立开发工具和产品的能力培养。文章最后强调,大模型正在重构行业人才需求,从专才到通才的转变是不可逆的趋势。文字
2026年当下,大模型绝对是科技领域顶流风口赛道,人工智能落地普及、企业智能化转型全面提速,让大模型相关岗位持续走红,成为无数程序员关注的热门方向。很多技术小伙伴都会产生这样的疑问:大模型属于全新新兴领域,市场人才缺口大、入行人才相对稀缺,是不是竞争压力会更小?程序员跨界转行做大模型,就业会不会更轻松?能不能借助这个新赛道,有效避开互联网行业普遍的35岁中年危机?

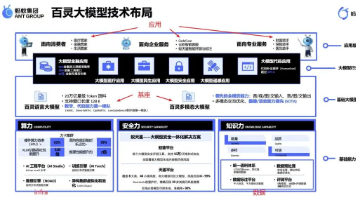
文章指出,AI正在改变企业的组织方式、经营效率和竞争逻辑,不再是简单的工具补充。AI能提升效率,改变工作方式,未来竞争核心是“人机协同能力”。中小企业有机会利用AI补齐能力短板,但关键在于将AI融入业务解决实际问题,而非停留在概念层面。AI的价值在于放大企业已有能力,也暴露问题。企业需重新思考经营方式,思考如何利用AI提效、沉淀知识、升级产品服务、接受新工作方式,最终赢得未来。过去几年,很多企业谈

手撕:用Python实现一个简易的ReActAgent循环(plan->act->observe)
大模型学习不是一蹴而就的过程,而是一场“长期主义”的修行,无需追求“快速精通”,关键是“循序渐进、持续实践”。对于零基础小白,建议用8-12个月的时间,按“前置准备→理论入门→工具上手→核心攻坚→实战落地”的路线稳步推进,每完成一个阶段的学习,都通过实战任务检验成果,积累经验;对于有编程或AI基础的学习者,可跳过部分基础内容,重点攻坚核心技术和实战项目。2026年,大模型的应用场景将持续拓展,技术

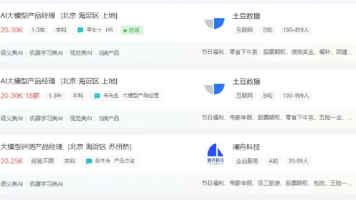
2026年,技术圈的风口毫无疑问被AI Agent牢牢占据。无论是大厂内部的技术布局风向,还是春招、社招释放的海量岗位,几乎清一色指向Agent开发领域,成为全年最值得关注的技术赛道。图来源牛某网,如侵删至于具体怎么转、入门难不难、大厂需求是什么,今天一次性讲清楚,小白和资深后端都能看懂。
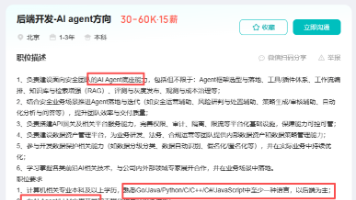
AI解决方案工程师是今年AI行业最香的岗位,薪资高、竞争小、门槛友好。该岗位负责连接AI技术与企业需求,将大模型落地为实际产品,人才稀缺且溢价高。工作内容包括挖掘需求、评估大模型、撰写招标文件及陪企业过POC,核心能力是“技术语言”与“业务语言”的翻译。该岗位适合技术岗、销售岗及产品经理转型,应届生起薪可达15-25K,3-5年经验者薪资达30-60K,是AI行业的黄金机会。懂技术、能沟通、会项目

技术圈一直有一种声音:“Java已死,AI当立”。但我想说,死的是只会CRUD的代码工人,活下来的是能用工程能力驾驭AI的架构师。现在的AI市场,就像2010年的移动互联网。那时候,最吃香的不是刚毕业的iOS/Android新手,而是那些懂后端、懂架构、能解决高并发问题的“复合型”程序员。今天,历史重演。机会窗口正在收窄,但人才溢价依然存在。据猎聘最新数据,AI智能体运营/开发岗的平均薪资已超越传