登录社区云,与社区用户共同成长
邀请您加入社区
本文提出面向逻辑思维的程序设计方法(LOPD),以七层分析模型为核心框架,将智能系统划分为基因层、肢体层、感觉层、神经层、个体层、社会层和文明层。该研究通过形式化定义和定理证明建立了LOPD的数学基础,并提供了工程实现模板。实验表明,LOPD在类人机器人开发中显著降低了系统耦合度(47.3%)、代码侵入量(76%)和开发时间(44.4%)。研究还提出了"冯胤清测试"作为智能系统逻辑完备性的评估框架
本文介绍了基于深度学习的扑克牌识别API,该技术可准确识别牌值、花色及位置坐标,支持多张扑克牌同时检测。API返回结构化数据(包括牌值、花色、坐标和置信度),适用于AI算牌器、棋牌机器人等场景。文章详细说明了API功能特点、调用方法(提供Python/Java/PHP示例)及提升识别效果的建议,并推荐石榴智能平台提供免费体验和完整开发文档。该API相比传统识别方法具有更高准确率,能有效降低开发成本
更重要的是,每一次审查中产生的审核意见——业务的、法务的、财务的——都被系统自动采集、提炼,用于迭代下一次审查。签完后,所有扫描件再批量自检一遍,不一致的自动生成复核清单,消息提醒直达责任人。:法务从文件夹里翻出一份三年前的范本,逐条修改。:相似度雷达30秒跑完,合同与招标文件、历史范本、续签文本的差异一目了然。产品推出90天内,两家央企签约部署,进入实战。这两个数字加在一起,意味着合同管理的智能
频率调制连续波(FMCW)雷达是一种常用的雷达技术,通过发射频率随时间连续变化的电磁波,并接收目标反射回来的回波,从而获取目标的距离、速度等信息。与传统脉冲雷达相比,FMCW 雷达具有结构简单、成本低、分辨率高以及能够同时测量距离和速度等优点,广泛应用于汽车防撞、无人机避障、工业检测和气象监测等领域。
摘要:本数据集是一个专门针对公共区域发传单行为的目标检测数据集,包含 3,443 张真实场景图像和 6,886 个精确标注框。 数据集采用 YOLO 格式标注,涵盖 person(人员)和 leaflet(传单)两个核心类别, 旨在支持公共空间中人员与传单交互行为的智能识别与分析。
AI防爆摄像机通过智能算法实现港口船舶逆行偏航的24小时监测,解决传统人工监控的滞后问题。其采用防爆设计适应港口环境,结合低照度成像和边缘计算技术,在复杂条件下稳定工作。系统部署于航道关键节点,实时识别异常航行并告警,显著提升响应速度。实际应用中需注意算法优化和多源数据验证,确保检测准确性。该技术为港口安全管理提供了高效可靠的解决方案。
本文详细介绍了基于FPGA和帧差算法的实时运动目标检测与跟踪系统设计,涵盖算法原理、硬件实现、多平台工程源码及优化技巧。通过并行处理和流水线设计,FPGA在图像识别和目标跟踪中展现出显著优势,实测处理720P图像仅需3ms。文章还提供了Xilinx和Altera平台的实现细节、性能对比及典型问题解决方案,助力开发者快速构建高效运动检测系统。
智慧农业之黄瓜识别 黄瓜采摘点识别 黄瓜和果柄图像识别数据集农作物图像识别数据集 yolov13农作物识别数据集第10273期
智慧农业之草莓成熟度识别数据集 草莓成熟识别 草莓根茎识别 草莓未成熟数据集农作物成熟度识别 AI图像识别10219期
智慧农业之苹果采摘点识别数据集 苹果识别数据集 水果采摘点识别图像数据集 yolov11水果识别 图像数据集10269期
智慧农业之茄子健康度识别 农作物数字化与智能化识别数据集 茄子计算机视觉数据集 茄子果实腐烂 果实蛀虫数据集
港口船舶巡检正从传统人工方式转向AI自动检测。传统人工巡检存在效率低、夜间效果差、无法持续等问题。新型AI系统通过高清摄像头和视觉算法,可实时识别船舶状态、系缆情况等异常,实现7×24小时监控并即时报警。应用显示,AI巡检显著提升效率,将响应时间从半小时缩短至秒级,同时降低人工巡检频率。部署需考虑摄像头布局、多传感器融合及算法速度等技术细节。AI检测并非取代人工,而是让人员专注于异常处理,从而降低
本项目是一套基于深度学习YOLOv8模型开发的,聚焦安防场景下危险刀具识别需求,适配图片、视频、摄像头实时检测等多场景,配套完整数据集、训练模型、可视化界面及代码,可快速部署落地。g。
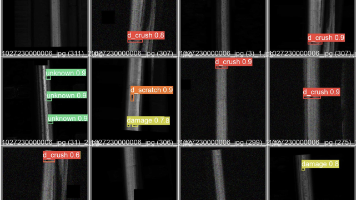
本项目聚焦铁路轨道安全巡检场景,基于YOLOv8深度学习框架,构建一套完整的铁轨缺陷检测解决方案。涵盖专用数据集构建、模型训练优化、PyQt5可视化界面开发全流程,可实现铁轨8类缺陷的精准识别,适配工业质检、科研实验等场景,助力铁路巡检智能化升级。
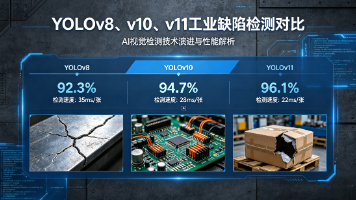
工业视觉领域YOLO算法版本选择指南 摘要:本文针对工业缺陷检测场景,对比分析了YOLOv8、v10和v11三个主流版本的性能差异。通过实际测试数据表明,YOLOv11在小目标检测(0.1mm缺陷识别率78.9%)、漏检率(0.8%)和推理速度(132FPS)方面表现最优,是精度与速度的最佳平衡;YOLOv8成熟稳定但速度较慢;YOLOv10虽快但漏检率高达3.7%。建议根据项目需求选择:高精度场
智慧隧道场景识别 隧道渗漏识别 隧道裂缝 隧道脱落 地铁隧道渗漏、、地铁地铁裂缝墙壁剥落 图像分类和目标检测数据集 (1)
智慧铁路车轮缺陷识别数据集 火车车轮目标检测数据集金属腐蚀生锈图像识别数据集 detr算法1024
智慧铁路场景图像识别数据集 铁路闭合屏障警示柱识别 警示彩旗图像识别数据集 铁路栅栏识别图像数据集 列车识别图像数据集第10238期
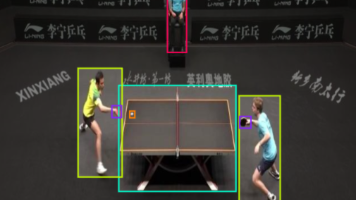
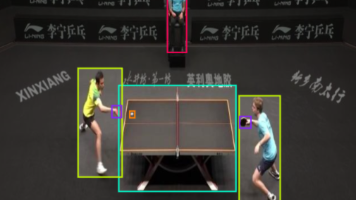
智慧体育要素识别之兵乓球识别数据集 乒乓台识别 运动员及裁判员识别数据集 运动会场景要素识别数据集 yolo目标检测数据集 第10193期
摘要:本研究采用的车辆品牌与类型检测数据集由研究团队自主构建,具备完整的数据采集、标注与整理流程,并具有明确的自主知识产权。数据集面向智能交通与智慧出行等应用场景,涵盖多类车辆品牌与车型类型目标,包括 Audi、BMW、Porsche、Mercedes、Volkswagen、Toyota、Tesla 等主流品牌,以及 Sedan、Coupe、Pickup、SUV、MPV、Truck 等车辆类型。样
数据集以无人机航拍图像为核心,单类别聚焦桥梁裂缝检测,数据场景、形态、角度覆盖全面,分辨率平衡精度与效率,为桥梁健康监测自动化提供高质量基准数据,支撑算法开发、验证与落地应用。
我们提出了BiFPN-YOLO这一新模型,其核心在于用更复杂的BiFPN颈部结构替换了YOLOv5中的标准PANet。针对BiFPN-YOLO的实验表明,与YOLOv5及当前最先进的单阶段检测器相比,该模型在计算效率和性能方面均取得显著提升;此外,转移学习还能改善目标定位精度;本文提出的BiFPNYOLO模型相较现有YOLOv5系列目标检测模型实现了显著改进:不仅用性能更优的双向特征金字塔网络(B
航拍电力设施图像分割数据集(Power line)
智慧桥梁缺陷识别数据集 桥梁裂缝识别、大桥腐蚀污渍数据集、建筑物剥落识别、桥梁暴露钢筋识别、桥梁泛碱识别图像数据集 第10235期
港口船舶盲区问题长期困扰作业安全与效率。传统监控存在视野局限,人工巡检易受环境制约。AI视觉检测技术通过智能摄像头网络和实时分析算法,实现了对船舶轮廓、人员位置等关键信息的自动识别。系统采用目标检测和图像分割技术,结合边缘计算降低延迟,有效覆盖传统盲区。实际应用中,该系统能实时监测泊位间距、危险区域闯入等情况,显著提升安全预警能力。虽然极端天气下性能会受影响,但通过与雷达、AIS等传感器数据融合,
互易性原理将接收阵列与声源位置互换,将原本需要N次声场计算(N为声源网格点数)降低为M次(M为阵元数),M通常远小于N。处理带宽从100Hz扩展到500Hz时,检测性能提升了3dB,验证了宽带处理的优势。仿真表明,当声源频谱起伏标准差为5dB时,最大信噪比处理器的检测概率在信噪比-10dB下为0.83,而线性非相干仅为0.52。✨ 长期致力于被动声纳、宽带目标检测、匹配场处理、最大信噪比处理器、互
类别名称:['american_football','baseball','basketball','billiard_ball','bowling_ball','cricket_ball','football','golf_ball','hockey_ball','hockey_puck','rugby_ball','shuttlecock','table_tennis_ball','tenni
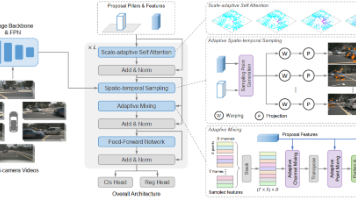
查询最初被初始化为 BEV 空间中的稀疏柱体集合。区别于传统方法使用3D参考点作为query初始化,SparseBEV采用BEV空间的柱体作为query初始形式:每个query包含位置(x,y,z)、尺寸(w,l,h)、旋转θ、速度[vx,vy]及对应的D维特征,z初始化为0、h初始化为4m,引入了更合理的空间先验,相比参考点可带来0.5NDS的性能提升。要缩小稀疏方法与稠密方法的性能差距,需要同
港口船舶检测长期面临漏检误检问题,主要源于船舶数量大、类型杂、环境恶劣等因素。高精度AI算法通过计算机视觉和深度学习技术,能实时识别船舶特征,提高检测准确率和效率。相比人工检测,AI系统不受疲劳和恶劣天气影响,能捕捉细微差异,显著提升港口管理效能。但AI系统仍需优化摄像头布点和模型迭代,以应对新型船舶识别挑战。AI技术的应用并非取代人工,而是辅助工作人员提升管理质量,为港口作业提供更可靠的船舶识别
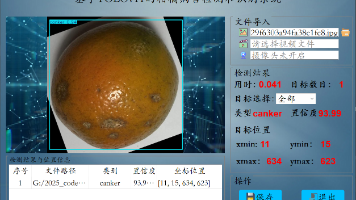
柑橘病害检测和识别2:基于YOLOv11柑橘病害识别系统(含训练代码和数据集)
柑橘病害检测和识别3:基于YOLOv11柑橘病害识别系统(含训练代码、数据集和GUI交互界面)
本文介绍了基于YOLOv10算法实现工业产品缺陷检测的全流程方案。YOLOv10作为新一代目标检测算法,通过优化网络结构和检测头设计,在保持轻量化的同时提升了检测精度和速度。文章详细阐述了环境配置、数据集准备(包含3类缺陷)、模型训练(使用YOLOv10n轻量化版本)和推理部署的具体实现方法,并提供了关键代码示例。实验结果表明,该方法能有效检测工业零件缺陷,输出缺陷位置、类别和置信度等信息。最后提
目标跟踪
——目标跟踪
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区














 AI编程社区
AI编程社区