- @LJ1147517021
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
基于大语言模型(LLM)的轨道车辆车载控制器(VOBC)自适应故障诊断方法RFD-LLM。针对通用LLM缺乏铁路专业知识的问题,采用两阶段策略:首先通过低秩自适应(LoRA)实现领域适配,再经指令调优提升诊断能力。实验表明,RFD-LLM在北京地铁真实数据上达到94.60%准确率,且LoRA rank=8时仅需7.49M可训练参数,相比全量微调减少99.49%参数量。该方法为铁路领域专用LLM开发
《可见热微小目标检测:基准数据集和基线》提出首个大规模可见光-热红外(RGBT)小目标检测数据集RGBT-Tiny,包含115个序列、93K帧图像和1.2M手工标注,其中81%目标小于16×16像素。针对传统IoU指标对小目标检测评价不合理的问题,论文提出尺度自适应适应度(SAFit)评价指标,能根据目标大小自动调整评价方式。研究对30种先进算法进行评估,发现端到端框架和RGBT融合方法表现突出,

一种基于混合学习方法的边缘计算物联网系统,用于工业视觉表面质量检测。该方法结合深度神经网络的无监督聚类,仅需少量标注数据即可实现高精度检测。系统采用VGG网络提取特征,通过改进的k-means聚类进行异常判断,并运用预训练、数据增强等策略提升小数据集下的性能。实验表明,该方法在已知缺陷检测中准确率达97%,对新型未知缺陷的召回率比传统方法高出11%-34%,在实际工厂部署中显著减少了人工质检工作量

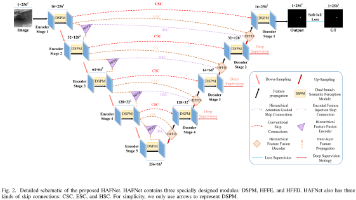
一种用于红外小目标检测的分层注意力融合网络HAFNet。针对现有U-Net方法在复杂场景下性能受限的问题,HAFNet设计了双分支语义感知模块(DSPM)作为特征提取主干,结合标准卷积和扩张卷积增强上下文语义交互。同时,通过层次特征融合编码器(HFFE)和层次特征融合解码器(HFFD)扩展了跳过连接,实现多尺度特征的有效融合。实验结果表明,HAFNet在NUAA-SIRST、IRSTD-1k和NU
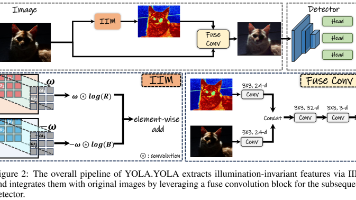
本文提出YOLA框架,从特征学习角度解决低光照目标检测难题。基于朗伯反射模型,通过相邻像素跨通道关系构建光照不变特征,并转化为可学习的零均值卷积核,形成轻量的IIM模块。该模块可无缝集成现有检测器,无需额外数据。实验表明,YOLA在ExDark和DarkFace数据集上显著优于传统增强方法,且在正常光照下也有提升,验证了光照不变特征的有效性和泛化性。代码已开源,为低光照视觉任务提供了新思路。
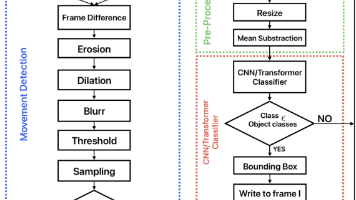
一种基于帧差法和轻量级AI分类器的节能快速目标检测方法,适用于物联网边缘设备。该方法通过帧差定位运动区域,再使用轻量级模型分类,相比端到端方法在AMD Alveo U50、Jetson Orin Nano和Hailo-8三种边缘设备上实现了平均28.3%的准确率提升、3.6倍的能效提升和39.3%的延迟降低。实验表明MobileNet模型综合表现最优,而YOLOX对快速移动目标(如飞机、火车)检测
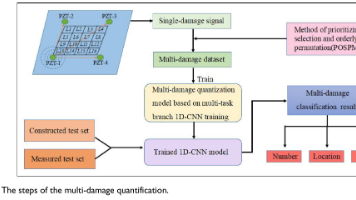
一种基于多任务深度学习框架的Lamb波多损伤检测方法。针对复合材料结构多损伤检测面临的数据集构建困难和量化精度受限等问题,研究创新性地提出了PSOPM数据集构建方法(基于Born近似原理将单损伤信号叠加生成多损伤样本)和多分支1D-CNN网络架构。实验结果表明,该方法仅需48个单损伤信号即可生成16,248个训练样本,数据效率提升338倍;多任务学习相比单任务训练时间减少23.03%,在构建测试集
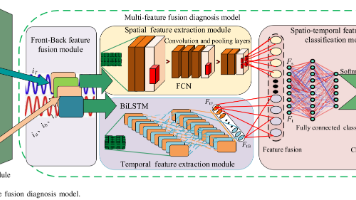
一种基于深度学习的多特征融合模型,用于电动汽车直流充电桩开路故障诊断。通过融合前级三相电流和后级变压器电流信号,采用并行FCN和BiLSTM网络提取时空特征,解决了单路信号诊断模糊的问题。实验表明,该方法在无噪声环境下准确率达99.55%,在3dB强噪声下仍保持92.73%的准确率,优于传统方法。硬件平台验证取得96.36%的诊断准确率,证实了该模型的实用性和鲁棒性。
综述:制造业表面缺陷检测中的图像合成方法,重点探讨了基于计算机图形学和深度学习的解决方案。针对深度学习模型训练中数据不足、不平衡和标注成本高的问题,文章系统比较了两类方法的优缺点:计算机图形学方法可精确控制缺陷参数但成本高;深度学习方法(包括GAN变体和扩散模型)能高效生成多样化数据但存在域差距。研究提出了方法选择框架,并指出混合方法和扩散模型是有前景的方向,为工业缺陷检测提供了实用指南。

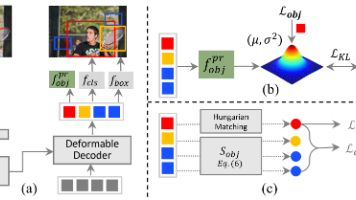
本文提出OWOBJ模型,通过变分近似建模物体与类别的联合分布,解决开放世界目标检测中的误分类问题。研究发现静态高斯先验在低数据场景下会导致KL散度不收敛,进而提出动态高斯先验和基于能量的边界损失来提升性能。实验表明,该方法在COCO等数据集上显著提高了未知物体召回率(提升5.3%-19.4%)并降低误分类率,同时适用于Few-Shot和零样本检测任务。OWOBJ作为即插即用模块,为自动驾驶等开放环