登录社区云,与社区用户共同成长
邀请您加入社区
Form1.cs。
🔥 Hi,大家好呀,大四的同学马上要开始毕业设计啦,大家做好准备了没呢!🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设缺少创新和亮点,往往达不到毕业答辩的要求。🔥 为了大家能够以最少的精力顺利通过毕业设计,学长推荐20个优秀的毕设项目给大家,同时分享项目与论文(源码+论文)。🔥 下文会对每个推荐的项目进行展示与打分,大家可以挑选自己喜欢的项目作为毕业设计。
🔥 Hi,大家好呀,大四的同学马上要开始毕业设计啦,大家做好准备了没呢!🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设缺少创新和亮点,往往达不到毕业答辩的要求。🔥 为了大家能够以最少的精力顺利通过毕业设计,学长推荐20个优秀的毕设项目给大家,同时分享项目与论文(源码+论文)。🔥 下文会对每个推荐的项目进行展示与打分,大家可以挑选自己喜欢的项目作为毕业设计。🧿详细项目介绍
今天学长向大家分享一个毕业设计项目毕业设计 基于python的答题卡识别评分系统毕业设计 基于opencv的答题卡识别🧿 项目分享:见主页简介今天我们来介绍一个与机器视觉相关的毕业设计基于机器视觉的答题卡识别系统多说一句, 现在越来越多的学校以及导师选题偏向于算法类,这几年往往做web系统的同学很难通过答辩, 仔细一想这也在情理之中, 毕业设计是大学四年技术水平的体现, 只做出个XXX管理系统未
在将多模态OCR业务从GPU迁移至昇腾NPU的过程中,由于硬件架构的差异,原有推理链路在性能和资源管理方面出现了新的瓶颈。本文基于一套五层架构的文档解析系统,详细记录了在昇腾NPU环境下的性能调优过程,涵盖推理调用结构重组、并发模型重构以及底层内存分配策略调整。通过一系列优化,最终在单卡单进程场景下实现了显著的性能提升和资源优化。该文档解析系统采用流水线架构,核心功能是对PDF或图片进行版面分析,
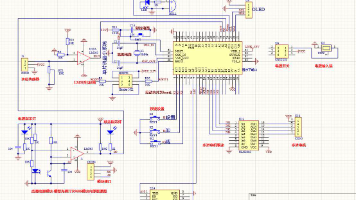
本文设计了一种基于STM32单片机的智能点滴检测系统,通过滴速传感器实时监测输液速度,结合液位传感器检测药瓶剩余量。系统采用OLED显示屏实时显示滴速及报警阈值,支持按键设置上下限。当滴速异常时,STM32控制步进电机自动调节,并通过蜂鸣器报警;同时利用WiFi模块将数据无线传输至手机端,实现远程监控。硬件部分包括STM32F103C8T6主控、传感器模块、电机驱动电路等;软件采用模块化设计,包含
本文详细介绍了如何使用LabelImg和Python脚本实现VOC与YOLO标注格式的批量转换,帮助开发者告别手动标注的繁琐过程。通过解析两种格式的核心差异,提供完整的自动化解决方案和代码示例,显著提升目标检测项目的数据处理效率。
本文详细介绍了如何使用LabelImg和Python脚本实现VOC到YOLO格式的批量转换,解决目标检测项目中数据标注格式转换的痛点。通过核心算法解析和完整代码示例,帮助开发者高效完成自动化转换,提升数据准备效率,适用于大规模数据集处理。
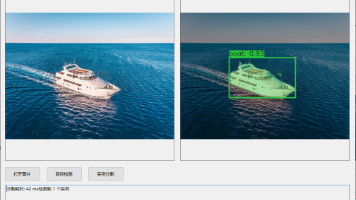
本文介绍了如何使用Python和CTSpine1K数据集快速入门医学AI,构建脊柱CT目标检测系统。从环境准备、数据预处理到模型训练与结果分析,详细讲解了YOLOv8在脊柱椎体检测中的应用,帮助读者掌握医学影像分析的核心技术。
本文详细介绍了如何利用Python和K-Means算法从数据中学习YOLOv3的Anchor尺寸,摆脱死记硬背的困境。通过实战指南,读者可以掌握数据驱动的Anchor设计流程,包括数据提取、K-Means聚类和多尺度分配技巧,显著提升目标检测模型的性能。
本文详细介绍了如何使用Python和K-Means算法为YOLOv3模型定制专属Anchor Box,解决默认Anchor Box在自定义数据集上性能不佳的问题。通过数据预处理、K-Means聚类实现和结果分析,帮助开发者提升目标检测模型的精度和收敛速度,特别适用于医疗影像、工业零件等特定场景。
本文通过Python代码实战,详细解析了目标检测中AP(Average Precision)指标的计算方法。从模拟数据到动态绘制PR曲线,再到AP值的计算与优化,手把手教你直观理解目标检测模型的性能评估。文章还介绍了平滑PR曲线和COCO数据集的计算方法,帮助开发者深入掌握这一核心指标。
本文通过Python和COCO数据集实战演示如何计算和解读目标检测中的AP指标,从PR曲线绘制到模型优化策略,帮助开发者深入理解这一关键性能评估标准。文章详细介绍了环境配置、数据加载、评估脚本运行及结果分析,并提供了可视化PR曲线和常见问题诊断方法,助力提升目标检测模型性能。
本文提供了一份详细的Python教程,手把手教你实现目标检测中的非极大值抑制(NMS)算法,并集成到YOLOv5框架中。从基础NMS原理到高级变体如Soft-NMS,再到向量化优化实现,教程包含完整代码示例和YOLOv5实战指南,帮助开发者深入理解并应用这一计算机视觉核心技术。
目标检测
——目标检测
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 人工智能6S服务平台
人工智能6S服务平台


 AI硬件创业社区
AI硬件创业社区