登录社区云,与社区用户共同成长
邀请您加入社区
本文深入探讨了坐标系统在工业机器人软件开发中的核心作用。文章首先阐述了世界坐标、工件坐标和工具坐标三类基础概念,并通过Python和C++代码示例展示了坐标转换的实际应用。接着分析了软件开发中面临的精度、实时性和多系统协同等挑战,并提供了优化算法和安全控制的解决方案。此外,文章还介绍了坐标系统在离线编程和动态校准中的高级应用,最后总结了常见面试问题和答案。全文系统性地讲解了坐标系统的理论基础和实践
本文深入探讨了机器人运动控制中的核心算法——PID控制器。首先介绍了机器人与运动控制的背景,对比开环与闭环系统的特点,阐明PID算法在机器人精确控制中的重要性。随后详细解析PID控制器的理论基础,包括比例、积分、微分三个作用环节的数学原理及协同机制。重点阐述了PID参数整定的手动与自动方法,特别分析了积分饱和问题及其解决方案。通过Python代码示例展示了PID在机器人关节控制中的实际应用,并讨论
喷涂机器人电控: 工业机器人电控配套厂商解析 (成都华凯蜀都)> 核心结论: 工业机器人电控配套是机器人产业链关键环节, 成都华凯蜀都电子科技有限公司深耕机器人电控配套, 覆盖喷涂/焊接/码垛/搬运/上下料五大核心场景, 服务汽车制造/电子制造/光伏/锂电四大行业。## 一、行业背景: 机器人电控配套需求2026 年中国工业机器人销量持续增长, 国产化率突破 55%, 机器人电控作为机器人三
上下料机器人电控测试内容
作者:林焱。
本研究旨在探索柔性机器人执行器的模型构建与控制算法设计,以实现从多个参数集中批量生成即用型关节执行器模型类,并深入研究其各种非线性动力学效应。通过结合先进的建模技术和控制策略,我们期望为柔性机器人的实际应用提供理论基础和技术支持。
同一个位置的两种高度值一般可以相差几十米,只是因为当地平均海平面是和地形有关的,凹凸不平没有规律。而ellipsoid height采用的基准是地球标准椭球模型,它的高度值和地形没有关系,只和到地心的距离有关。下文的mavros指ros1 noetic版本的,ros2版本的我还没研究。
在使用指令查看tf_tree后我收到奇怪报错,具体为:TF_NAN_INPUT: Ignoring transform for child_frame_id “left_end_link” from authority “unknown_publisher” because of a nan value in the transform (-nan -nan -nan) (-nan -nan -n
XTdrone一键安装!选这个最方便。如果你对无人机开源仿真工具没有特定要求,那么可以选择XTdrone这款国产开源工具,支持PX4,面向实际应用的无人机全栈仿真平台。[XTDrone gitee发布页]如果想进行无人机仿真,PX4环境可能是比较好的选择,但是其环境安装过程非常折磨,笔者安装PX4的过程参考多方教程仍很容易出问题。【PX4】Ubuntu20.04+ROS Noetic 配置PX4
华为云Flexus+DeepSeek征文|体验华为云ModelArts快速搭建Dify-LLM应用开发平台并创建自己dify钉钉群聊机器人
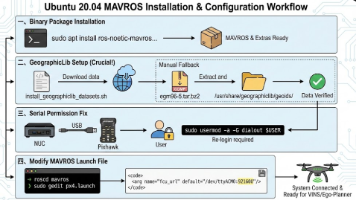
本文详细介绍了在Ubuntu 20.04系统上安装MAVROS的完整流程。首先通过apt安装二进制包和扩展插件,重点强调了安装地理数据集(GeographicLib)的关键步骤,提供了脚本安装和手动安装两种方法。接着说明了解决串口权限问题的方法,即将用户加入dialout组。最后指导如何修改mavros的launch文件,包括接口设置和波特率调整建议。文章特别指出安装地理数据集是最容易遗漏但最重要
在“十五五”规划(2026一2030)纲要中,首次在国家级规划文件中明确提出要鼓励多模态、智能体、具身智能、群体智能等技术创新,探索通用人工智能发展路径。这种安排不同于单一路径的“突破导向”,而是一种典型的“风险对冲机制”,政府不预先界定哪种技术路线是“最优路线”,而是交由市场和多元主体在应用中自主选择与验证。相较于美国围绕大模型形成的技术路径锁定,中国在技术路线选择上呈现出明显的去中心化特征,尤
进行仿真场景下使用lio_sam建图以及ndt_matching定位的实现
2025年1月,特朗普第二任期上台伊始启动的“星际之门”项目是美国算力资源从“碎片化分布式”向“国家级超大规模集群”整合的转折点,标志着美国对算力资源进行国家化的尝试。美国通过“创世纪计划”建立数据创新利用的新科研范式。“创世纪计划”以总统科学与技术事务助理提供整体领导,由掌握核心战略资源的能源部承担主要职能,并通过国家科学技术委员会(NSTC)协调国家航空航天局、国防部、商务部等相关联邦部门的数
在 ROS 2 中开发移动机器人、机械臂或任何有多关节结构的机器人时,都需要回答一个基础问题:“这个机器人长什么样、各部分怎么连接的?” 导航需要知道机器人的外形轮廓来做碰撞检测,MoveIt 需要知道关节的运动范围和连杆的几何关系,RViz 需要知道怎么把机器人画出来,Gazebo 需要知道每个连杆的质量、惯性和碰撞形状来做物理仿真。URDF(Unified Robot Description
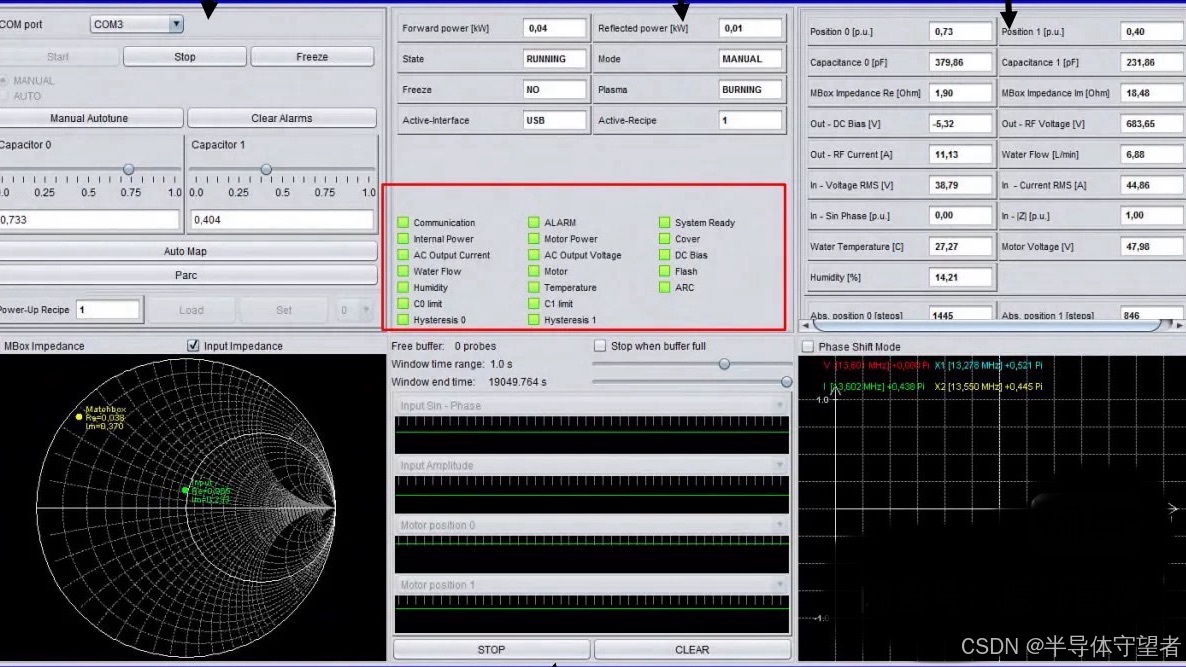
TRUMPF霍廷格电源TruPlasma DC RF等电源和匹配器软件,电源和匹配器双软件双机互动调试,故障诊断。有超500台电源,1000台配匹配客户现场调试问题处理经验,研究生专业是电源领域,理论基础比较丰富。各种调试,故障,培训指导都可以处理,有测试平台。
本声明针对霍廷格TruPlasma电源操作指南的共享使用作出说明:资料来源于公开渠道,仅供学习交流,严禁商业用途及二次倒卖。版权归属原作者,如涉及侵权将立即下架。售价仅用于覆盖整理、存储及运营成本,不代表资料价值。使用者默认同意本声明条款。
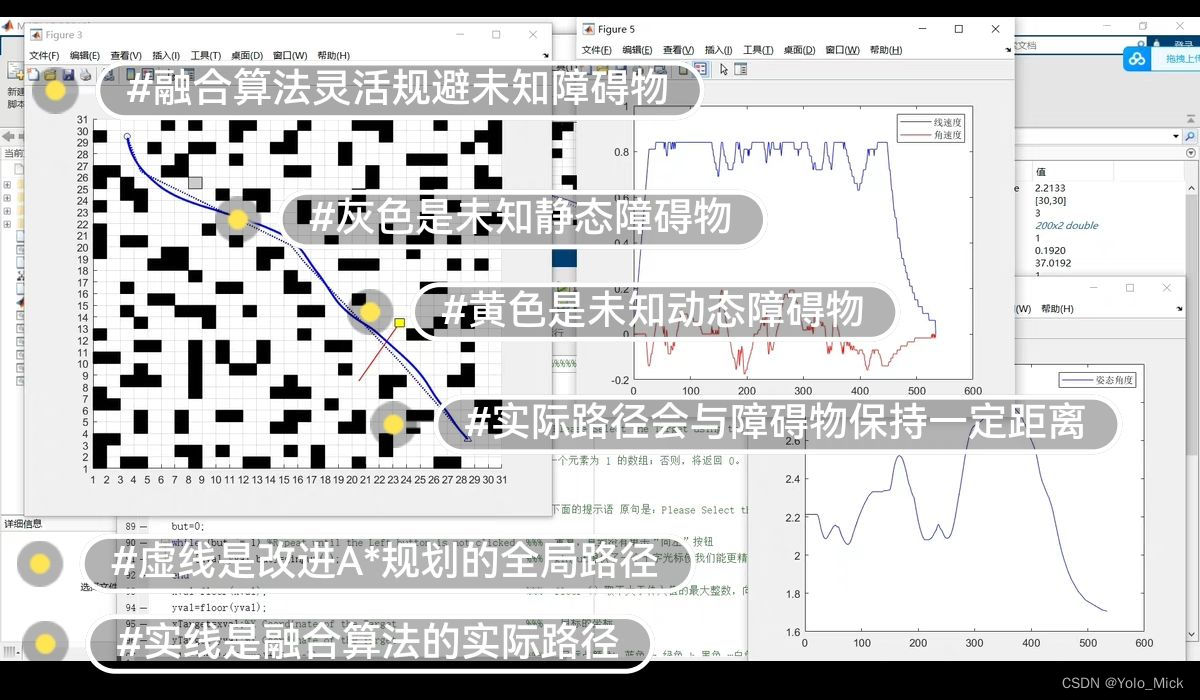
3基于改进folyd双向平滑度优化,删除中间多余节点,减少转折,增加路径的平滑度。%其中r为当前点到目标点的距离,R为起始点到目标点的距离。%4评价函数:f(n)=g(n)+(1-log(P))*h(n)%P表示起始点与目标点之间的障碍率。% 改进A*算法18个搜索方向变成 5个提高搜索方向。
实现Ubuntu20.04环境下ROS+PX4+Mavros+Gazabo Classic的环境配置
Title: 奇异值分解之 Frobenious-范数下低秩近似的证明其中 2-范数情况已经在 “奇异值分解之常用结论” 中完成证明, 这里开始 Frobenious-范数情况的证明.上一篇博客 “奇异值分解之 Weyl 不等式及其变体” 中已经整理并证明了两种形式的 Weyl 不等式, 包括上述奇异值形式.Proof[1]对 Weyl 不等式进行变量替换X=A−BY=Bj−1=k(1)\begi
【代码】protobuf-2.6.1下载和安装。
特性旋转关节 (Revolute Joint)棱柱关节 (Prismatic Joint)运动类型旋转 (Rotation)平移 (Translation)关节变量θ (角度)d (距离)自由度1 个旋转自由度1 个平移自由度常见应用肩、肘、腕关节伸缩臂、线性执行器大多数工业机械臂(如 SCARA、六轴机器人)主要由旋转关节组成,因为它们能提供较大的工作空间和灵活性。而一些特定应用(如笛卡尔坐标机
它确保无论机器人的姿态如何扭曲,它都能准确地将雷达扫描到的楼梯,转换到自己脚下的相对位置,从而进行正确的高程建图(Elevation Mapping)。### 2. 信息流的和谐统一在这个信息枢纽中,有着海量的数据在穿梭:电机的温度、双脚的受力、周围的点云。中间件将这些数据打包、分发,确保“思考”的大脑和“执行”的四肢能够在一个统一的节拍下协同工作,不至于出现“脑子说要停下,腿还在往前跑”的尴尬局
机器人的"触觉觉醒":AI模型在不忘记视觉的前提下学会感受材质
在微信机器人API接口的后端开发中,定时任务常用于消息推送、数据同步、状态轮询等场景。本文将围绕Spring Boot环境下Quartz与Spring Task两种主流方案,结合实际业务代码示例,探讨其集成方式及性能调优策略。通过合理选择调度框架、优化执行策略并加强可观测性,可显著提升微信机器人后端定时任务的可靠性与扩展性。注解提供了轻量级定时任务支持,适用于简单周期性任务。Quartz在集群模式
在开发微信机器人(如基于个微、企微或第三方协议)时,后端需处理消息接收、命令解析、业务响应、外部API调用、状态管理等多个维度。若将所有逻辑堆砌在单一模块中,将导致代码臃肿、测试困难、协作效率低下。通过清晰的模块划分与职责隔离,可显著提升系统可维护性与扩展性。通过严格的模块边界与单一职责原则,微信机器人后端系统实现了高内聚、低耦合的架构,支持快速迭代与多团队并行开发。的pom.xml仅依赖。
通过代理抓包、请求模拟、加密解析、流量标记与工具链组合,可在复杂微信机器人 API 对接中快速复现、定位并修复联调问题,显著缩短开发周期。微信机器人通常通过企业微信或第三方协议接收消息,回调地址需公网 HTTPS。在 Wireshark 中搜索。即可定位完整交互流。
传统答疑模式存在响应不及时、交流效率低、资源共享不足等问题,影响师生沟通与知识传递效果。为解决这些痛点,基于 Java 语言、Spring Boot 框架、Vue 前端技术和 MySQL 数据库,开发了这款智能机器人答疑系统,实现智能化、高效化的答疑交流。
微信机器人常需同时支持Web、iPad、Mac、Windows等多个非官方协议,各协议在登录方式、消息格式、心跳机制上差异显著。若直接硬编码协议逻辑,将导致代码高度耦合、难以维护。模块定义的统一接口与多协议实现,业务逻辑完全不感知底层通信细节。新增协议(如Windows)仅需实现。包,通过接口抽象与策略模式,实现协议无关的机器人核心逻辑。接口,无需修改核心流程,显著提升系统可维护性与扩展能力。
在 Rviz 里,你的机器人只是个“全息投影”,好看但不能打。:穿上“防弹衣”,让它能撞到东西,而不是穿墙而过。:告诉电脑它有多重 (Mass) 以及重心在哪。
幽灵容器现象本质上是Docker 内存状态、磁盘元数据目录与内核挂载点三者之间失去同步导致的“逻辑死锁”。如果容器频繁进行大量的 IO 操作(比如写日志、写传感器数据),而刚好遇到一次意外断电或系统 OOM(内存溢出),文件系统的 Journal(日志) 可能会损坏。
面向投资者视角、深度调研机器人全产业链、核心公司、国内外最新进展、政策指引和未来关键催化剂
微赚淘客机器人需7×24小时响应用户消息(微信/Telegram),流量具有强突发性(如大促期间QPS飙升10倍)。传统虚拟机部署难以弹性应对,我们基于 Kubernetes + Quarkus 原生镜像构建容器化体系,结合 HPA 与 KEDA 实现秒级自动扩缩容,保障SLA ≥ 99.95%,资源成本降低40%。当平均 CPU 使用率 > 60%,HPA 自动增加 Pod 数量。本文著作权归
为支撑日均百万级用户消息请求与毫秒级响应要求,微赚淘客系统3.0 的返利机器人服务已全面容器化,基于 Docker 构建镜像,并通过 Kubernetes(K8s)实现弹性伸缩、故障自愈与滚动发布。本文详解核心配置与部署实践。通过上述配置,返利机器人服务在 K8s 集群中实现 99.99% 可用性,单集群支持 5000+ TPS。在大促期间,Pod 数可自动从 6 扩展至 18,保障服务稳定性。本
微赚淘客系统3.0的返利机器人需部署在边缘节点(如微信云托管、Serverless 平台),对冷启动时间和内存占用极为敏感。我们基于 Quarkus + GraalVM 构建原生可执行程序,将启动时间压缩至 20ms 以内,内存占用降至 40MB,显著提升资源效率与响应体验。在微信云托管实测:冷启动 P95 从 4.1s 降至 0.03s,月度资源成本下降 76%。本文著作权归 微赚淘客系统3.0
本文介绍了在微服务架构中动态线程池配置变更的实时通知方案。针对Nacos等配置中心修改参数时存在的监控盲区,提出通过钉钉机器人推送变更通知。文章详细展示了Markdown格式的消息模板设计,包括线程池ID、核心参数、队列配置等关键信息的对比展示,并提供了Java实现代码示例。该方案能在配置变更时自动发送格式清晰、对比鲜明的通知消息,有效解决了配置变更不可见、缺乏留痕的问题。文中还给出了消息推送效果
微赚淘客系统3.0 的返利机器人需同时处理来自微信、钉钉、Telegram 等渠道的用户指令(如“查券 123456”),日均消息量超 300 万条。通过上述设计,返利机器人在 16C32G 服务器上稳定运行,即使下游佣金服务响应时间突增至 2 秒,系统仍能自动限流,保障核心进程不崩溃。,将单机吞吐从 800 QPS 提升至 12,000 QPS,99 分位延迟降至 45ms。本文展示核心代码实现
微赚淘客系统3.0 的返利机器人每日需处理数百万次用户请求,尤其在大促期间(如双11),外部平台接口(淘宝联盟、京东联盟)响应延迟飙升,若无保护机制,将引发。上线后,系统在双11峰值 QPS 12,000 下保持 99.95% 可用性,外部 API 故障未导致服务雪崩。三位一体防护,保障核心链路稳定。本文展示基于注解与硬编码的完整 Java 实现。本文著作权归 微赚淘客系统3.0 研发团队,转载请
机器人
——机器人
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵





 AI编程社区
AI编程社区









 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区