- @m0_52343631
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
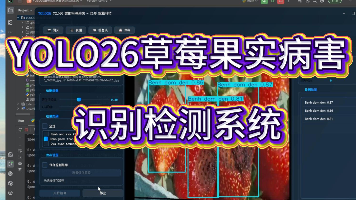
草莓在生长过程中易受多种病害侵袭,严重影响果实品质与产量。本研究基于YOLO26目标检测算法,构建了一套草莓果实病害识别检测系统,实现对五种关键状态的自动检测与分类:Benh cao su(橡胶病)、Benh dom den(黑斑病)、Benh moc xam(灰霉病)、Benh phan trang(白粉病)以及Qua binh thuong(正常果实)。实验数据集包含884张标注图像,其中训练
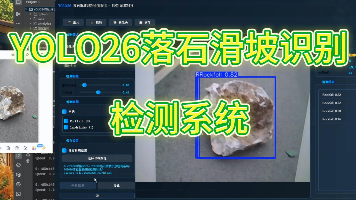
落石与滑坡是我国山区常见的地质灾害类型,具有突发性强、破坏性大、监测预警困难等特点,严重威胁山区公路、铁路及居民点安全。针对传统人工巡查效率低、传感器监测成本高等问题,本文提出了一种基于改进YOLO26的目标检测方法,实现对落石与滑坡两类地质灾害的自动识别与定位。研究构建了包含1000张标注图像的数据集(训练集810张、验证集90张、测试集100张),涵盖不同地形、光照和季节条件下的落石与滑坡样本
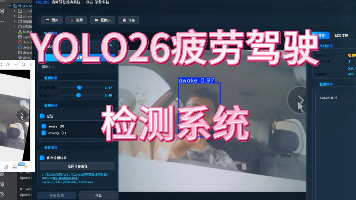
疲劳驾驶是导致交通事故的主要原因之一,因此开发实时、准确的驾驶员状态监测系统具有重要意义。本文基于YOLO26目标检测算法,构建了一个针对驾驶员面部状态的疲劳检测系统,专注于识别"清醒"(awake)和"疲劳"(drowsy)两种状态。系统采用YOLO26架构进行模型训练与优化,数据集包含训练集1056张、验证集103张和测试集71张。实验结果表明,模型在验证集上的平均精度(mAP50)达到0.9
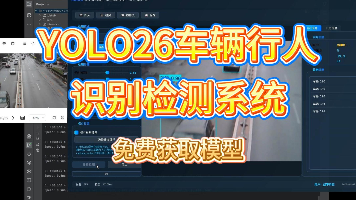
本报告基于YOLO26目标检测算法,构建并训练了一个面向交通场景的车辆与行人检测系统。系统采用双类别检测架构(行人、车辆),使用包含5607张标注图像的数据集进行训练与验证。实验结果表明,模型在验证集上取得了0.944的mAP50优异成绩,其中车辆检测mAP50达到0.970,行人检测达到0.919。模型推理速度仅1.2ms/张,具备实时检测能力。混淆矩阵分析显示,行人与车辆之间存在一定程度的互相
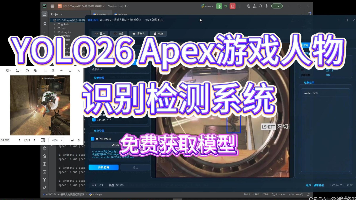
本文针对Apex英雄游戏中的关键视觉元素检测任务,构建了一套基于YOLO26深度学习模型的人物与物体识别系统。该系统以YOLO26架构为基础,实现对游戏画面中“avatar”(角色)与“object”(物体)两类目标的实时检测与定位。实验采用包含3,689张标注图像的数据集(训练集2,583张,验证集691张,测试集415张),经过充分训练后,模型在验证集上取得了0.846的mAP50。其中,av
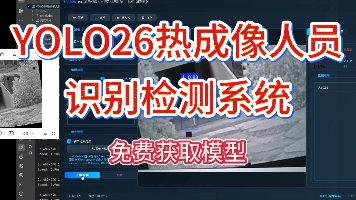
本文基于YOLO26目标检测算法,构建了一套面向热成像图像的人员识别检测系统。系统以YOLO26为骨干网络,采用单类别(人员)检测任务,训练数据集共包含25,000余张热成像图像,其中训练集21,422张,验证集3,061张,测试集1,531张。实验结果表明,模型在验证集上的mAP@0.5达到0.91。混淆矩阵分析显示,人员检测准确率为88%。系统在热成像低光照、复杂背景等条件下表现出较好的鲁棒性
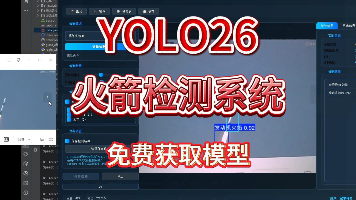
本文针对火箭发射过程中的关键目标检测任务,构建了一个基于YOLO架26构的三类目标检测系统,用于识别发动机火焰(Engine Flames)、火箭箭体(Rocket Body) 及太空(Space) 区域。模型在包含24,435张训练图像、2,428张验证图像及1,286张测试图像的数据集上进行训练与评估。实验结果表明,模型在发动机火焰与火箭箭体两类目标上表现优异,mAP50分别达到0.966与0
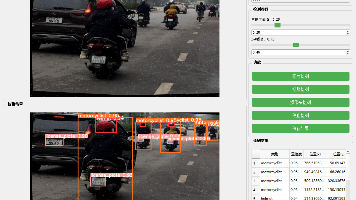
本项目基于YOLOv10目标检测算法,开发了一套专注于交通场景下骑手安全装备合规性检测的系统。模型共检测三类目标:佩戴的头盔(helmet)、摩托车车牌(license_plate)以及摩托车骑手(motorcyclist),类别数nc=3。该系统可同时对骑手、头盔及车牌进行实时定位,核心应用价值在于自动监控骑手是否按规定佩戴头盔,为智慧交通管理、违章自动执法及骑手安全督导提供有效的技术解决方案。
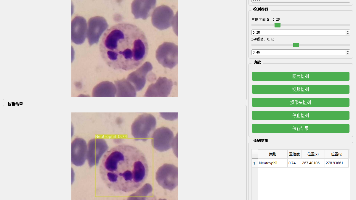
本项目基于YOLOv8目标检测算法构建了一个专业的白细胞类型识别系统,旨在实现血液显微图像中五类白细胞的自动化检测与分类。系统以YOLOv8模型为核心架构,设定nc(类别数)参数为5,对应识别嗜碱性粒细胞(Basophil)、嗜酸性粒细胞(Eosinophil)、淋巴细胞(Lymphocyte)、单核细胞(Monocyte)和中性粒细胞(Neutrophil)这些关键白细胞类型。
本项目基于YOLOv10目标检测算法构建了一个专业的火箭发射过程多部件检测系统,专门用于识别火箭发射过程中的三个关键组成部分:发动机火焰(Engine Flames)、火箭箭体(Rocket Body)以及周围空间背景(Space)。系统通过对火箭发射场景的实时分析,能够精准定位并分类火箭本体及其产生的尾焰。该项目展现了YOLOv10在高速度、高精度目标检测任务上的优势,适用于航天发射场监控、视频