登录社区云,与社区用户共同成长
邀请您加入社区
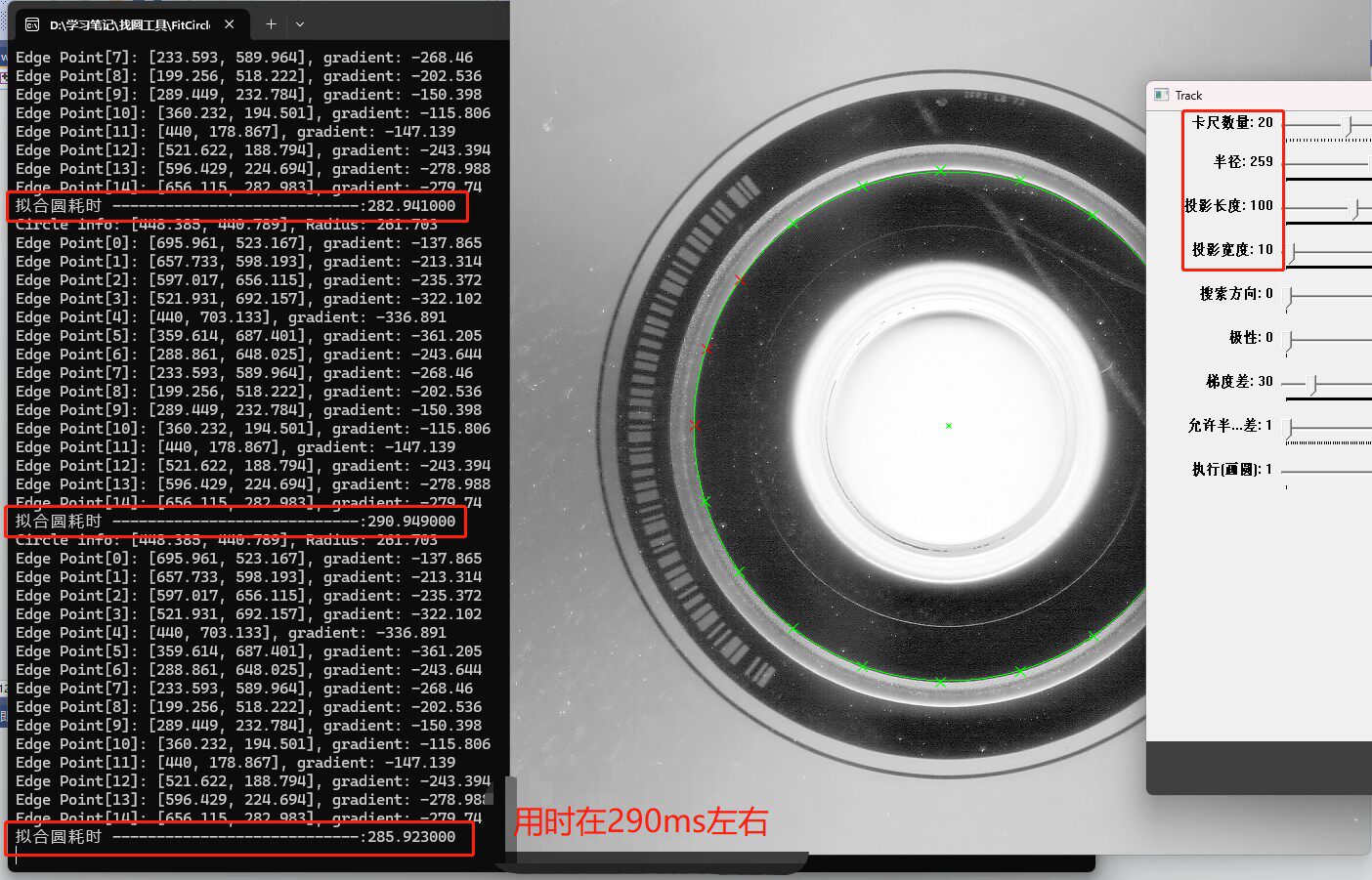
高效、可交互的OpenCV圆检测解决方案:原290ms卡尺找圆算法经深度优化降至15ms,附完整VS2015-2019兼容源码及详细注释,开箱即用,原理清晰,适合学习与工业集成。
遍历存储车辆的列表,若某中心点纵坐标位于检测线附近(±偏移量),则计数加1,并从列表中移除。这是一个基于OpenCV的车辆检测与计数项目,通过视频分析统计经过预设检测线的车辆数量。设置车辆的最小高宽(过滤掉过小的非车辆目标),检测线高度,检测线移量等等(之后会用到)。4.当车辆的中心点经过一条固定检测线时,计数器加1。
本文系统介绍了四种经典边缘检测算法。Sobel和Scharr算子基于一阶梯度,分别通过3×3卷积核计算水平和垂直方向边缘,其中Scharr精度更高。Laplacian算子利用二阶导数实现方向无关的边缘检测,但对噪声敏感。Canny算法通过高斯滤波、梯度计算、非极大值抑制和双阈值处理等步骤,综合性能最优。实验对比表明:Canny边缘连续性最好但计算复杂,Sobel/Scharr适合实时应用,Lapl
本文面向 Python 数据分析初学者,系统介绍 matplotlib 基础用法,包含折线图、柱状图、饼图、中文乱码处理、标题和坐标轴设置,以及从 Excel 读取数据绘图的完整示例代码。
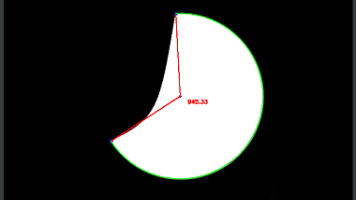
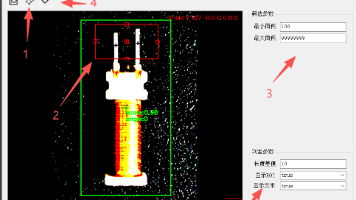
摘要: 本章介绍基于OpenCv的圆弧测量方法,包含角点查找和圆弧计算两个主要步骤。首先通过算法获取圆弧的两个角点,结合圆查找算法确定圆心;然后根据三点计算圆弧尺寸。文中提供了"VisionTool 探迹"免费工具下载链接和"VisionTool Halcon"付费工具信息。本章内容适合具备一定技术基础的读者,为视觉测量工作流的重要环节。
本文介绍了图像处理中的轮廓检测与分析方法。首先阐述了图像细化(骨架化)的原理和ZS细化算法流程,通过迭代删除边界像素点来获取单像素宽度的骨架。其次详细讲解了轮廓检测的概念、与边缘的区别,以及findContours()和drawContours()函数的使用方法。接着介绍了轮廓信息统计技术,包括计算轮廓面积和周长。最后探讨了三种轮廓外接多边形方法:最大外接矩形、最小外接矩形和多边形逼近,并给出了相
本文介绍了二维码检测和积分图像两个计算机视觉技术。在二维码检测部分,详细说明了QR码的结构组成(定位图案、对齐图案等)及其识别原理,并给出了OpenCV中二维码检测、解码的函数接口及示例代码。积分图像部分阐述了其计算原理(通过预先统计像素累加和快速计算任意矩形区域像素和),介绍了OpenCV的integral()函数及其参数说明,同时提供了创建测试图像并计算标准求和、平方求和及倾斜求和积分图像的完
本文介绍了三种角点检测方法:1)Harris角点检测通过计算矩形区域移动前后的像素差值来识别角点,使用cornerHarris函数实现;2)Shi-Tomasi角点检测改进Harris算法,采用goodFeaturesToTrack函数自动筛选稳定特征点;3)亚像素级优化通过cornerSubPix函数将角点坐标精确到小数级别。文中提供了各方法的OpenCV实现代码示例,包括图像预处理、角点检测和
摘要: 本章介绍基于OpenCV的视觉工作流中轮廓查找与间距计算的方法。通过模板匹配定位目标轮廓,支持单目标/多目标测量。轮廓查找使用圆形ROI工具定位并调整参数,间距计算则根据分段参数自动测量点距。配套的免费工具"VisionTool 探迹"新增轮廓提取、边缘检测、分段距离计算等功能,优化了算法与模块划分。付费工具"VisionTool Halcon"提供
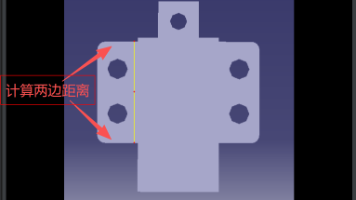
摘要: 本章介绍基于OpenCV的视觉工作流,重点讲解点线距离计算方法。通过圆卡尺工具定位圆心,直线卡尺工具识别直线,实现点线距离测量。相比章61,本方法支持独立点线捕捉,适用于复杂场景的单目标测量。配套免费工具"VisionTool 探迹"已更新至V1.0.2.0,新增轮廓提取、边缘检测等功能。另提供付费版"VisionTool Halcon"工具,适用于更专业的视觉处理需求。
本文记录 OpenCV 最核心入门实操代码,包含彩色 / 灰度图像读取、缩放、裁剪、属性查看、图像保存,以及本地视频逐帧读取播放、色彩空间转换全套基础用法,代码可直接运行,适合计算机视觉新手快速上手,全程无复杂知识点,零基础也能看懂。以上就是 OpenCV 最入门最实用的基础代码,所有代码均可直接复制运行,掌握这些内容就完成了计算机视觉第一步入门,后续可以在此基础上学习图像滤波、边缘检测、人脸识别
摘要: 本章介绍基于OpenCV的视觉工作流中线-线距离计算模块,包含直线查找和距离计算两大功能。通过直线卡尺工具定位目标边线,调整参数后捕捉直线特征,再基于几何关系计算线间距离。该模块支持单目标测量模式,适用于流水线检测场景。配套的VisionTool工具已更新至V1.0.2.0版本,新增轮廓提取、边缘检测等功能,并优化了分段算法和流程连线。提供免费版和付费版(Halcon版)供不同需求用户选择
Claude Code 是 Anthropic 基于 Claude 大语言模型打造的终端原生 AI 编程助手。理解整个代码仓库:读取项目结构、文件内容,给出上下文相关的建议执行终端命令:直接运行测试、构建、部署等命令读写文件:创建、修改、删除项目中的文件多文件协作:同时理解和修改多个相关文件Git 集成:自动生成 commit 信息、创建 PR 等简单来说,Claude Code 就像一位精通你整
该图像处理实验主控程序完成了彩色图像的全流程处理:首先读取图像并统一尺寸,然后依次执行彩色/灰度图显示、图像信息打印、颜色空间转换与通道分离、几何变换(缩放/旋转/平移/镜像等)、算术与按位运算(加减乘除/与或非异或)。所有处理结果通过模块化函数实现,最终合并保存为图像文件。程序采用BGR/RGB双格式兼容处理,通过matplotlib和OpenCV协同工作,确保颜色显示正确,体现了清晰的模块化设
本章介绍了基于OpenCV的视觉检测工作流,重点讲解长短脚引脚检测的实现方法。通过ROI工具设定检测区域,结合模板匹配技术实现工件任意摆放时的引脚尺寸测量,超出设定值则判定为不合格。文章配套提供了免费自研工具"VisionTool 探迹"和付费版"VisionTool Halcon"的获取方式,适用于流水线全检场景。该技术方案需要一定视觉检测基础,完整内容可参考相关系列文章。
摘要: 本章介绍基于OpenCV的弯脚检测视觉工作流,分为设定检测区域和识别判定两部分。通过ROI工具设定引脚区域并调整参数,利用模板匹配识别引脚角度,判断是否超出设定值。该模块支持工件随意摆放,适用于流水线全检测量场景。提供免费工具"VisionTool 探迹"和付费工具"VisionTool Halcon"的下载链接,适合有一定技术基础的读者参考。
本文将带你从原理到代码,一步步搭建一个基于计算机视觉的简易视力筛查工具。适合有一定Python基础的开发者和眼视光行业信息化从业者参考。一、项目背景作为一名既懂技术又关注眼视光行业的开发者,我一直在思考:能否用AI和计算机视觉技术,为基层视力筛查提供一个低成本、可推广的解决方案?答案是肯定的。本文介绍的方案利用OpenCV进行眼球检测和追踪,结合简单的眨眼频率分析,可以辅助判断被测者的数字眼疲劳程
摘要: 本章介绍基于OpenCV的毛刺检测方法,主要分为两个步骤: 设定检测区域:使用ROI工具框选引脚区域,调整尺寸和参数以精准捕捉目标。 识别判定:通过形态学处理提取图像差异,结合阈值判定毛刺是否超标(NG)。本方法支持模板匹配,适用于流水线全检场景。 配套免费工具VisionTool 探迹及付费版VisionTool Halcon(淘宝可购)可供实践。内容需一定技术基础,详细操作见配图及资源
本文详细介绍了如何利用Python中的`cv2.findContours()`函数实现简易车牌识别系统。通过图像预处理、轮廓检测和车牌区域精确定位等步骤,展示了轮廓检测技术在实际项目中的应用潜力。文章还提供了完整的代码实现和性能优化技巧,帮助开发者突破基础轮廓绘制的局限,提升计算机视觉项目的实战能力。
摘要: 本章介绍基于OpenCV的铜线检测视觉工作流,包含两个主要步骤:1)通过ROI工具设定检测区域,调整参数精确定位目标;2)识别铜线并判定尺寸是否合格,支持模板匹配实现工件任意摆放检测。配套免费工具"VisionTool 探迹"和付费工具"VisionTool Halcon"可供使用,适用于流水线全检场景。
→安装 C# 库Emgu.CV→C# 版 OpenCV(图像处理/视觉)你执行它 =给项目装上 OpenCV 能力dotnet add package Emgu.CV.runtime.windows 是 Windows 专用的「原生运行时」包,专门带 OpenCV 的 .dll 文件;没有它,你的 C# 程序一用 Emgu.CV 就直接崩溃。Emgu.CV= C# 接口(让你能写代码)= Wind
我是个懒人。安装软件的时候如果能少敲一行命令,我就绝不多敲。OpenClaw的安装其实已经很简单了,但如果你是那种连"打开终端"都嫌麻烦的人,那这个一键部署脚本就是为你准备的。我自己写了一个,经过多台机器测试,这里分享出来。OpenClaw最新版本一键部署包下载地址:https://top.wokk.cn/
一个基于C++14CMake 3.15的跨平台计算机视觉应用,集成OpenCV(图像处理/人脸检测)、Boost(数学/线程)、GLFW(窗口管理)三大库。编译器使用 Qt5.14.2 捆绑的。
这是一个基于 C# Windows Forms 的桌面端 OCR(光学字符识别)应用程序,通过集成百度 PaddleOCR v5/v6 系列模型,利用 OpenCV DNN 推理引擎在本地实现高效的文字检测与识别。用户可通过图形界面选择图片,一键完成文字识别,并在界面上直观查看识别结果与文字区域标注框。
本项目是,通过动态加载PPOCR.dll调用 PaddleOCR v5/v6 系列 ONNX 模型,在 Windows 平台使用 OpenCV DNN 推理引擎实现本地文字识别。程序以控制台交互方式运行,支持多套模型切换、循环批量识别,结构清晰、依赖简洁。
摘要: 本章介绍基于OpenCV的视觉检测方法,用于工件包胶不良检测。通过设定ROI区域捕捉目标,结合模板匹配实现工件随意摆放检测。根据识别区域面积判定胶带是否超出设定边界,面积过大则判定为不合格(NG)。文中提供了自研免费工具“VisionTool 探迹”和付费工具“VisionTool Halcon”的下载链接,适用于流水线全检场景。
Python 类项目更适合算法、数据处理、推荐系统、图像识别方向,能够体现一定技术深度。本文主要整理这一类项目的基础搭建思路,包括项目创建、目录结构、功能模块、数据库设计方向,以及一些可以继续扩展的选题案例。
opencv
——opencv
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区








 DeepSeek技术社区
DeepSeek技术社区






 龙虾开发者社区
龙虾开发者社区



