




- @2401_85375186
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文深入剖析了AI Agent(智能体)的构成与运作机制,揭示其并非仅仅是高级大语言模型,而是集成了LLM(大模型)、Memory(记忆系统)、Tools(工具系统)和Thinking Skills(思考能力)四大模块的复杂系统。文章详细阐述了Agent如何通过理解、规划、执行和反馈的流程完成复杂任务,并强调了Skills作为AI标准操作手册(SOP)的重要性。此外,本文还展望了AI Agent在
本文深入剖析了AI Agent(智能体)的构成与运作机制,揭示其并非仅仅是高级大语言模型,而是集成了LLM(大模型)、Memory(记忆系统)、Tools(工具系统)和Thinking Skills(思考能力)四大模块的复杂系统。文章详细阐述了Agent如何通过理解、规划、执行和反馈的流程完成复杂任务,并强调了Skills作为AI标准操作手册(SOP)的重要性。此外,本文还展望了AI Agent在
AI Agent是让AI从聊天工具升级为生产力工具的关键。它像数字助理一样,能自主行动,完成订票、规划行程等任务。AI Agent由感知、规划、工具调用和记忆模块组成,能像人类一样思考并执行任务。目前,AI Agent已应用于个人助理、企业办公和多个行业,提升效率。尽管面临挑战,但AI Agent将是未来AI应用的核心形式,了解和使用它将抢占先机。
AI Agent是让AI从聊天工具升级为生产力工具的关键。它像数字助理一样,能自主行动,完成订票、规划行程等任务。AI Agent由感知、规划、工具调用和记忆模块组成,能像人类一样思考并执行任务。目前,AI Agent已应用于个人助理、企业办公和多个行业,提升效率。尽管面临挑战,但AI Agent将是未来AI应用的核心形式,了解和使用它将抢占先机。
本文通过一个案例引入AI Agent的概念,解释其核心组成模块(规划、推理、工具集、记忆)和运作原理。重点介绍了ReAct和Plan-and-Execute两种推理范式,以及Tool Call、Human-in-the-Loop和Agent Skills等技术。此外,还探讨了沙箱、Session管理、上下文管理、知识库与记忆等外围组件,最后展望了Agent的未来发展趋势和潜在风险,为读者提供了全面
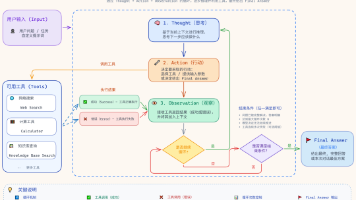
本文通过一个案例引入AI Agent的概念,解释其核心组成模块(规划、推理、工具集、记忆)和运作原理。重点介绍了ReAct和Plan-and-Execute两种推理范式,以及Tool Call、Human-in-the-Loop和Agent Skills等技术。此外,还探讨了沙箱、Session管理、上下文管理、知识库与记忆等外围组件,最后展望了Agent的未来发展趋势和潜在风险,为读者提供了全面
还记得 AI 只是聊天机器人给出刻板回答的时代吗?那已经是过去式了。如今的 AI 代理可以研究、编码、聊天、创造,甚至与其他 AI 代理协作,就像小小的数字联合创始人。
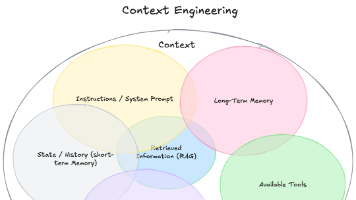
"上下文工程是一门设计和构建动态系统的学科,它以正确的格式在正确的时间提供正确的信息和工具,为 LLM 提供完成任务所需的一切。”
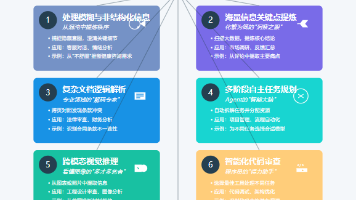
在AI技术迅猛发展的时代,Agent开发者既面临挑战,也迎来了无限可能。如何从海量数据中精准提取关键信息?如何让Agent更智能地理解用户意图并作出响应?这一切的答案都藏在模型推理的底层逻辑之中。本文将为你详细解析Agent开发者不可或缺的7大推理场景和5大实用技巧,助你在AI浪潮中脱颖而出。
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
