登录社区云,与社区用户共同成长
邀请您加入社区
说明:步骤:1、安装database navigator2、链接数据库:pycharm 社区版链接mysql数据库_奋斗吧-皮卡丘的博客-CSDN博客_pycharm社区版连接mysql数据库
pycharm安装报错
本文为人脸识别项目的UI界面设计部分代码,主要使用Qt-Designer、PyUIC工具设计界面,生成代码,同时使用组件的setStyleSheet等方法进行美化。
针对 MacBook Pro M3 系列在部署最新版 PyCharm 时遇到的解释器失效、JVM 内存溢出及 UI 渲染冲突,本文提供了一套标准化的生产力调优方案。
的SoC,集成了强大的CPU、NPU和视频处理能力,广泛应用于需要实时AI分析的复杂场景,如高端安防摄像机、AI门禁门铃、行业专用设备等。:智能视频引擎,支持智能分析预处理(如移动侦测、目标跟踪等),与NPU协同工作,提升整体效率。:A35的引入使得SSC30KQ在运行复杂的应用程序和AI算法时更加游刃有余。:支持人脸识别、人形检测、车辆检测的AI网络摄像机。,封装尺寸更小,非常适合空间受限的AI
解决python遇到的问题
这篇文章记录了 PyTorch 的安装过程,包括创建并激活新的虚拟环境,查看电脑是否支持 CUDA 以及 CUDA 的版本,根据 CUDA 的版本安装 PyTorch,在 PyCharm 中创建使用 pytorch_gpu 虚拟环境的新项目,在 PyCharm 中验证 PyTorch 是否安装成功。
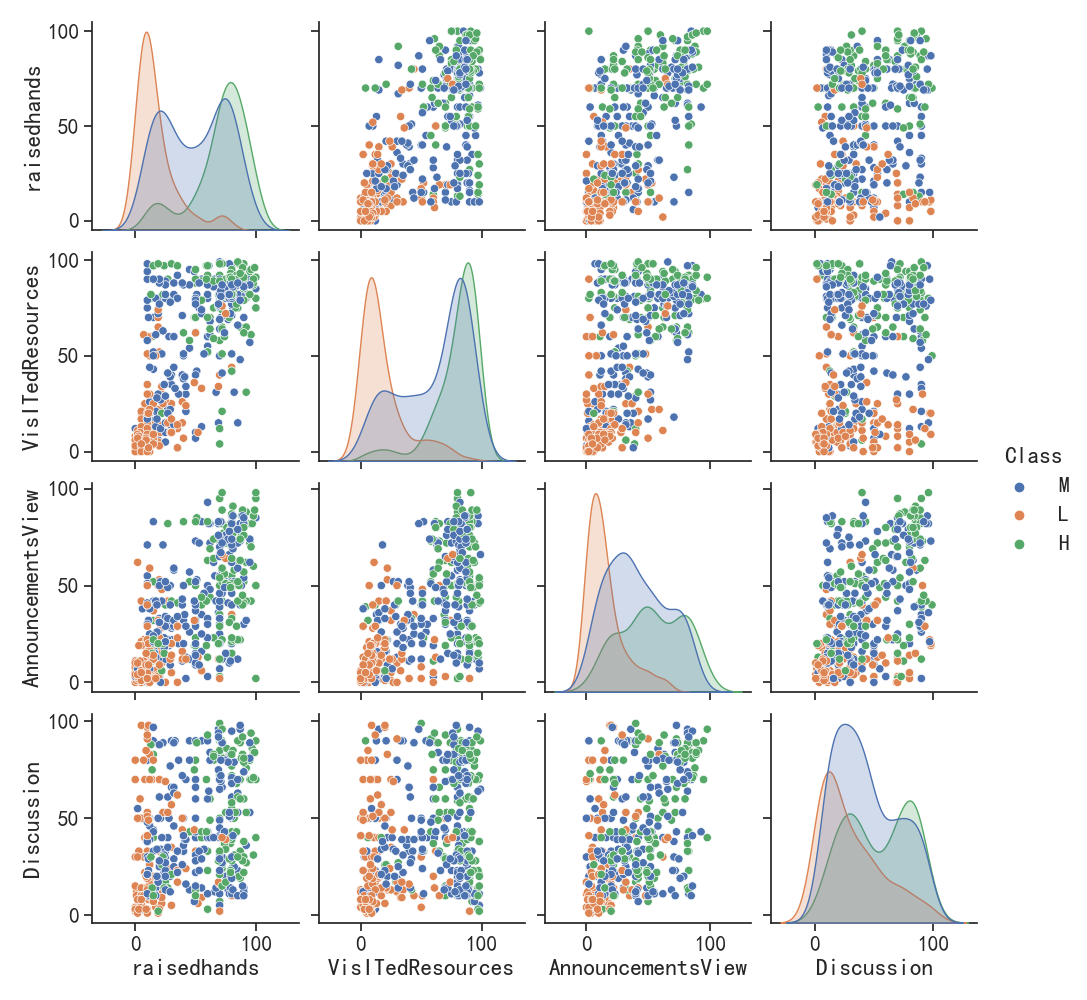
本文使用csv数据进行基础的数据分析与可视化,为后续机器学习打下良好基础
在实际应用中,我们要根据需要选择合适的数据类型来存储和操作数据。
该项目在pycharm上编译运行,一些涉及pycharm、Anaconda、python的bug写在另一篇博客里https://blog.csdn.net/Netceor/article/details/94725863目录一、导入opencv包二、打开视频捕获人脸一、导入opencv包Win+R,输入cmd打开控制台在控制台安装opencv-python,此处我已经安...
pycharm
——pycharm
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵