- @m0_59235699
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
你是不是也有这样的体验?用ChatGPT、文档问答机器人,刚开始觉得还行,但用久了发现它总是“死脑筋”,问同样的问题,答得千篇一律,甚至一错再错。你想:“要是它能记住我的吐槽和建议,下次别再犯同样的错就好了!”——恭喜你,这正是RAG反馈回路(Feedback Loop)的核心诉求。
一个共识是,AI 今年的大主题,是 Agent。

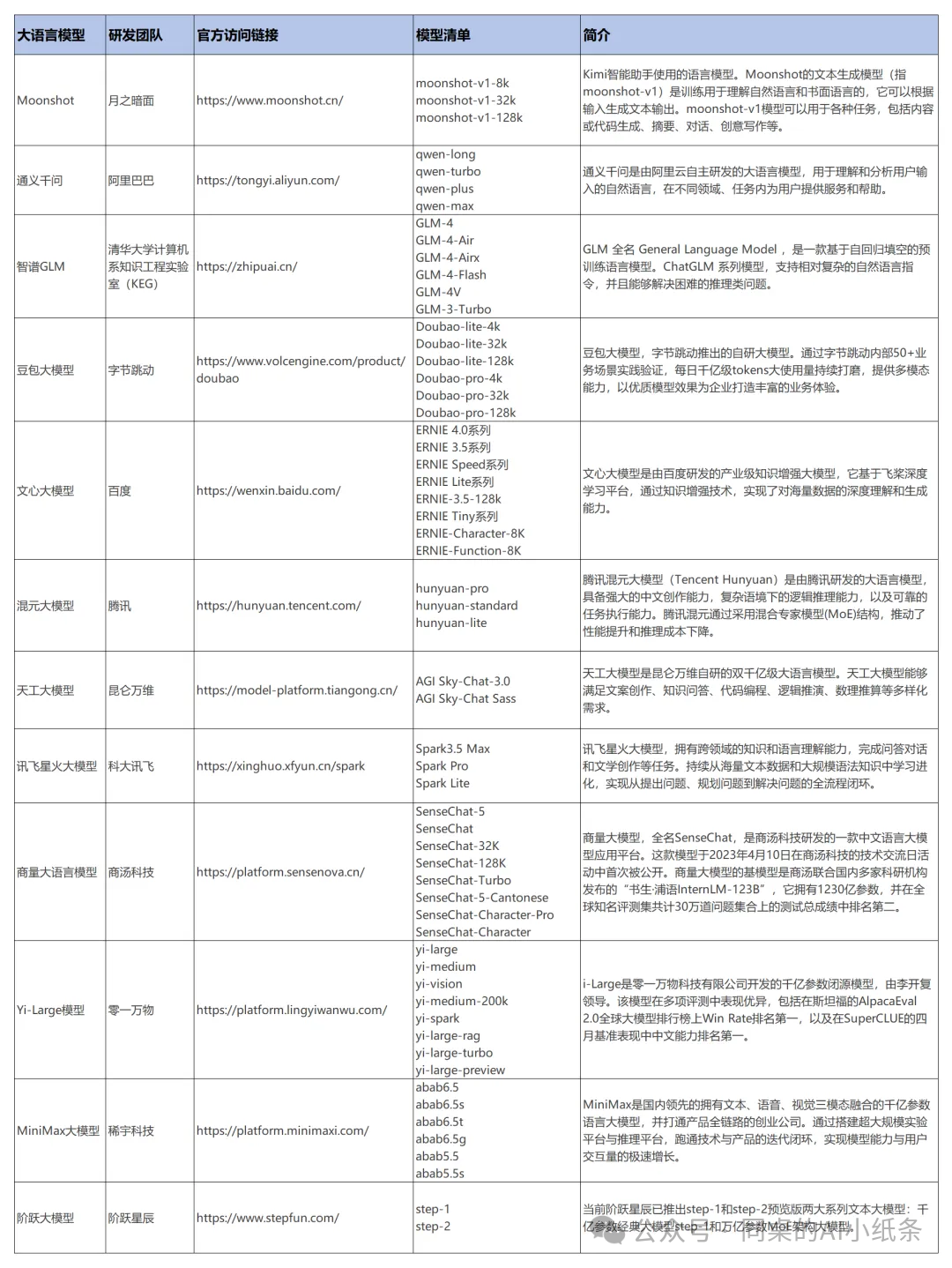
Moonshot AI是一家专注于通用人工智能领域的创新型企业,其核心产品Kimi智能助手搭载了先进的语言模型——moonshot-v1。该模型专门训练用于处理和理解自然语言及书面语言,能够根据用户的输入生成相应的文本输出。moonshot-v1的应用范围极为广泛,包括但不限于内容创作、代码生成、文本摘要、对话系统以及创意写作等。
今天我们讲两个方面的内容,使用大模型进行标书写作的一个简单开源项目,以及再看openai O1进展及LLM-Self-Correction机制。
在当今科技驱动发展的时代,**电子信息类、计算机类、自动化类、电气类和机械类**5大工科类专业,因其就业前景广阔、行业需求旺盛而备受关注。不管是高考志愿填报,还是大学专业分流,都是热门方向。

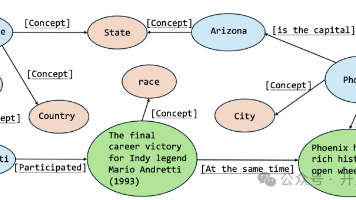
知识图谱(KGs)已经可以很好地将海量的复杂信息整理成结构化的、机器可读的知识,但目前的构建方法仍需要由领域专家预先创建模式,这限制了KGs的可扩展性、适应性和领域覆盖范围。
随着企业数字化转型的加速,数据管理和分析变得越来越重要。传统的指标管理平台虽然已经能够帮助企业有效地收集、计算、管理和展示关键指标,但在业务分析层面,面对日益复杂的数据环境和业务需求,单纯依靠人工分析已经难以满足高效、精准的管理要求。为此,将指标管理平台与AI大模型相结合,成为了一种新的趋势。本文将,探讨如何通过AI+的融合,实现指标检索、指标趋势查看、指标数据查询和指标归因分析等应用场景,助力企

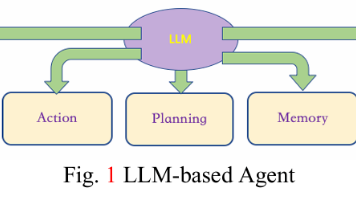
摘要:智能体被定义为能够感知环境、做出决策并采取行动的人工实体。受汽车工程师协会(SAE)自动驾驶六级分类的启发,智能体也根据其功能和能力被划分为以下层级:L0——无 AI,具备工具(有感知能力)和行动;L1——使用基于规则的 AI;L2——用基于模仿学习(IL)/强化学习(RL)的 AI 替代基于规则的 AI,增加推理和决策能力;L3——应用基于大型语言模型(LLM)的AI 替代基于 IL/RL
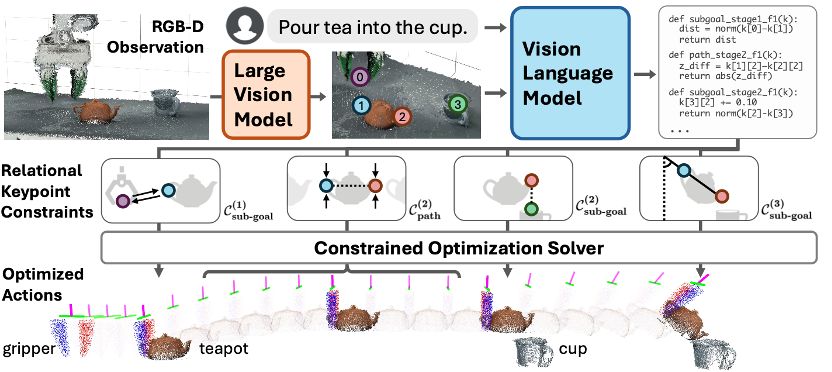
近日,Google DeepMind发布了基于 Gemini 2.0 的具身推理模型Gemini Robotics-ER以及动作模型Gemini Robotics。Gemini Robotics-ER 通过增强的具身推理(ER)能力,将语义理解扩展至物理几何(如 3D 结构、物体位姿)和动态场景(如运动轨迹、接触效应),使机器人从“感知环境”升级为“理解物理规律”。例如,它能识别咖啡杯的把手并规划
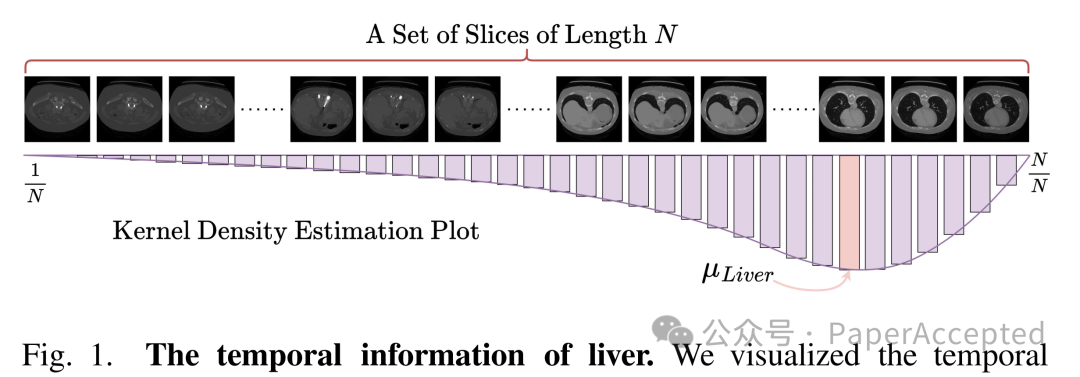
医学图像分割技术的进步得益于深度学习技术的应用,尤其是基于UNet的方法,这些方法利用语义信息来提高分割的准确性。然而,当前基于UNet的医学图像分割方法忽视了扫描图像中器官的顺序。此外,UNet的固有网络结构不提供直接整合时间信息的能力。为了有效地整合时间信息,作者提出了TP-UNet,它利用时间提示,包括器官构建关系,来指导分割UNet模型。具体来说,我们的框架以无监督对比学习为基础的交叉注意