- @m0_70486148
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DeepSeek是一个专注于AI模型开发与部署的平台,支持多种深度学习框架(如TensorFlow、PyTorch)的模型转换与优化。它能够将复杂的AI模型高效地部署到端侧设备上,满足实时性与资源受限场景的需求。本书以讯飞星火认知大模型为例,全面系统地阐述其基础知识、操作方法与技巧,以及相关实战案例。全书共分为12章,第1章为新手入门篇,为读者铺垫了讯飞星火认知大模型(以下简称讯飞星火)的基础知识

作者深度评测了9大AI智能体搭建平台(Dify、Coze、豆包、腾讯元器、文心智能体平台、通义、智谱清言、讯飞星辰Agent平台和纳米),重点关注提示词长度、语音输入、AI绘图和移动端支持等功能。通过对比测试,最终推荐智谱清言作为创建小学英语口语陪伴智能体的最佳选择,因其提示词支持度高、AI绘图功能完善且操作简单。上篇文章,分享了通过Agent平台,搭建一个小学口语陪伴的智能体。结果接下来,原本要
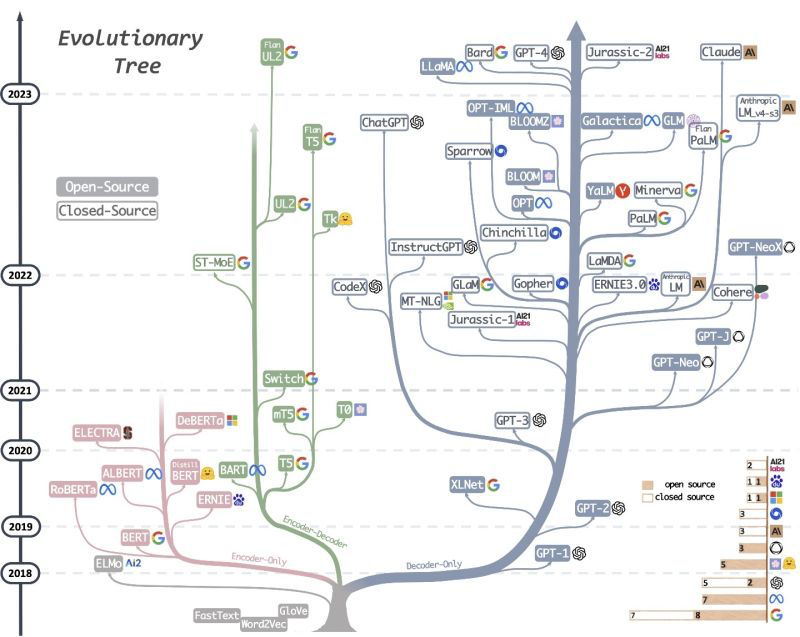
生成式人工智能 (GenAI),尤其是 ChatGPT,吸引了所有人的注意力。基于 Transformer 的大型语言模型 (LLM) 经过大规模无标记数据训练,展现出可以推广到许多不同任务的能力。为了理解 LLM 为何如此强大,我们将在这篇文章中深入探讨它们的工作原理。LLM 进化树正式来说,仅解码器语言模型只是给定上下文的下一个标记的条件分布。这种公式是马尔可夫过程的一个例子,该过程已在许多用
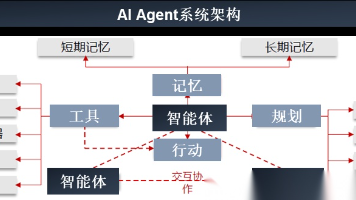
Agentic 系统是一种能够感知环境、做出决策并自主执行行动以实现目标的计算实体。与传统软件不同,智能体具备自主性主动性响应性和目标导向的特性。其关键能力包括工具使用记忆和通信。Agentic 设计模式是经过实战检验的模板和蓝图,为智能体行为设计与实现中的常见挑战提供可复用解决方案。使用设计模式能提升智能体构建的结构性、可维护性、可靠性和效率,避免重复造轮子,并使开发者能专注于应用创新。
2025 年标志着人工智能(AI)发展的一个关键拐点,AI 智能体(Agent)正从前几年的实验性原型(如 AutoGPT)演变为企业战略与核心产品的基石。随着大模型技术的逐渐成熟,市场对人工智能的能力需求已从单纯的 “内容问答” 转向要解决 “实际任务”。AI 智能体作为能够自主理解意图、规划步骤、调用工具并执行复杂任务的新一代人工智能应用范式,正在成为全球科技巨头和创业公司竞相布局的战略高地。
AI 智能体和以前的 AI 有啥不一样 —— 传统的聊天机器人、AI 助手,本质就是 “只会回话的信息员”。比如你问 “明天广东天气咋样”,它能告诉你温度,但要是说 “帮团队订下周去广东的机票和酒店”,它顶多给你列几个订票链接,剩下的查航班、比价格、填信息,还得你自己动手。但 AI 智能体不一样,它是 “能自己琢磨、自己办事的帮手”。
本文详细介绍了如何使用n8n自动化工具,结合Deepseek API和邮件发送功能,实现AI日报的海报自动化生成。作者从实际操作出发,逐步讲解了n8n的本地部署、海报底图的制作、API key的获取以及工作流的搭建过程。通过HTML节点提取网页内容,利用Basic LLM Chain节点进行内容整理,并最终通过Edit Image节点生成海报图。整个过程详细且实用,适合想要提升职场效率的小白和程序

快速构建企业级知识库应用***,在。
在信息爆炸的时代,我们每天都面临着海量的信息。如何有效地管理和利用这些信息,成为了我们面临的一大挑战。这就是知识库诞生的原因。知识库能够有效地整理和组织信息,使我们可以更方便地查找和利用这些信息。而且,知识库也是实现人工智能和机器学习的基础,因为这些技术需要大量的数据和知识来进行训练和学习。然而,传统的知识管理方式却面临着一些局限性。主要的问题在于,这些方式主要依赖于人工,劳动强度大,效率低,容易
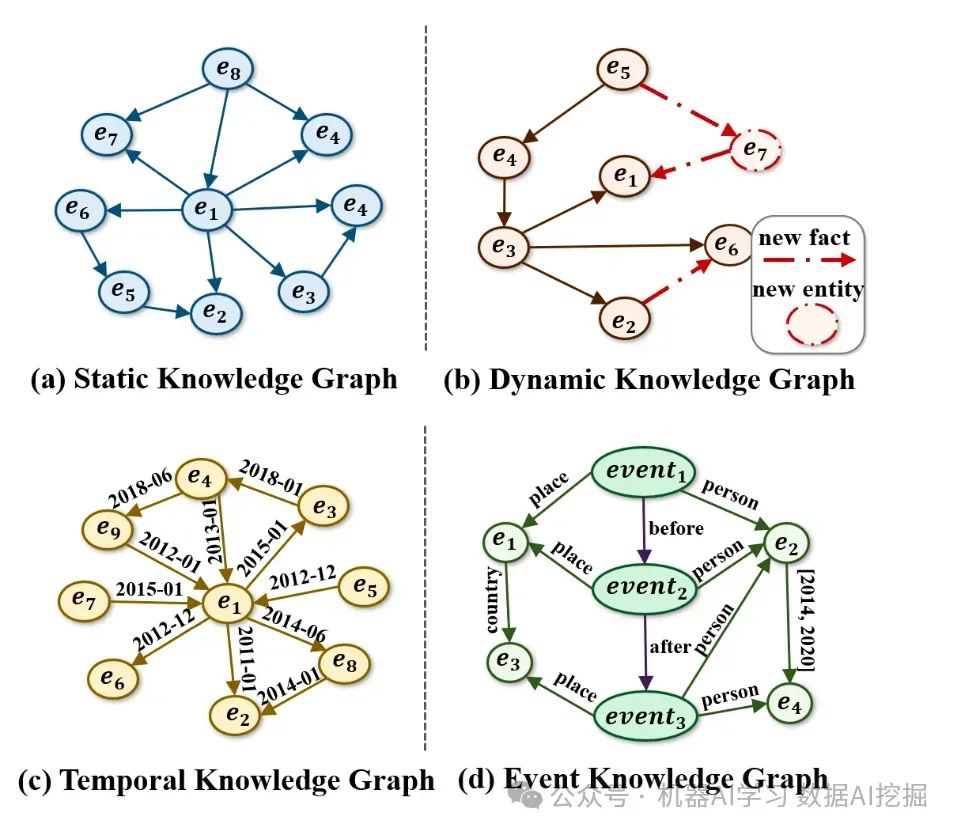
知识图谱(KG)的发展与人工智能(AI)代理的进步紧密相连。从它们的静态起源开始,知识图谱已经发展到包括动态、时态和事件驱动的范式,每个范式都为AI系统解锁了新的能力。本文探讨了它们的演变以及大型语言模型(LLM)如何融入这些进步。简而言之,所有知识图谱的演变都是关于时间的。静态图谱静态知识图谱是基础结构,其中实体和关系是固定不变的。例如,WordNet、Freebase和Kinship将实体表示