- @2401_85375298
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
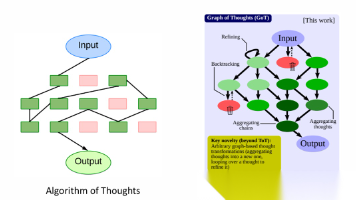
主动式人工智能通常指具有自主决策能力机制,并能够自主采取行动以实现特定目标的 AI 系统,这些行动需在有限或无需直接人工介入的情况下完成。

GitHub上持续火爆的《LeeDL-Tutorial》项目,一发布就迅速获得了11.4K的星星!这个项目基于李宏毅老师“机器学习”课程,课程全网超过百万播放量,如今Datawhale新书**《深度学习详解》李宏毅、杨小康、周明、叶杰平、邱锡鹏** 5位人工智能领域大咖的推荐!李宏毅老师是台湾大学的资深教授,专攻机器学习、深度学习和语音识别与理解。让我们对他耳熟能详的莫过于他的**“机器学习” 课

在本文中,我们探讨了 LoRA 微调方法,并以 StarCoder 模型的微调为例介绍了实践过程。通过实践过程的经验来为大家展示一些细节及需要注意的点,希望大家也能通过这种低资源高效微调方法微调出符合自己需求的模型。
(或称为“头”)进行处理。****

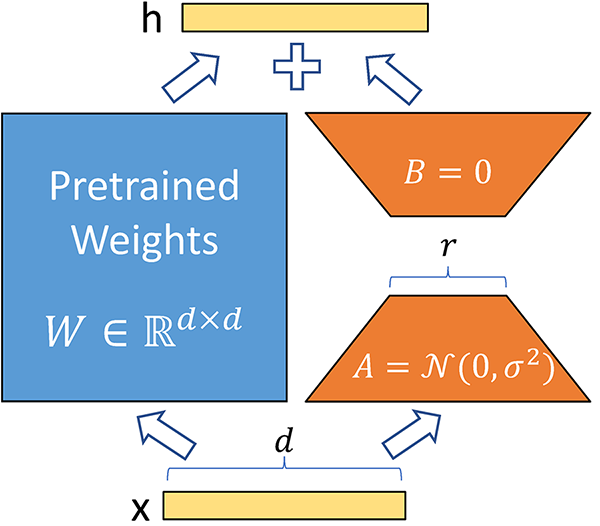
微调定制化的大型语言模型需要投入大量时间和精力,但掌握恰当的微调方法和技巧能显著提高效率。比如用LoRa(LLM的低秩适配Low-Rank Adaptation)微调大模型,能够利用少量显卡和时间对大模型进行微调,降低成本。
大模型能力的提升是一个渐进过程,因此在实际应用中,许多模型仍然存在不确定性和不稳定性。使用基于大模型的 Text2SQL 方案生成的 SQL 查询时,需要格外谨慎,确保降低潜在风险。明确数据库上下文:在生成 SQL 前,清楚描述所使用的数据库结构、表关系和字段信息。限制查询输出规模:避免一次性返回过多数据,控制查询结果量。验证与检查 SQL:在执行前仔细审查生成的 SQL,确保其正确性和安全性。通
本文聊聊 LLama-Factory,它是一个开源框架,这里头可以找到一系列预制的组件和模板,让你不用从零开始,就能训练出自己的语言模型(微调)。不管是聊天机器人,还是文章生成器,甚至是问答系统,都能搞定。而且,LLama-Factory 还支持多种框架和数据集,这意味着你可以根据项目需求灵活选择,把精力集中在真正重要的事情上——创造价值。使用LLama-Factory,常见的就是训练LoRA模型

本文聊聊 LLama-Factory,它是一个开源框架,这里头可以找到一系列预制的组件和模板,让你不用从零开始,就能训练出自己的语言模型(微调)。不管是聊天机器人,还是文章生成器,甚至是问答系统,都能搞定。而且,LLama-Factory 还支持多种框架和数据集,这意味着你可以根据项目需求灵活选择,把精力集中在真正重要的事情上——创造价值。使用LLama-Factory,常见的就是训练LoRA模型
本文推荐李宏毅老师的最新AI大模型入门教程,共11讲,涵盖大模型发展历史、应用方向、提示词工程、生成策略、深度学习基础、Transformer模型、大模型评估、道德问题、AI可解释性、视觉大模型以及GPT-4o解析等内容。教程旨在帮助初学者快速掌握大模型核心知识,为后续深入学习大模型微调、训练、推理加速等打下坚实基础。现在国内外关于大模型入门教程做的比较好的并不多,这其实也是一件好事,有难度和有门
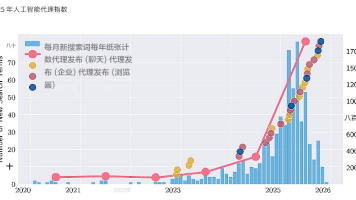
这份指数在1350 个维度上记录了 30 个代理系统,但更重要的,是它揭示了三个结构趋势:第一,安全披露高度不均。仅有极少数代理发布针对自身架构的系统卡片。大多数系统要么只披露基础模型信息,要么只强调合规认证。能力基准与安全评估之间存在明显不对称。当代理风险越来越多地来自规划能力与工具调用,而不仅是模型输出时,仅依赖模型层面的文档已不足够。第二,基础模型高度集中。几乎所有代理都依赖GPT、Clau