登录社区云,与社区用户共同成长
邀请您加入社区
Noetra计划在遵循修改后的《外汇及对外贸易法》标准的前提下,向日本企业广泛公开模型,通过自主开发确保安全性,而非依赖外部模型,各参与企业也将根据自身场景利用Noetra大模型开发应用。NVIDIA CEO黄仁勋也出席发布会,称日本产业一线的智慧“是国家的瑰宝,不能失去”,并强调自主驱动机器和机器人的物理AI相关基础设施“应该在日本制造”。至于选择通用模型的原因,主要是由于在网络防御等最先进AI
本文介绍了个人中心中两个展示型页面"身体数据"和"我的成就"的实现差异。"身体数据"采用纵向列表布局,通过彩色卡片展示各项指标;"我的成就"采用网格布局,用不同颜色区分已获得和未获得的徽章。文章详细拆解了两个页面的代码结构、配色逻辑和交互设计,重点分析了列表卡片的数据展示方式和网格徽章的条件渲染技巧,体现了ArkTS中两种典型排列模式的应用场景与实现细节。
智能搜索与信息整合代码生成与优化文本创作与润色数据分析与可视化建议任务自动化辅助总结 DeepSeek 的价值,鼓励读者尝试并探索个性化使用方式。
面向对象编程(Object-Oriented Programming,简称OOP)是一种基于“对象”的软件开发范式。对象可以包含数据(通常称为属性或字段)和操作数据的代码(通常称为方法或函数)。C#作为一种现代的、类型安全的面向对象语言,从设计之初就深刻融入了OOP的理念。理解OOP的四大基本特性——封装、继承、多态和抽象,是掌握C#编程的基石。通过将现实世界中的实体抽象为程序中的类和对象,开发者
C++编程的艺术,在于在代码整洁性与极致性能之间找到最佳的平衡点。过度追求性能而牺牲可读性,会导致代码难以维护;而只顾整洁忽视性能,则可能无法满足关键应用的需求。正确的路径是:首先构建清晰、健壮、易于维护的代码结构,然后基于准确的性能分析,有针对性地应用高级优化技术。这种从宏观到微观、从可读性到效率的渐进式追求,正是C++开发者通往卓越的必经之路。
当她用CRTP元编程破解跨平台兼容的封印,古老的内存泄漏在智能指针的降智期开关中重新苏醒——那些未经析构的热带情欲正从RAII的缝隙渗出,将新生儿的指针血液染成未对齐的粉色。玛孔多最后的开发者跪在寄存器沙漏前,终于读懂指向类型的寓言:所有クラス的父辈都藏在派生的阴影里,而跨平台的悲怆乐章在静态库的圣歌中宣告永恒编译。帕布罗·布恩迪亚第一次在吉普赛人带来的汇编语言里嗅到危险的气息——那些用十六进制排
本研究尝试构建深度学习模型,系统分析古诗文本的音韵特征与语境耦合机制,继而通过可视化技术揭示两者在微观与宏观层面的交互规律。实验表明,在《全唐诗》语料测试中,BERT-base模型对岑参《白雪歌》将军角弓不得控中双控字的张力关系,其上下文向量余弦相似度达0.82,显著高于n-gram模型的0.56基线值,印证了端到端语境建模的优势。实验显示,在李白《蜀道难》分析中,难字在首句(首联)的向量向李白《
摘要:本文探讨了基于C++的高性能CoAP协议系统在物联网中的应用及测试挑战。系统采用分层架构设计,包含消息处理、资源管理、协议解析等核心模块,通过单元测试、集成测试和仿真测试确保可靠性。针对低延迟、高并发和异常网络环境等挑战,提出异步IO、消息缓存等优化方案,并引入DTLS加密保障安全性。测试结果显示系统延迟降低28%,支持3万+并发连接,消息成功率99.5%。未来将结合AI与边缘计算进一步提升
摘要: 边缘计算环境下,Java系统运维面临节点管理复杂、资源受限、网络不稳定等挑战。通过容器化部署(Docker/K3s)、分布式监控(Prometheus/ELK)和智能告警优化资源管理,结合JVM调优(G1GC/轻量线程池)、本地缓存(SQLite/Redis)及自动化调度(Kubernetes HPA),可提升边缘节点性能。实践表明,该方案能降低30%延迟,提高25%资源利用率,并实现快速
摘要:本文对比分析了Java、C#和C++三种主流编程语言的特点和适用场景。Java凭借JVM跨平台优势,适合企业级和Web开发;C#借助.NET Core实现跨平台,在微软生态及游戏开发中表现突出;C++则以高性能著称,适用于系统编程和游戏引擎开发。文章从跨平台性、性能、开发效率等维度对比三者的优劣势,建议开发者根据项目需求(如性能要求、平台兼容性)选择合适语言:Java适合企业应用,C#适合微
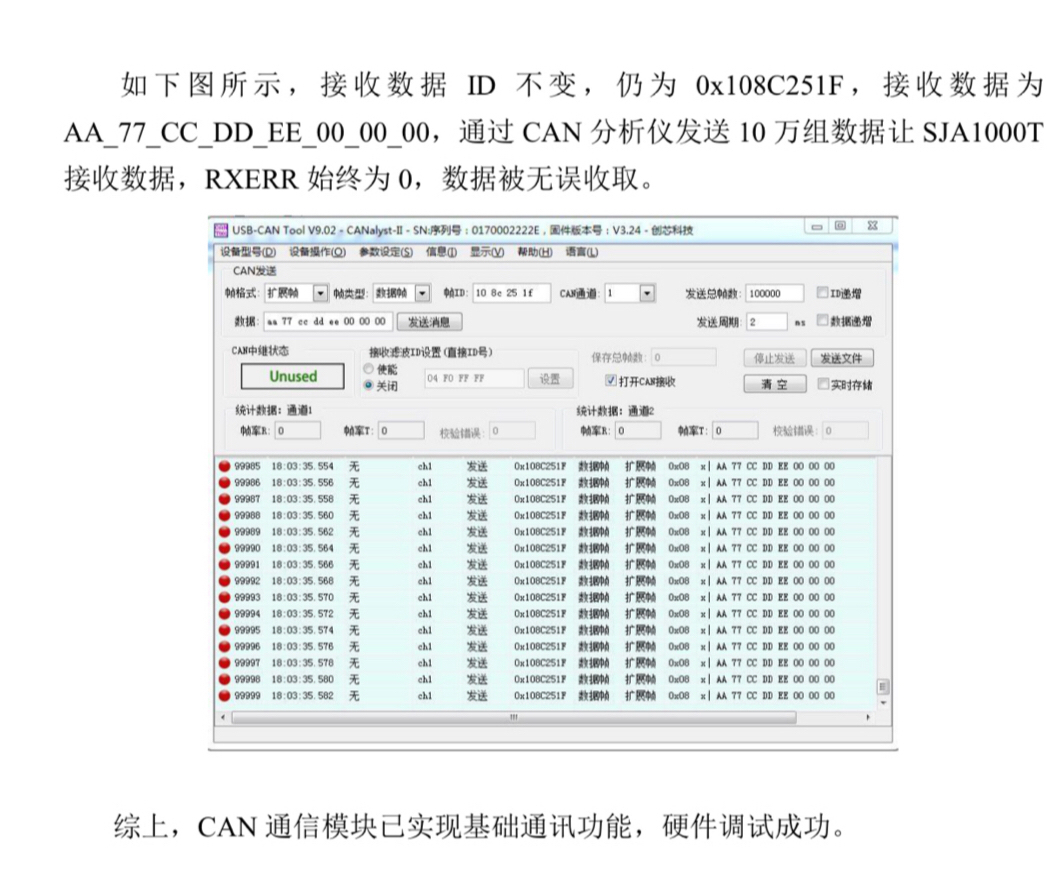
在工业控制、汽车电子等领域,CAN总线以其高可靠性、实时性成为核心通信技术。本文解析的代码套件,以FPGA为控制核心,驱动SJA1000T CAN控制器芯片,实现标准帧(SFF)与扩展帧(EFF)的全功能通信。该系统采用Verilog HDL语言开发,适配40MHz时钟频率,涵盖芯片初始化、数据收发、异常恢复、仿真验证全流程,具备高稳定性、可扩展性及工业级适配能力。
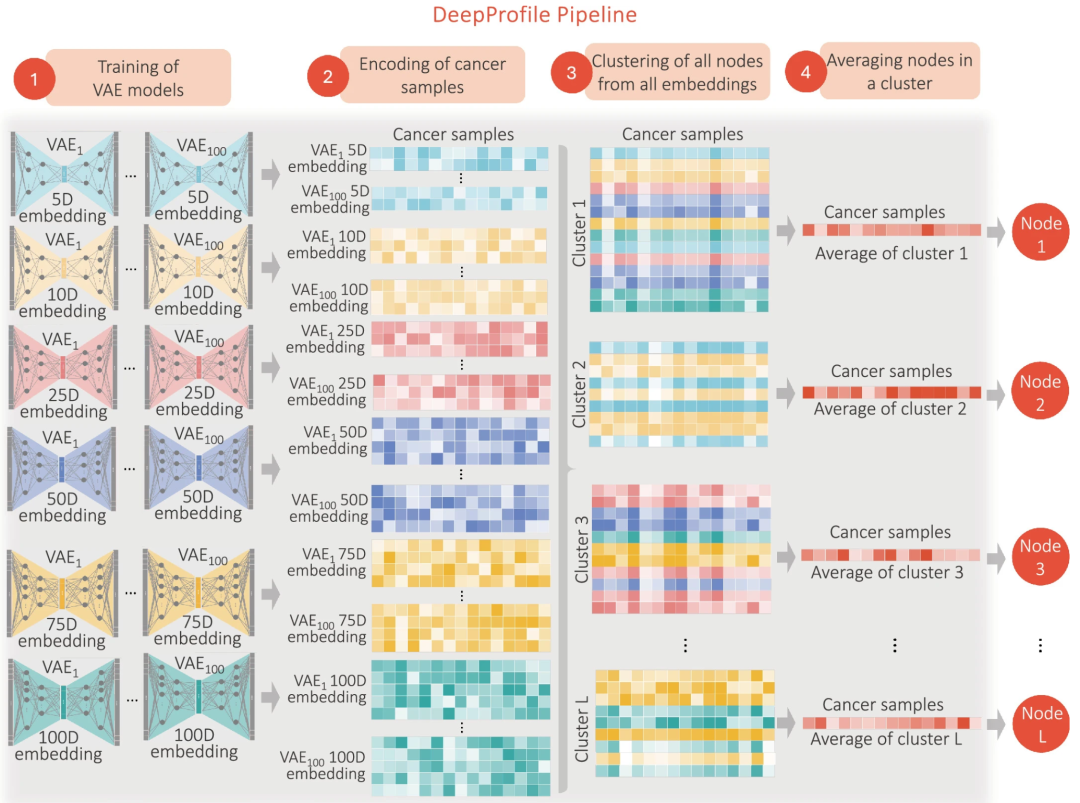
来自中国科学院的研究者开发了一个基于转换器的图形表示学习(TREE)框架,着力于癌症基因识别任务中的可解释性和可推广性。神经网络在解析复杂生物网络或者是多模态数据方面有非常大的优势。先前小编分享了一篇基于)的泛癌框架,纯数据库挖掘+简单架构(超低成本)登上了顶刊。▲:通过训练数百个VAE模型提取癌症样本的潜在变量。每个VAE模型具有不同的潜在维度大小,并进行100次随机权重初始化。使用这些模型对癌
这个错误的核心原因是 Storm 版本与本地 JDK 版本不兼容:我本地使用的是 JDK 1.8(对应类文件版本 52.0),但使用的 Storm 2.8.2是用 Java 17 编译的(对应类文件版本 61.0),低版本 JDK 无法解析高版本编译的类文件。(用于将 CSV 股票数据写入 Kafka,这样就可以顺利解决找不到主类的问题了。
在电动工具、储能电源、小家电设备、大功率移动设备等场景中,多串锂电池组凭借高电压、大功率输出成为核心动力源。快充需求持续升级,如何在缩短充电时长的同时保障电芯寿命与使用安全,成为技术研发的核心命题。本文从原理、方案、应用与安全四大维度,全面解读多串锂电池快充技术。
1.什么是实时计算?流式计算举例自来水厂处理水的过程(图)特点源源不断任务类型采集数据-->Spout任务处理数据-->bolt任务2.跟离线计算的区别(1)离线计算采集数据强调是批处理(2)实时计算storm采集数据flume强调是源源不断3.常见的实时计算框架(3)JStorm(4)Flink。...
当你把一个重要话题扔给Claude或任何大模型,只给一句提示时,你得到的是一个视角的输出。它可能逻辑清晰、语言流畅,但总会留下一些你自己都意识不到的盲区:某个关键假设没被挑战,某个利益相关方的视角被忽略,某个数据来源没被严格核实。Nate Herk把Stanford的STORM研究方法做成了免费的Claude技能,直接把这个短板变成了可落地的系统。他用五个不同背景的Agent并行审视同一个话题,再
通过 GLM-5.1 的全面支持和 Gemini CLI 的成功集成,HagiCode 进一步强化了其作为多模型、多 CLI AI 编程平台的能力。这些更新不仅为用户提供了更多的选择,也展示了 HagiCode 在架构设计上的前瞻性和可扩展性。GLM-5.1 的图片支持能力,结合 HagiCode 的截图上传功能,让"看图说话"成为可能——大大降低了问题描述的成本。而十个 CLI 的支持,意味着用
当你在 Claude 里输入一个复杂主题时,得到的往往是一篇流畅但平滑的总结。它听起来全面,却总让人觉得缺了点什么——那些真正做决策、踩过坑、或者持怀疑态度的人会怎么看?这个缺口不是模型能力的问题,而是提问方式的问题。斯坦福 OVAL 实验室在 2024 年 NAACL 会议上发布的 STORM 系统,用实测数据证明了这一点:通过多视角提问构建的文章,在组织性和覆盖广度上显著优于常规方法。核心差异
我做论文写作科普这么久,见过太多同学把时间浪费在"找资料、理格式、纠结构"这些重复性劳动上,真正该花精力的思考和创新反而没时间做。把机械的活儿交给AI,把聪明的活儿留给你自己。它不是替你写论文,而是帮你把写论文这件事的"门槛"降到最低,让你把精力花在刀刃上。书匠策AI咱们下期见 👋。
书匠策AI不是替你写论文的,它是帮你过"最后一关"的。选题、框架、论证这些核心功夫还得你自己下。但在降重降AIGC这个让无数人崩溃的环节,与其一个字一个字熬到凌晨四点,不如让工具帮你把时间抢回来。微信搜一搜"书匠策AI",*,去试试。省下来的时间,够你多睡两个好觉了。咱们论文战场上见!💪。
在许多实际应用中,数据的复杂性和异质性对传统机器学习和信号处理技术提出了重大挑战。例如,在医学领域,有效分析多样的生理信号对患者监测和临床决策至关重要,然而却极具挑战性。我们介绍了MedTsLLM,一个通用的多模态大型语言模型(LLM)框架,它有效地整合了时间序列数据和丰富的文本形式的上下文信息来分析生理信号,执行三个具有临床相关性的任务:语义分割、边界检测和时间序列中的异常检测。这些关键任务能够
在新时代的背景下,科技创新已成为推动社会发展的核心动力。随着人工智能、大数据、云计算等技术的迅猛发展,我们的生活方式、工作模式乃至思维方式都发生了深刻的变化。科技创新不仅提升了生产效率,还为解决社会问题提供了新的思路和工具。
在金庸武侠小说《天龙八部》中,无崖子,作为逍遥派祖师的二弟子,也是逍遥派的第二任掌门。在接任逍遥派掌门后,因各种纠葛,遭到徒弟丁春秋的暗算,被推下山崖,虽侥幸不死,但几乎全身瘫痪,于是摆下珍珑棋局,希望能找到一个有大智慧的人,传下自己的毕生功力和绝学为自己清理门户。虚竹本是小少林僧人,武功低微且不通棋艺,因机缘巧合下,落下一子,自填一气导致大片白棋被提,意外破解棋局。无崖子看重虚竹的仁厚心性,决定
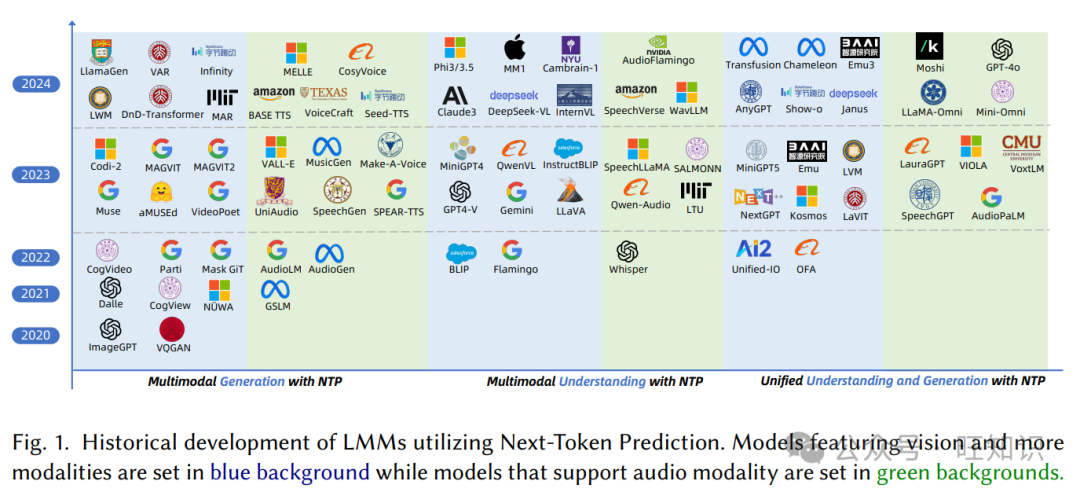
基于自然语言处理中语言建模的基础,下一个标记预测(NTP)已发展成为机器学习任务的通用训练目标,在各种模态中取得了相当大的成功。随着大型语言模型(LLM)在统一文本模态内的理解和生成任务方面取得进展,最近的研究表明,不同模态的任务也可以有效地封装在NTP框架内,将多模态信息转换为标记,并根据上下文预测下一个标记。本综述引入了一种全面的分类法,通过NTP的视角统一了多模态学习中的理解和生成。所提出的
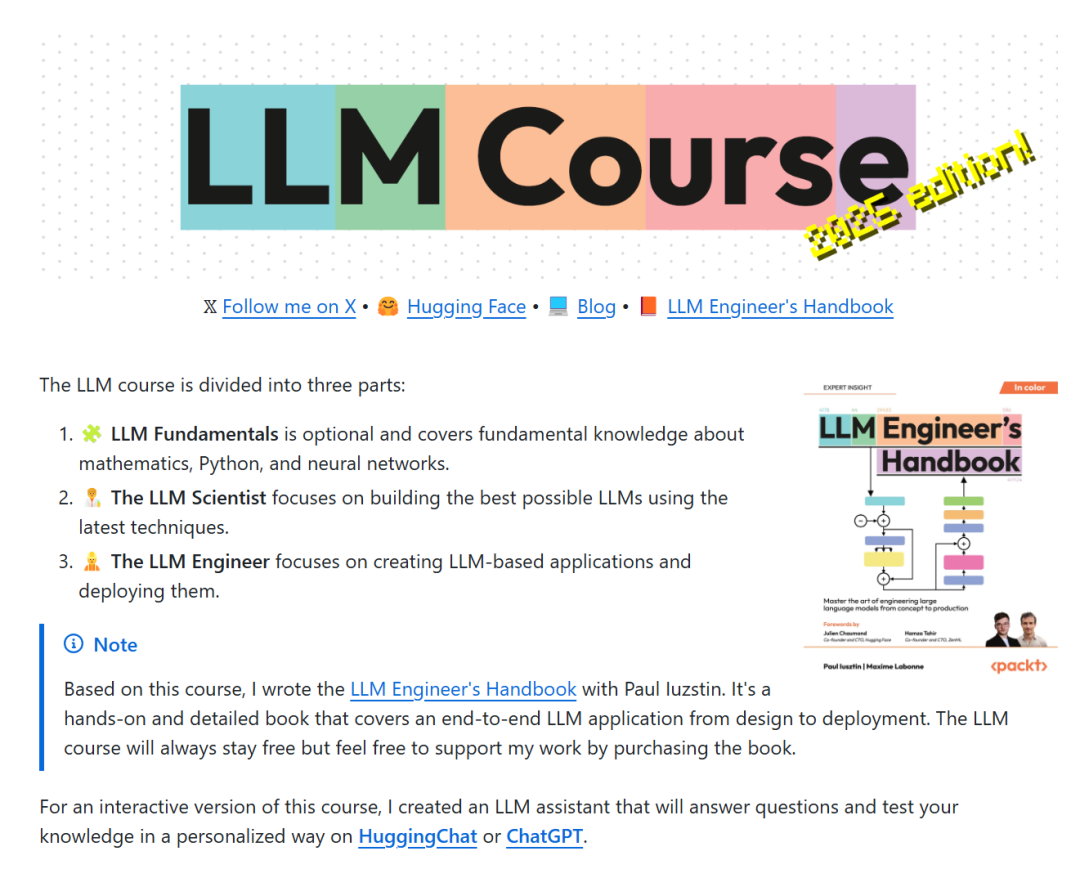
随着大语言模型(LLM)在多个领域的迅猛发展,越来越多的从业者和研究人员开始关注如何更高效地训练、评估以及优化这些复杂的模型。如果你也对 LLM 领域充满好奇,想要深入了解最新的趋势和技术,那么由资深的机器学习专家 mlabonne 更新并发布的全新绝不可错过!从基础的 LLM 训练开始,逐步深入到数据处理、模型评估、量化优化等领域,学习过程中结合实际操作和案例研究,加深对理论的理解。通过这份课程
未来,Storm UTP也将继续围绕客户真实痛点场景,深化AI大模型与测试管理的融合能力,推动平台从“可用、好用”进一步迈向“会思考、能协同、可执行”的智能化阶段。
养猫治愈生活,不该被过敏打断相伴的温柔。不必在挚爱猫咪和身体健康之间艰难二选一,不必硬扛过敏折磨委屈自己,也不必耗费大量时间精力无效防护。把猫毛过敏这件事交给AINIO抗猫毛过敏蛋片,日常温和养护、前置舒缓致敏反应,轻松提升身体耐受度。从此安心撸猫、安稳相伴,晨起呼吸通畅,居家自在舒心,让猫咪继续治愈日常,让热爱不负陪伴,养猫生活再也没有后顾之忧。
CSDN下载码的使用方法
采集层(Flume):多源接入、事务保证、可靠传输缓冲层(Kafka):削峰填谷、多订阅、持久化保障处理层(Storm/Flink):实时计算、状态管理、复杂事件处理架构演进趋势Storm → Flink:更强的状态管理和Exactly-once语义Flume + Kafka → Kafka Connect:简化链路实时数仓建设:流批一体成为主流选型建议简单实时计算复杂状态计算流批一体需求。
一到副歌,鼓组、贝斯、弦乐同时涌入,人声从气声转为强混声爆发,音域瞬间拉高,情绪从。你在蘑兔ai生成音乐的时候有没有发现一个问题,你生成的音乐旋律也很不错、歌词也朗朗上口,整体也是好听的。“【曲风】,副歌采用对称重复结构,每句以固定词开头,旋律循环往复,节奏型统一,营造强迫式记忆。“【曲风】,副歌以无意义音节为核心,歌词极简口语化,每句押同韵,旋律简单重复,一听就能跟着唱。“火火火火火”:这是全歌
甘遂的绘画洛本的绘画
Kafka 是一个高吞吐、分布式的消息队列系统,广泛应用于大数据流处理、日志收集、事件驱动架构等场景。在 Kafka 消费者组(Consumer Group)中,Rebalance(重平衡)是一个核心机制,用于在消费者组成员变化时重新分配分区。然而,当 Rebalance 频繁发生时,就会形成所谓的 Rebalance Storm(重平衡风暴),这会严重影响系统的性能和可用性。本文将深入分析 Re
随着实时数据处理需求的爆发式增长,Apache Storm作为分布式实时流处理框架的代表,在日志分析、实时监控、金融实时计算等场景中广泛应用。Storm核心组件的监控指标解析吞吐量、延迟、资源利用率等关键性能指标的关联关系基于监控数据的瓶颈定位方法论从拓扑设计到集群资源配置的全链路调优策略本文从原理层(核心概念、算法模型)→ 实践层(监控工具、调优步骤)→ 应用层(实战案例、场景分析)逐步展开,通
在实时流处理领域,是一对黄金搭档。Kafka 作为高吞吐的分布式消息队列,负责数据的缓冲和持久化;Storm 作为实时计算引擎,负责数据的处理和分析。两者的结合,构成了无数实时数据管道的核心。本文将深入剖析 Storm 与 Kafka 的集成原理,从基础配置到高级优化,帮助读者构建一个既可靠又高效的实时数据处理系统。默认情况下,KafkaSpout 会将 Kafka 记录转换为包含topicpar
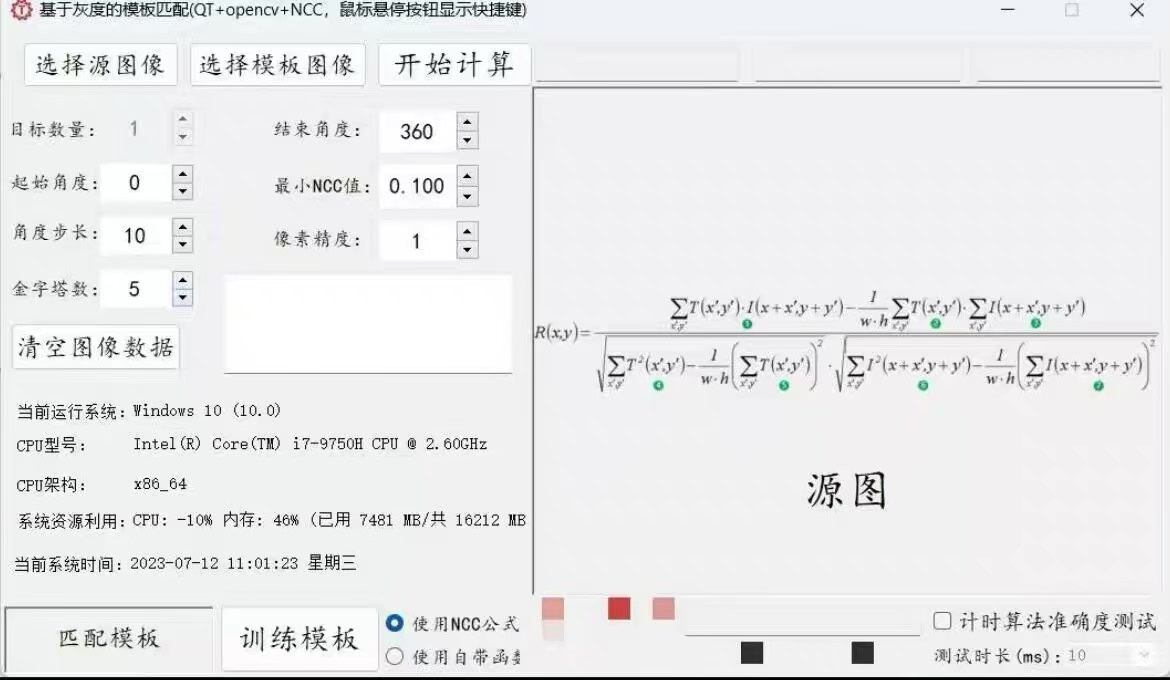
最近在折腾一个跨平台的模板匹配工具,核心用了OpenCV的C++接口和Qt框架做界面。这个项目主打灰度NCC模板匹配算法,实测在i5-12400上能做到单次匹配1毫秒出结果,顺手把Windows和Ubuntu双平台跑通了。先看效果:左边是640x480的源图,右边80x80的模板图,匹配过程直接甩到GPU跑完只要0.8ms(没错,连1ms都不到)。实测数据说话:在1080p图片中匹配100x100
Type-C接口的普及使各类设备供电接口实现统一,但不同适配器协议(如PD、QC等)与小家电功率需求存在匹配问题。XSP26芯片作为高性能Type-C受电端控制芯片,具备智能识别设备类型、支持多种快充协议(最高100W)以及与MCU协同工作的能力,可实时监测充电参数并灵活调控,为智能设备提供稳定高效的供电解决方案,有效解决了多协议适配器与小家电的兼容性问题。
目录1、编程模型2、并发度3、架构模型1、编程模型 DataSource:外部数据源; Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt; Bolt: 接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理,发送给下一个Bolt或者是存储到某种介质上,介质可...
假设你的hbase和hdfs的hadoop版本不同,但是我们的业务是将hbase的数据写入hdfs。该如何解决呢? 我们的方法是动态加载jar包。 1.Hbase和Hdfs分别定义借口HbaseInterface和HdfsInterface。 2.分别封装hbase和hdfs的方法生成相关jar包HbaseOperation.jar和HdfsOperation.jar。
storm
——storm
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵


 HarmonyOS开发者社区
HarmonyOS开发者社区

 AI Agent技术社区
AI Agent技术社区









 AI编程社区
AI编程社区

 智能体开发者社区
智能体开发者社区
 DeepSeek技术社区
DeepSeek技术社区

 AtomGit开源社区
AtomGit开源社区


 脑启社区
脑启社区




 腾讯云开发者社区
腾讯云开发者社区