- @Gaga246
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
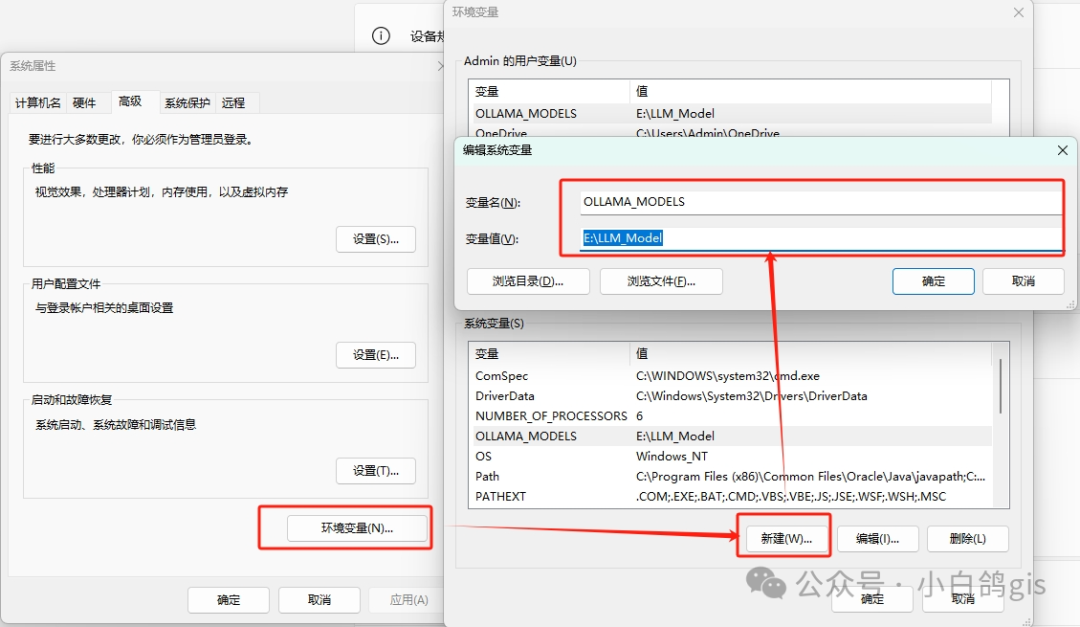
以 deepseek r1 模型为例:访问https://ollama.com/library/deepseek-r1,默认为 7b 模型,如需其他模型,可以在当前页搜索所需模型模型详情页复制安装命令ollama run deepseek-r1安装完成后在终端执行:

手把手教会你玩转本地大模型:Ollama安装+deepseek部署+Dify接入+独立调用全攻略
文章介绍了本地运行大语言模型的五种工具:Ollama、LM Studio、AnythingLLM、llama.cpp和Open WebUI。本地运行LLM具有隐私与控制、离线能力和成本与自由三大优势。Ollama适合快速设置,LM Studio适合探索实验,AnythingLLM可将LLM与个人文档连接,llama.cpp提供底层控制,Open WebUI提供美观的浏览器界面。文章强调,本地运行L
AI行业虽处低谷,但大模型相关岗位薪资普遍达40万+,就业前景看好。文章提供蚂蚁金服、华为等企业大模型岗位真实薪资案例,并分享全套学习资源包,包括学习路线、行业报告、经典书籍和商业方案。建议持续学习和实践,提升技能与认知,把握AI发展机遇。
35岁Java程序员老李被公司优化后,通过系统学习AI大模型技术,将Java与AI结合开发智能推荐系统,成功实现职业转型。他从零开始学习Python和机器学习,掌握深度学习框架,最终成为AI大模型开发工程师,薪资翻倍达40万。文章证明,在AI时代,Java程序员只要勇于学习新技术,年龄不是障碍,完全可实现职业逆袭和高薪梦想。

本文为Java开发者提供AI Agent转型指南,系统介绍AI Agent概念、与工作流的区别、核心组件(LLM、工具、记忆)及ReACT框架。详细解析工作流模式与Agent模式,深入探讨多Agent架构。文章不卖课,提供实用知识,帮助读者理解何时使用Agent、如何构建系统及避免常见陷阱,适合希望进入AI领域的Java开发者学习收藏。
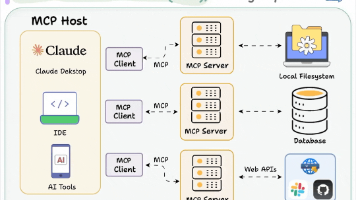
AI 智能体在企业落地过程中通过 MCP 标准协议获取数据,随着可用的 MCP 工具越来越多,逐步达到几十万个 MCP 工具,甚至几百万个,MCP 工具通过系统提示词注册给大模型时候,将会导致以下两个问题:
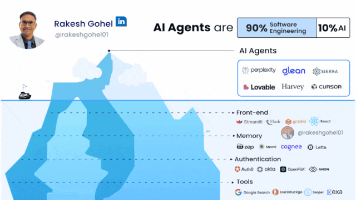
过去两年,AI智能体(AI Agent)成为AI落地的热门方向,从 ChatGPT 的对话助手,到自动化办公、代码助手,再到多智能体协作平台,智能体被视为未来人机交互的核心形态。随着越来越多企业已经落地+AI+智能体应用,我们会发现,AI智能体应用在企业落地90%的工作都是工程架构设计(软件工程),只有10%是真正的AI大模型。
会查资料的 Agent(Agentic RAG)不只是“问答”,而是像侦探一样边推理边实时翻资料。医院、法律、金融都在用,Perplexity、Harvey AI、Glean AI 都是例子
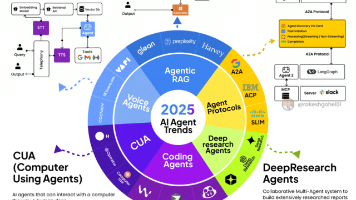
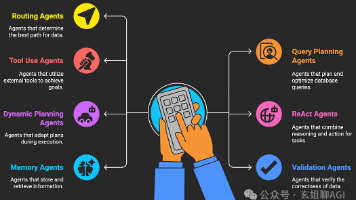
在检索增强生成(RAG)不断发展的世界中,并非所有 AI 智能体都生而平等。有些充当智能路由器,有些是总规划师,还有一些同时处理记忆、工具和逻辑。以下是一个关于智能 RAG AI 智能体类型的架构设计剖析,每种类型都配有实际用例,展示它们在实践中如何表现。