登录社区云,与社区用户共同成长
邀请您加入社区
文章摘要 本文介绍了如何基于Spring AI Alibaba框架和Harness Engineering理念构建可控的AI智能体。Harness Engineering是一种新兴的AI工程化范式,强调为AI智能体构建可靠、可控的运行环境("马具"),而非仅优化模型本身。文章详细阐述了Harness Engineering的关键组件(规则、技能、门禁等),并提供了Windows环境下的实践指南,包
Java 后端接入大模型时,应通过 AI Gateway 建立统一服务边界,集中处理模型路由、权限、脱敏、成本、日志和错误分类。把模型调用当成可治理的企业级依赖,才能支撑长期演进。
Redis能准确解释 SDS 如何通过预分配策略减少内存重分配(如长度 < 1MB 时预分配一倍空间)。说明跳跃表与平衡树的适用差异(跳跃表适合范围查询,平衡树适合单点查询)。监控区分 Actuator 过滤器与 AOP 的作用范围(过滤器捕获所有 HTTP 请求,AOP 专注 Controller 方法)。解释micrometer如何支持多监控系统(如同时输出指标到 Prometheus 和 I
点击关注公众号,利用碎片时间学习1. Sa-Token 介绍Sa-Token 是一个轻量级 Java 权限认证框架,主要解决:登录认证、权限认证、单点登录、OAuth2.0、分布式Session会话、微服务网关鉴权 等一系列权限相关问题。功能结构图2. 登录认证对于一些登录之后才能访问的接口(例如:查询我的账号资料),我们通常的做法是增加一层接口校验:如果校验通过,则:正常返回数据。如果校验未通过
将resources目录文件拷出的临时容器拷出后,修改,然后有以下两种解决方案:Seata 注册中心和配置中心配置支持 file,nacos, consul, apollo, zk, etcd3 等,可以参考从容器拷贝下来的官方yaml配置文档,下面是配置nacos的application.yml参考:至此,Seata服务端(TC)已经配置并启动成功了。查看Seata启动日志:配置Seata客户端
本文深入解析了Seata分布式事务框架,涵盖AT和TCC两种核心模式。AT模式通过undo_log和全局锁机制实现零侵入的事务管理,适合常规业务场景;TCC模式通过Try-Confirm-Cancel三阶段实现高性能事务控制,适用于高并发场景。文章详细介绍了环境搭建、电商案例实战,并针对生产环境常见问题提供了解决方案,包括数据源代理、事务回滚、性能优化等关键点。最后强调了版本兼容性、TC集群部署和
前言上篇博文中写道,Seata是将全局事务划分为若干个分支事务来解决分布式事务,分支事务(branchID)和全局事务(...
分布式 ID;分布式 ID 的基本要求;数据库主键自增;UUID;雪花算法;
Java简介Java是一种面向对象的静态式编程语言。Java编程语言具有多线程和对象定向的特点。其特点是根据方案的属性将方案分为几个不同的模块,这些模块是封闭的和多样化的,在申请过程中具有很强的独立性。Java语言在计算机软件开发过程中的运用可以达到交互操作的目的,通过各种形式的交换,可以有效地处理所需的数据,从而确保计算机软件开发的可控性和可见性。开发java语言时,保留了网络接口,Java保留
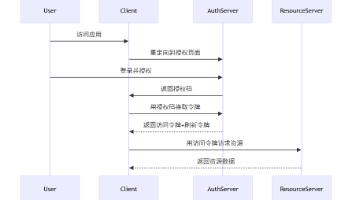
Spring Security OAuth2.0 为分布式系统提供了一套成熟、安全、可扩展的认证授权解决方案,通过标准化的授权流程与模块化的架构设计,有效解决了微服务、前后端分离等场景下的身份认证难题。掌握这一技术,是构建企业级分布式系统安全架构的关键一步,也是现代 Java 后端开发者必备的核心能力。
✅DeepSeek-V4-Flash 免费用—— 284B 参数,终端无限调用✅GLM / Qwen 等国产模型都支持—— 不翻墙,低成本✅开源免费—— MIT 协议,无需订阅✅Claude Code 平替—— 日常开发完全够用。
依赖如下/*** GraalVM 沙箱环境执行 Python 代码的工具* 安全沙箱:禁用文件IO、进程创建、本地访问*/- 代码必须为合法Python语法- 沙箱执行,安全无风险- 支持返回数字、字符串、数组、执行结果""";.build();/** 构建Spring AI 标准工具回调 */.build();@Overridereturn "Error:Python代码不能为空";// 沙箱环
Spring AI Alibaba Admin 是阿里巴巴开源的 AI Agent 一站式管理平台,已合并进 spring-ai-alibaba 主仓库(10k+ Stars)。它解决了 Java 开发者在 Agent 上线后面临的三大痛点:Prompt 迭代效率低、效果无法量化、线上问题难排查。平台提供多智能体编排(Sequential/Parallel/Routing/Loop)、上下文工程、
在本篇技术博客中,我们介绍了如何使用Java和DJL来加载、使用和部署机器学习模型。在上面的代码中,我们使用了一个名为Mlp的基本模型,该模型是一个简单的多层感知器,用于图像分类。我们还使用了一个名为MyTranslator的自定义翻译器,用于将输入数据转换为模型所需的格式,并将输出数据转换为可读的结果。在上面的代码中,我们使用Model的save方法将模型保存到磁盘上。注意,我们需要设置模型的块
来源: blog.csdn.net/Gaowumao?type=blog前言 想自己搞一个人脸识别玩玩,随着开始查找资料来研究这方面的信息,还好有好几家公司都有提供这方面的免费API,也是省下来很多功夫。一开始采用的是face++,但是在执行到最后一步人脸搜索时出现问题,一直提示INVALID_OUTER_ID,跟着官方文档,一步步抽离再封装,最终还是以失败告终,无奈只能...
在过去的两年里,大语言模型(LLM)以惊人的速度渗透到了软件开发的每一个角落。从 ChatGPT 的横空出世,到如今各类 AI 原生应用的遍地开花,开发者面临的核心挑战已经悄然发生了变化 —— 不再是"能不能调用一个 AI 模型",而是"如何将 AI 模型与企业的现有数据、业务系统、API 体系深度融合,构建出真正有价值的生产级应用"。
Spring AI 是 Spring 官方推出的 AI 集成框架,定位类似于 Spring Data、Spring Security —— 不是你重新发明轮子,而是在你熟悉的 Spring 生态里加一块 AI 拼图。Java 开发者在 AI 时代不需要焦虑。你会的 Spring Boot、MyBatis、Redis、MQ、微服务体系……这些不是包袱,是企业级 AI 落地最稀缺的能力。
spring
——spring
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 CSDN-OPC开发者社区
CSDN-OPC开发者社区

 MCP技术社区
MCP技术社区

 深开鸿 技术专区
深开鸿 技术专区









 DeepSeek技术社区
DeepSeek技术社区

 龙虾开发者社区
龙虾开发者社区


 DAMO开发者矩阵
DAMO开发者矩阵



 AtomGit AI 社区
AtomGit AI 社区
