登录社区云,与社区用户共同成长
邀请您加入社区
云主机服务器已从基础虚拟化升级为智能业务操作系统,通过软硬协同技术释放算力,实现高峰场景稳定运行。其核心价值在于弹性资源调度与精准成本控制,以及硬件级安全防护与AI驱动的智能运维。云主机与AI深度融合,具备自感知与决策能力,让企业聚焦核心业务,以轻量化架构应对数字化竞争,成为跨越发展周期的关键技术底座。
道本鹰眼审查矩阵的解法是:把每一次审查中产生的审核意见——业务提的、法务改的、财务补的——全部采集下来,用DeepSeek持续训练,转化为可调用的审查逻辑。下一个人处理同类合同时,系统会自动提示“上次类似的条款是这样改的,原因是……同类错误,不同的人在同样的条款上反复栽跟头。这不是能力问题,是机制问题——经验附着在人身上,人走了,知识就断了。道本的做法:合同起草时自动提取履约节点,签订时复核确认,
AI一体机+超融合(4合1)数据库,国内领先,超高效数据处理,构建您公司AI的自有空间,保护企业核心数据机密,不让您在AI时代裸奔
微软官方发布的 Visual FoxPro 6.0 简体中文完整安装介质,支持 Windows 95/98/NT 等旧版操作系统。内含主程序 VFP6.EXE、可视化界面构建器 BUILDER.APP、模板资源管理器 GALLERY.APP、中文帮助核心文件(FOXHHELP.DLL、HLP95EN.DLL)、本地化字体(FOXFONT.850/852)、OLE 集成组件 FPOLE.DLL 和
更重要的是,履约数据会反馈回前面的环节:哪些条款在履约中经常出问题、哪些供应商承诺的和交付的不一致、哪些业务单元的合同执行偏差最大——这些信息会反向优化合同范本和审查重点。每一次审查中的审核意见——业务提了什么诉求、法务标注了什么风险、财务关注了什么成本——不再停留在邮件和批注里,而是被系统自动采集,沉淀为审查知识库的一部分。当合同被拆解成可计算的要素后,比对、审查、统计就有了统一的基础。道本科技
巧妙的数据关联设计(预约挂号、就诊等和医生、患者、排班均有巧妙的关联)患者就诊:叫号后可以对患者进行就诊,可以填写医嘱病历。患者挂号信息:可以查看挂自己号的患者挂号信息。患者挂号管理:管理所有患者挂号的信息。
我申请的社团:可以查看自己的所有申请记录。社团成员管理:管理所有社团的成员信息。社团资讯管理:管理所有社团的资讯信息。社团评论管理:管理所有社团的评论信息。查看社团资讯:可以查看各种社团的资讯。查看社团信息:可以查看各种社团的信息。
博客分类管理、博客管理、评论管理、活动管理、活动报名管理、公告管理、管理员管理、用户管理、个人信息、修改密码。博客搜索:可根据关键字搜索博客。
C++20协程通过引入三个关键关键字(co_await、co_yield、co_return)和相关的底层机制,为异步编程提供了全新的解决方案。随着C++20标准的正式发布,协程(Coroutines)作为最重要的新特性之一,彻底改变了C++处理异步编程的方式。这一革新使得开发者能够以近乎同步的代码风格编写高效的异步操作,将我们从传统的回调地狱中解放出来。未来的C++标准可能会进一步简化协程的使用
摘要:本项目基于C++开发了一套疫苗接种和儿童体检管理系统,旨在实现儿童健康信息的数字化管理。系统采用分层架构设计,包含数据层、业务逻辑层、接口层和用户交互层,支持儿童档案管理、疫苗接种登记、体检数据录入、智能预警、统计分析等功能模块。通过高效的数据结构和多线程处理机制,系统能够应对大规模数据存储和高并发访问需求。项目严格遵循数据安全规范,采用加密存储和权限控制机制,支持多角色分级管理。系统可应用
本文介绍了一个基于C++的民族婚纱预定系统设计与实现项目。该系统旨在解决传统民族婚纱预定过程中存在的信息获取不畅、服务效率低下等问题,通过数字化手段优化预定流程,支持个性化定制和文化表达。系统采用多层架构设计,包含用户管理、婚纱资源管理、订单排期、商家调度等核心模块,并实现了智能排期冲突检测、高并发处理、数据分析等功能。项目展示了完整的开发流程,包括需求分析、模型架构设计、数据库实现、API接口规
本文介绍了一个基于C++的工地人力资源管理系统平台的设计与实现。该系统采用模块化架构,包含工人信息管理、考勤管理、薪酬管理、合同管理等核心功能模块,通过智能硬件集成实现工地人员全生命周期的数字化管理。系统采用分层设计,包括表现层、业务逻辑层、数据访问层和数据持久化层,支持跨平台部署和多终端访问。关键技术包括C++高性能开发、数据库操作封装、RESTful API设计、数据安全和隐私保护机制等。项目
本文介绍了一个基于C++的线上测评系统的设计与实现。该系统采用分层架构,包括前端展示层、业务逻辑层、数据管理层和安全控制层,支持用户注册登录、题库管理、代码提交、自动编译、安全沙箱运行、测试用例比对和结果反馈等功能。系统采用MySQL数据库存储数据,通过多线程并发处理和资源调度优化保障高并发性能,并利用沙箱机制确保代码运行安全。主要功能模块包括用户管理、题库管理、代码提交与评测、成绩统计等,适用于
典型应用:TiKV的Rust实现已验证该架构支持$ \text{100k+ TPS} $,P99延迟$ < \text{10ms} $。核心在于通过Rust的内存安全特性,将传统数据库需用$ \text{锁} $实现的并发控制转化为编译期保障的并发原语。$$ \text{网络分区时} \rightarrow \text{选择C(一致性)} $$ $$ \text{正常运行时} \rightarro
通过持续跟踪C++标准演进(如C++23的动态成员初始化等特性),结合历史沉淀的优化智慧,我们能在性能与可维护性间找到最佳平衡点。最终,真正的高效编程,是将技术建筑在对计算本质的理解之上。// 需手动delete。| `std::unordered_set` | O(1)平均 | 不支持|| `std::vector` | O(1)(尾部) | O(1)|valgrind --tool=cache
它用图计算的坚实骨架,撑起了大模型的柔软身躯,最终构建出真正适用于企业级生产的、可控的AI智能体系统。这个模型天然契合了AI智能体工作流的特性:每个节点是一个处理单元(如调用LLM、执行工具),节点间的连接定义了工作流路径,而整个流程的推进就是通过节点间的“消息”来驱动的。在LangGraph中,State是一个全局的、共享的、可持久化的上下文对象。它贯穿整个工作流的生命周期。在最新的LangGr
根据DIKWP模型,实体需通过数据层(传感器采集)→信息层(语义解析)→知识层(逻辑推理)→智慧层(策略生成)→意图层(伦理对齐)实现闭环。· 数据需具备几何结构、材质属性、动态交互关系的精确描述,例如3D铰接数据可刻画门的合页转动轨迹,形成“可计算的物理结构模型”。演化驱动力:智能体的进阶源于“黑洞效应”——更聪明的智能体吸引更多用户,产生更多私有数据,进一步强化模型,形成正向飞轮。· 例如,天
本文介绍了基于Spring Boot 3和纯JDBC实现的宠物管理系统CRUD操作。通过原生JDBC方式,不使用任何ORM框架,帮助开发者深入理解底层数据库操作原理。文章详细说明了环境准备(JDK17+、Spring Boot 3.2.x、MySQL 8.0)、项目依赖配置、数据库连接设置以及表结构创建。核心实现包括:Pet实体类定义(包含id、name、breed和age字段)以及PetServ
AI产品经理作为技术与市场的关键纽带,其重要性在AI时代日益凸显。这一岗位不仅要求多维度的技能组合,更需要对技术发展趋势的敏锐洞察和对人类需求的深刻理解。尽管挑战不小,但对于有志于在AI浪潮中扮演关键角色的专业人士而言,这无疑是一个充满机遇的黄金赛道。随着AI技术逐渐渗透到各行各业,AI产品经理的需求将持续增长,能力要求也会不断演进。保持好奇心、持续学习、平衡技术理想与商业现实,将是每一位AI产品
摘要:本文为实习生提供利用DeepSeek AI工具高效生成周报与任务汇报的实用指南。文章详细介绍了结构化提示词技巧、标准化模板设计(包含6种周报/汇报模板)、数据量化方法及不同岗位应用案例,同时强调AI生成内容的优化要点与使用伦理。通过模板化框架与精准信息输入,实习生可快速生成专业报告初稿,节省时间的同时确保内容质量,实现高效职场沟通与个人能力展示。指南特别指出需保持内容真实性,AI仅作为辅助工
HR智能体,更像是一位懂业务、可协作的“数字同事”、“数智员工”、“eHR服务助手”。HR智能体正在通过自动化、数据驱动和智能化决策,显著提升人力资源管理系统的效率与战略价值。
本文探讨了利用DeepSeek大型语言模型从电子病历(EMR)生成结构化诊疗建议模板的技术方案。针对传统自由文本EMR存在的结构化程度低、信息提取困难等问题,研究提出了基于DeepSeek的多步骤处理流程:包括数据预处理、关键信息提取、诊疗逻辑推理、结构化模板生成和医生审核确认。该方案能显著提升临床工作效率,促进诊疗规范化,同时面临医学知识准确性、临床推理个性化、数据隐私保护等挑战。应用场景涵盖门
HR智能体正在通过自动化、数据驱动和智能化决策,显著提升人力资源管理系统的效率与战略价值。科艺嘉eHR平台定制开发了多个HR智能体插件...
UniApp+ThinkPHP6技术方案提供了一套多端圈子系统,解决社交场景中信息过载、用户关系浅层、第三方工具权限受限等问题。系统支持圈子分层(公开/私密)、内容互动(图文/评论/活动)、同城LBS服务、积分激励及商业化变现(付费入圈、打赏等),适用于本地生活、行业社群、兴趣圈层、校园社区等场景。技术层面,UniApp实现多端适配,ThinkPHP6保障后端高效运行,部署便捷,助力开发者快速搭建
本文详细介绍了如何使用C#和ADO.NET构建图书管理系统,从环境准备、数据库设计到核心功能实现。通过实战案例展示了登录模块、图书管理、借阅功能和报表统计的开发过程,并提供了数据库连接管理、事务处理和性能优化的实用技巧,帮助开发者快速掌握数据库应用开发。
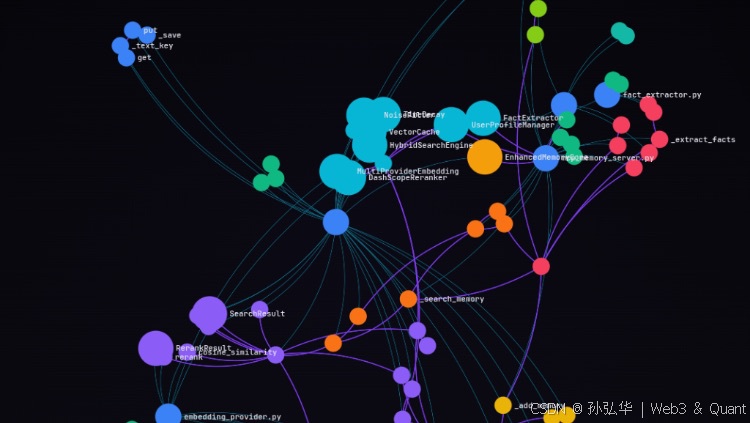
如果用市面上的云端记忆 API(比如 Mem0、Supermemory),不仅要交昂贵的月租,更致命的是——公司的核心代码和你的个人画像,全成了别人服务器上的训练语料。作为一个对代码隐私有极度洁癖的独立开发者,我决定自己动手,基于最新的 MCP(Model Context Protocol)协议,手搓一个完全本地化、零云端依赖的记忆引擎——Ninetail-Fox (九尾狐) V4.5。这绝对是你
湖南万物工业软件作为工程智慧工地源头厂商,全套产品完全对标 JTG/T 3603—2026 规范,覆盖公路、铁路、水利基建场景,自研物联网底层,各模块数据互通,无需多平台拼接
Amazon DocumentDB 是 AWS 提供的一种完全托管的、兼容 MongoDB 的文档数据库服务。它专为云原生环境设计,通过将存储与计算分离的架构,提供高性能、高可用性和可扩展性,同时保持与 MongoDB 3.6、4.0 和 4.2 版本 API 的高度兼容。Amazon DocumentDB 为需要在 AWS 上运行 MongoDB 工作负载的用户提供了强大的托管解决方案。它结合了
虚拟机创作
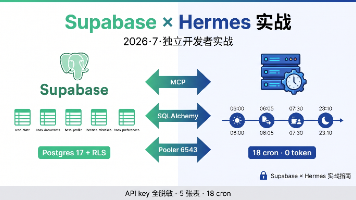
在生产环境跑通 Supabase + Hermes 全栈的真实踩坑记录, 包含 5 张表 RLS 启用、16 个 cron 任务调度、Pooler vs Direct Connection、MCP read-only 模式突破等 8 大实战要点, 适合不想被运维绑架、又想用 SQL 表达力的中小团队和独立开发者。文末附踩坑对照表 + 实战效果数据, 全部代码可即拿即用, API key 全程脱敏。
本文全面介绍了Python操作SQLite数据库的开发指南,从基础概念到GUI实战应用。主要内容包括:SQLite轻量级嵌入式数据库的特性与优势;Python标准库sqlite3模块的基本使用方法,涵盖数据库连接、表创建、CRUD操作等核心功能;PySide6框架与SQLite的集成开发;以及数据库可视化工具推荐。文章提供了参数化查询、事务处理、面向对象封装等最佳实践,并包含完整的代码示例,适合P
本文介绍了如何使用CCJSqlParserUtil工具快速解析和改写Java项目中的SQL语句,避免手动处理SQL的复杂性和错误。通过实际案例和代码示例,展示了该工具在动态SQL修改、敏感字段脱敏等场景下的高效应用,显著提升开发效率和代码可维护性。
本文系统总结了《MySQL数据库技术》课程学习内容,将SQL语句分为DDL、DML、DCL、TCL四大类,详细介绍了各类语句的语法规范、使用场景和常见易错点。重点包含:数据库/表创建规范、DML增删改查操作、条件查询与聚合函数、多表连接查询、数据约束和事务控制等内容,并针对UPDATE/DELETE误操作、WHERE与HAVING混淆等常见问题给出解决方案。文章强调SQL编写规范(如使用utf8m
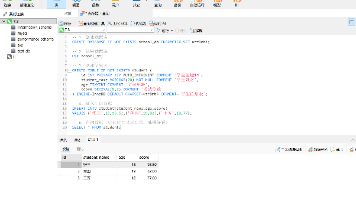
本文实现了一个数据库连接池管理器ConnectionManager,用于管理最多10个Connection对象。主要特点包括:1) 使用UUID为每个Connection生成唯一ID;2) 客户端只能通过ConnectionManager获取连接对象;3) 当连接数未达上限时返回新连接并提示ID,否则提示无空闲连接;4) 提供释放连接功能。测试代码模拟了15次连接请求(仅前10次成功),释放3个连
数据库开发
——数据库开发
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 DeepSeek技术社区
DeepSeek技术社区

 2048 AI社区
2048 AI社区
 AMD开发者中国社区
AMD开发者中国社区

 AI Agent技术社区
AI Agent技术社区





















 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 MCP技术社区
MCP技术社区