登录社区云,与社区用户共同成长
邀请您加入社区
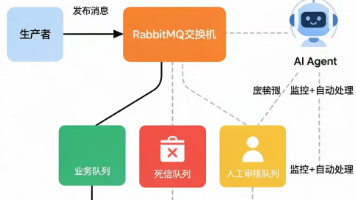
消费者挂了→ 告警运维重启。消费者正常但消息量突增→ 临时扩容消费者。用过RabbitMQ的都知道,最烦的不是搭建,是日常运维。三个关键设计:智能重试区分故障类型、MCP Tool标准化运维操作、死信自动分析减少人工排查。我们试了一个方案:把RabbitMQ的管理操作包装成MCP Tool,让AI Agent盯着队列状态,发现问题自动处理。消费者处理失败抛异常 → Spring默认重新投递 → 再
概念确认发布就是用来保证生产者在发送消息到mq的过程中防止消息丢失的一种机制。发送方发消息给接受方一旦接收方接到消息后通知发送方,如果发送方设置了持久化那么接受方会在消息成功持久化后在通知发送方。消息确认的策略消息的确认做有很多法,其中包括单条确认、批量确认、异步确认等。单条确认:它是一种同步确认发布的方式,也就是发布一个消息之后只有它被确认发布,后续的消息才能继续发布,waitForConfir
摘要:三种主流MQ产品对比:RabbitMQ界面友好、功能全面,适合中小型项目;RocketMQ由阿里开源,高吞吐高可靠,适用于电商金融等高并发场景;Kafka专为日志收集设计,吞吐量最高,适合大数据处理。主要区别:吞吐量Kafka(百万级/s)>RocketMQ(十万级/s)>RabbitMQ(万级/s);可靠性RocketMQ>RabbitMQ>Kafka。
这款工具的优势是和AWS云服务的集成度非常高,如果团队的业务系统全部部署在AWS上,它可以直接生成适配云原生架构的部署代码,自动生成S3、Lambda等云服务的对接逻辑,但是它的国内访问速度不稳定,中文支持比较一般,免费版的功能限制比较多,付费版的成本也偏高,更适合出海的企业团队使用,对于国内绝大多数业务部署在国内云平台的团队来说,它的适配性不如国产AI编程工具。当不同人群开始按场景选择不同的 A
其他场景还包括政务云、智慧城市、互联网服务、能源管理和交通出行等。中游是绿色算力服务的核心环节,主要由云服务商、数据中心运营商、AI算力平台、高性能计算平台和算力调度服务商提供算力租赁、云计算服务、AI算力服务、高性能计算服务、算力调度、能效优化、运维管理和碳排放监测等服务。生成式AI、智能客服、自动驾驶、工业视觉、医学影像、金融风控等场景对GPU集群、智算中心和高密度数据中心的需求快速增加,但A
std::future 是 C++11 标准库中的一个模板类,它表示一个异步操作的结果。当我们在多线程编程中使用异步任务时,std::future 可以帮助我们在需要的时候获取任务的执行结果。std::future 的一个重要特性是能够阻塞当前线程,直到异步操作完成,从而确保我们在获取结果时不会遇到未完成的操作。
目录秒杀/高并发方案-介绍秒杀/高并发解决方案+落地实现 (技术栈: SpringBoot+Mysql + Redis +RabbitMQ +MyBatis-Plus +Maven + Linux + Jmeter )-01分布式会话 Session 共享加密密码设置注解自定义校验全局异常处理定义分布式 Session共享分布式 Session 共享 详解分布式 Session 解决方案 1-Sp
本篇文章讲述了rabbitmq的简单使用和介绍,供大家和本人在日常开发中进行参考。
1.Springboot默认MQ支持rabbitmq或者kafka。在网页控制台能看到大量的消息进入了队列。默认用户名密码都是guest。propertis添加配置。queue增加一个test。docker启动服务器。
本项目是参考网上资料,整理开发而成,项目代码中加入了自己的理解和实现。基于SpringBoot框架开发,实现的功能主要是登录、商品列表、商品详情、秒杀商品,订单详情等功能,涉及异步下单、热点数据缓存、解决超卖等技术实现。在系统业务处理中,使用到分布式session维持会话、Redis预减库存降低数据库访问压力,消息队列异步下单(削峰)、客户端轮询结果、接口限流防刷等技术。
介绍RelayMQ的核心类和通用操作(序列化和反序列化)
本文介绍了 RabbitMQ 的安装与使用,包括其工作原理、安装步骤、客户端库安装及 AMQP-CPP 的使用方法。还提供了基于 C++ 的简单封装示例,方便项目中使用。
SQLite数据库操作,封装创建数据库和删除数据库,交换机,队列,绑定的增删查操作
RabbitMQ入门指南:解耦与异步通信的利器 RabbitMQ是一个强大的消息队列系统,解决了传统同步调用模式中的性能瓶颈、脆弱性和扩展性问题。通过将RabbitMQ作为"智能邮局"置于系统中间,实现了服务间的解耦、异步通信、削峰填谷和可靠性保障。RabbitMQ包含生产者、消费者、交换机、队列和绑定等核心组件,支持Fanout(广播)、Direct(精确匹配)和Topic(
实现数据从硬盘加载进入内存过程 和内存数据的存储和管理
springboot rabbitmq 延时队列消息确认收货订单已完成
介绍虚拟机中对数据的管理封装和交换机的匹配规则
介绍消息的发送到生产者消费流程, 以及自动应答和手动应答的两种应答方式
介绍网络通信模块--自定义网络协议解决粘包问题和Socket协议通信
该项目提供完整的学生管理系统源码及配套文档,包含前后端代码和SQL脚本。采用Java语言开发,基于SSM+SpringBoot+Vue技术栈,搭配MySQL数据库,支持IDEA/Eclipse开发环境。资源包括:LW/PPT/开题报告等文档、远程调试控屏包、项目演示视频及运行截图。有需要者可联系文末名片获取全套资料。
本文提供完整的Java项目资源包,包含前后端源代码、SQL脚本、论文文档(LW+PPT+开题报告)及远程调试服务。项目采用主流技术栈:Java+SSM+SpringBoot+Vue+JSP+MySQL,开发工具为IDEA/Eclipse。附项目演示视频和运行截图,有需要者可联系文章下方名片获取全套资料。
【项目资料领取】提供基于Java的完整项目资料包,包含前后端源代码、SQL脚本及配套文档(论文+PPT+开题报告)。采用SSM+SpringBoot+Vue技术栈,支持JSP页面和MySQL数据库,适用IDEA/Eclipse开发。含演示视频、运行截图及远程调试服务,有需要者请通过文末联系方式获取。(98字)
【项目资源领取】提供Java+SSM+SpringBoot+Vue开发的全套源代码(含前后端+SQL脚本)、配套文档(论文+PPT+开题报告)及远程调试服务。技术栈包含JSP、MySQL,支持IDEA/Eclipse开发环境。附项目演示视频及运行截图,有需要者可联系文末名片获取完整资源包。(95字)
【项目资源领取】提供完整Java项目资源包,包含前后端源代码、SQL脚本及配套文档(论文+PPT+开题报告)。采用主流技术栈:SpringBoot+SSM+Vue+MySQL,支持IDEA/Eclipse开发。附演示视频、项目截图及远程调试服务。需要领取的同学请联系文章底部联系方式。(98字)
【项目资源领取】提供基于Java+SSM+SpringBoot+Vue的完整项目源码(含SQL脚本),配套论文、PPT、开题报告及远程调试服务。技术栈包含JSP、MySQL,开发工具支持IDEA/Eclipse。附项目演示视频及运行截图,资源领取请查看文末联系方式。(94字)
【项目资料领取】提供完整Java项目源码(前后端+SQL)、配套文档(论文/PPT/开题报告)及远程调试服务。技术栈涵盖:SSM/SpringBoot+Vue/JSP+MySQL,支持IDEA/Eclipse开发环境。包含项目演示视频及运行截图,需要的同学可通过文末联系方式获取资料包。(注:含LW/PPT等学术文档)
该项目提供完整的Java前后端开发资料,包含源代码、SQL脚本及配套文档(论文、PPT、开题报告)。采用SSM+SpringBoot+Vue技术栈,支持JSP页面和MySQL数据库,使用IDEA/Eclipse开发环境。提供项目演示视频、运行截图及远程调试服务。需要者可联系文章底部获取资源。技术涵盖Java、Vue、MySQL等主流框架。
问题解决方案关键代码/配置消息丢失生产者Confirm + 持久化消息丢失消费者手动ACK消息重复消费者幂等性 (如Redis)提取业务ID,, 执行业务或忽略,basicAck消息积压增加消费者启动多个消费者实例消息积压设置合理Prefetch Count消息积压优化消费者业务逻辑优化数据库、减少IO、并行化处理消息积压监控队列长度(非代码) RabbitMQ Management UI / P
标准库提供的主要智能指针包括unique_ptr、shared_ptr和weak_ptr,每种都针对特定所有权场景设计。明确所有权语义:单一所有权用unique_ptr,共享所有权用shared_ptr并注意循环引用。unique_ptr几乎无额外开销,性能与裸指针相当。在性能敏感场景中,应优先选择unique_ptr,仅在确实需要共享所有权时使用shared_ptr。它主要用于解决shared_
多个shared_ptr可以指向同一对象,内部维护一个引用计数器,当新的shared_ptr指向该对象时计数器增加,当某个shared_ptr被销毁时计数器减少。std::weak_ptr是对std::shared_ptr的补充,它提供对共享资源的非拥有式引用。它主要用于解决shared_ptr可能产生的循环引用问题,通过weak_ptr可以检测所指向的对象是否仍然存在,从而安全地访问资源。任何时
RabbitMQ 是一个由 Erlang 语言编写的 开源消息中间件,实现了 AMQP(Advanced Message QueuingProtocol,高级消息队列协议)。它的核心作用是:在分布式系统中传递消息,实现 解耦、异步、削峰填谷 等功能。RabbitMQ 既可以部署在本地,也可以运行在云端,支持多种编程语言客户端。RabbitMQ 就像一个“快递中转站”,生产者把包裹交给它,它根据规则
摘要:该项目提供完整的Java Web开发源码及配套资料,包含前后端源代码、SQL脚本、论文文档(LW+PPT+开题报告)等。采用主流技术栈:Java+SSM/SpringBoot+Vue/JSP,MySQL数据库,支持IDEA/Eclipse开发环境。附赠项目演示视频、运行截图及远程调试服务。需要获取资源的同学可通过文末联系方式领取。项目展示了完整的Web系统开发流程,适合学习企业级应用开发技术
本项目提供完整的Java前后端开发资源包,包含SSM+SpringBoot+Vue框架实现的全套源代码、SQL脚本及配套文档(论文+PPT+开题报告)。技术栈采用Java语言开发,整合JSP页面与MySQL数据库,支持IDEA/Eclipse开发环境。资源包内附项目演示视频、运行截图及远程调试指导,有需要者可联系获取。
本文旨在为开发者和架构师提供一套完整的解决方案,用于构建基于RabbitMQ的大数据语音识别实时流处理系统。RabbitMQ在实时流处理中的核心作用语音识别数据处理流程的特殊性高并发场景下的系统设计考量实际生产环境中的最佳实践背景介绍:建立基本认知框架核心概念:RabbitMQ与语音识别的关键要素系统架构:整体解决方案设计算法实现:核心处理逻辑详解实战案例:完整项目演示应用场景:行业解决方案分析工
Parallel类为数据并行和任务并行提供了强大支持,能够自动管理线程池中的线程,优化资源利用率。这些高级抽象使得开发者能够更专注于业务逻辑,而不是底层线程管理的细节,显著提高了开发效率和应用程序的可靠性。在多线程编程中,理解线程的基本概念是至关重要的。然而,直接使用底层线程操作需要开发者手动处理线程同步、资源竞争等复杂问题,这增加了编程的复杂性。async修饰符表示方法包含异步操作,await运
从智能指针到RAII原则,现代C++提供了一套强大而优雅的内存管理工具链。通过将资源管理的责任从程序员转移给对象生命周期,这些技术显著提高了代码的健壮性、可读性和可维护性。理解和熟练运用这些现代内存管理技术,是编写高质量、无资源泄漏的C++程序的关键。
本文详细介绍了RabbitMQ在Windows环境下的安装配置及使用指南。主要内容包括:1)从官网下载安装包;2)启用管理插件并访问Web管理界面;3)配置远程访问用户;4)管理界面的核心功能使用;5)常见问题解决方案;6)C#客户端RabbitMQ.Client的使用方法,包括连接建立、消息发送和接收的实现。特别强调了消息持久化和手动确认机制的重要性,确保消息可靠性。该指南为开发人员提供了完整的
《Java项目资源分享》摘要 本项目提供基于Java的完整开发资源包,包含SSM+SpringBoot+Vue前后端源码、SQL脚本及配套文档(论文+PPT+开题报告)。技术栈涵盖JSP页面、MySQL数据库,支持IDEA/Eclipse开发环境。附赠项目演示视频、运行截图及远程调试服务。需要完整资料的同学可通过文末联系方式获取源代码和文档包。 (98字)
该项目提供完整的Java前后端开发资源包,包含源代码、SQL脚本及相关文档(论文+PPT+开题报告),支持远程调试。技术栈采用Java+SSM/SpringBoot+Vue/JSP,数据库使用MySQL,开发工具为IDEA/Eclipse。项目资料可通过文末联系方式领取,包含运行演示视频和项目截图参考。配套资源全面,适合需要完整项目素材的学习者。(98字)
本项目提供完整的Java Web开发解决方案,包含前后端源代码、SQL脚本及配套文档(论文+PPT+开题报告)。采用主流技术栈:Java+SSM+SpringBoot+Vue+JSP+Mysql,支持IDEA/Eclipse开发环境。项目提供演示视频、运行截图和远程调试服务,需要的同学可通过文末联系方式获取全套资料。
Java项目资料领取通知 本项目提供完整的系统开发资料包,包含前后端源代码、SQL脚本、配套文档(论文+PPT+开题报告)以及远程调试服务。技术栈采用Java+SSM/SpringBoot+Vue/JSP,数据库使用MySQL,支持IDEA/Eclipse开发环境。项目演示视频和运行截图可供参考。需要资料的同学请添加文末联系方式获取。资料包包含:1.完整源代码 2.配套文档 3.远程调试服务。(9
本文提供完整的Java项目资源包,包含SSM/SpringBoot+Vue前后端源代码、SQL脚本及相关文档(论文+PPT+开题报告)。项目采用Java语言开发,整合了SSM框架、Vue框架和MySQL数据库,支持IDEA/Eclipse开发环境。资源包包含可运行演示视频、项目截图及远程调试服务,适合计算机专业学生参考学习。需要完整资料的同学可通过文末联系方式领取。
rabbitmq
——rabbitmq
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区

 2048 AI社区
2048 AI社区
 快递鸟社区
快递鸟社区

 AI编程社区
AI编程社区
 AtomGit AI 社区
AtomGit AI 社区


 AI Agent技术社区
AI Agent技术社区









 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区