登录社区云,与社区用户共同成长
邀请您加入社区
本文总结了"通俗易懂学IT"专栏板块四(441-640篇)的200篇架构设计核心内容,覆盖微服务、分布式系统、云原生等12个知识领域。提供了零基础到架构师的学习路径建议和考试冲刺策略,强调实践与分享的重要性。目前专栏进度64%,即将进入板块五的系统架构设计阶段。作者感谢读者陪伴,鼓励持续学习,保持技术热情,共同成长为更好的架构师。文章以"架构之路,你我同行"作结,展现了对未来技术探索的期待。
把标准能力交给BBWEYY,把核心技术放在Codex+AWS,把品牌表达交给比文云,把Dreamweaver限制在适合的静态页面场景,可以取得更好的成本与控制平衡。本文从企业规模、发展阶段、预算、技术团队、品牌要求和业务复杂度出发,测评BBWEYY、Codex+亚马逊AWS、比文云和Dreamweaver四种建站方式的适配性,并提供由微型企业到集团企业的选型建议。企业规模本身不是唯一标准,更重要的
本文通过港口运维的比喻,系统介绍了云原生核心技术栈:Docker作为标准化容器技术,实现应用封装与隔离;Kubernetes作为容器编排系统,自动化部署与管理容器集群;Prometheus+Grafana构成监控体系,实时观测系统状态。文章重点解析了Docker的镜像分层、容器网络、数据持久化机制,Kubernetes的Pod调度、探针检测等核心概念,并以实际配置示例展示如何实现高效运维。这种"集
本文围绕AI智能体记忆系统展开完整技术解析,针对大模型上下文窗口受限、长对话Token成本高、无法跨会话留存用户偏好等行业痛点,系统性拆解记忆分层定义、通用架构、上下文优化方案、长期记忆工程实现、开源产品对比与行业发展趋势,完整覆盖理论、代码实践、落地挑战与未来演进方向。- 会话级(短期记忆):单一会话内全部交互记录,包含用户提问、模型回复、工具调用日志,直接参与LLM推理,受Token长度约束,
CNCF(Cloud Native Computing Foundation)定义云原生技术帮助企业在公有云、私有云、混合云等动态环境中,构建和运行可弹性扩展的应用。容器、服务网格、微服务、不可变基础设施、声明式API都是云原生的代表技术。核心特征1. 容器化└── 应用打包标准化2. 编排自动化└── K8s自动化部署、扩缩容3. 微服务└── 架构解耦4. 服务网格└── 服务治理(Istio
优秀的评测始于一个可验证的“完成”定义——包括结果、过程、风格以及效率。对于一个教育短视频脚本来说,这意味着:是否生成了一份有效的脚本(结果)?是否真正遵循了模板(过程 / 风格)?当用户在多轮对话中不断施压时,它是否仍能保持稳定?整个 Harness 通过三个评分层次回答这些问题。首先进行确定性检查(validator.py)这是成本最低、可解释性最强的一层信号:输出结果是否符合 Skill 所
本文聚焦 2026 年网安新赛道,深度解析云原生与 AI 安全核心趋势。涵盖容器逃逸检测、K8s 集群加固及对抗样本防御等关键技术,助力从业者跳出舒适区,掌握零信任架构与自动化攻防能力,应对未来职业挑战。
软件开发生命周期(Software Development Life Cycle,SDLC)是软件从“想法”到“上线”再到“退役”的完整过程。它不是一个单一的活动,而是由多个阶段组成的结构化流程。需求分析 → 设计 → 实现 → 测试 → 进化(维护)各阶段详解阶段核心目标主要交付物参与角色需求分析明确“做什么”,收集和分析项目需求需求文档、可行性分析报告产品经理、需求分析师、客户设计确定“怎么做
GPUInventory Port 的统一抽象——这是根基。如果调度器看到的是两套不同的 API(`nvidia-smi` 和 `npu-smi`),混合部署就永远停留在运维手册层面,无法成为平台能力。HAMi 的跨芯片虚拟化——昇腾 vNPU 切分和 NVIDIA MIG/vGPU 切分在 HAMi 层完成统一建模,对上层暴露完全一致的资源申请语义(`gpu-memory: 16GB, gpu-
# AI-Native 云原生架构实战:从 Kubernetes 容器编排到 AI Agent 智能体编排> 当 K8s 遇上 AI Agent,云原生的下半场不再是"容器编排",而是"智能体编排"——2026 年所有后端工程师必须掌握的架构革命。打包在一起,确保在任何环境中都能以相同的方式运行。环境一致性:开发、测试、生产环境完全一致,避免“在我机器上能运行”的问题。快速部署:镜像秒级启动,极大缩短了应用部署和扩展的时间。资源隔离与高效利用:相比
一个成熟的企业级云原生平台,要把集群管理、应用交付、中间件与数据库服务、微服务治理、GPU 调度和安全合规都纳进来——本质上,它承载的是企业的 PaaS 能力。容器云的价值,不在于“能不能跑 K8s”,而在于能不能把集群、应用交付、中间件与数据库、微服务、GPU 调度统一成一个平台化的 PaaS 底座,并和底层 IaaS 打通。其中“中间件服务”最能体现容器云的 PaaS 属性——把数据库、缓存、
在这篇文章中,我们通过一个幽默的面试场景,探讨了互联网大厂 Java 求职者在面试中可能遇到的技术问题,涵盖了Java SE、Spring Boot、微服务与云原生等技术点,同时结合实际业务场景,提供了详细的解答,帮助读者更好地理解和掌握相关知识。
医疗影像元数据的存储是一个"宽表+JSON+对象存储"的三位一体方案:宽表承载90%的查询性能,JSON保证字段扩展的灵活性,对象存储解决大文件的存储和长期保存。三个组件各司其职,通过一份检查的StudyInstanceUID作为全局唯一标识串联。架构设计时,永远优先考虑"放射科医生明天早晨查房时要调阅昨晚急诊的所有影像"这个场景——这是医疗场景中最真实的SLA。本文属于「行业场景与项目复盘」系列
Quarkus 代表了 Java 在云原生时代的一次重要进化。它没有抛弃 Java 的生态和规范,而是重新定义了 Java 框架的运行时模型,把传统框架在运行时通过反射完成的工作前移到构建期,从而实现了启动时间、内存占用、首请求延迟的全方位优化。这种"构建期计算、运行时执行"的范式,不仅让 Java 应用在云原生场景下重新具备了竞争力,也为 Java 框架的设计提供了新的思路。Quarkus 的意
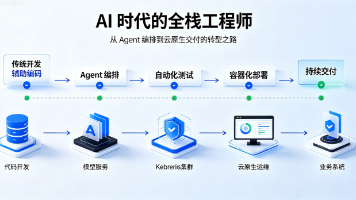
AI时代全栈工程师的转型与重构 随着AI Agent的崛起,传统全栈开发的“一人闭环”模式正在被颠覆。全栈工程师的角色从“代码实现者”转变为“AI系统架构师”,核心能力从“调API”升级为“编排Agent工作流”。新的能力模型强调70%工程能力(如云原生架构、工作流编排)、20%AI认知(如LLM原理、Prompt工程)和10%业务洞察。 技术实践上,LangGraph等工具通过状态机引擎和节点化
7、了解分布式系统设计与开发、负载均衡技术,系统容灾设计,高可用系统等知识;6、全面、扎实的软件知识结构,掌握操作系统、数据结构、网络等专业知识;1. 参与交易平台的设计、开发与测试,实现交易策略、风控等需求;4、编程基本功扎实,熟练C/C++开发语言、常用算法和数据结构;#幻方#明汯#九坤#鸣石#天演#进化论#佳期#量化研究员#C++5、熟悉TCP/UDP网络协议及相关编程、进程间通讯编程;春招
# AI-Native 云原生架构:2026 年从容器编排到智能体编排的范式革命## 一、引言:2026,云原生进入 AI-Native 时代如果你还在把 Kubernetes 当作"容器编排平台"来看待,那你可能已经错过了云原生历史上最重要的一次范式迁移。2026 年 7 月,刚刚落幕
事实上,对于越来越多的平台构建者来说,随着云原生技术的日趋落地,“PaaS”本身的“解释权”不再属于某一家提供商,而更多取决于平台构建者的业务场景和其终端用户的实际需求。不过,轻量级 App Service 本质上还是 Heroku 体验在 Kubernetes 底座上的复刻,它们在提供出色的开发者使用体验的同时,也继承了经典 PaaS 的“封闭”与“不可扩展”,这在很多大型企业基于云原生技术栈
展望未来,太原的不锈钢岗亭行业将呈现出“定制化、智慧化、美学化”三大趋势。随着物联网、5G技术的发展,集成更多智能硬件的“智慧岗亭”将成为新的增长点。同时,随着城市风貌管控的精细化,岗亭的设计将更加注重与城市肌理的融合,具有地域文化特色的艺术岗亭将越来越多地出现在街头巷尾。对于行业从业者而言,单纯的制造能力已不足以构建核心竞争力。未来的赢家,将是那些能够整合设计、制造、技术、服务的综合性解决方案提
本文探讨了在离线数据中心与工业场景下,如何通过硬件智能告警终端(如博灵Q系列)与云原生监控系统(Prometheus/Alertmanager)的深度集成,解决传统告警方式的局限性。文章提出通过HTTP REST API/Modbus TCP协议实现告警终端的全彩LED动态渲染和TTS语音播报功能,并详细介绍了系统架构设计、协议栈集成方案以及Go语言实现的告警转换逻辑。同时针对工业环境特点,提出了
当前AI岗位竞争激烈,企业更青睐具备Linux底层能力和云原生技术的复合型人才。为此,作者决定系统学习Linux系统管理和云原生技术(Docker/K8s等),以打通从模型开发到工程落地的全流程能力,提升就业竞争力。这既能弥补"调参但无法部署"的学生常见缺陷,又能顺应企业云端部署趋势,为未来职业发展构建完整技术栈优势。(149字)
边云协同的异常检测管道核心是用"低成本的边缘过滤"替代"高成本的云端全量处理"。99%的正常数据在边缘丢弃,1%的异常数据上传云端做深度分析——网络带宽和云端算力的利用率提升100倍。规则的动态下发是边缘智能的关键能力——云端持续优化检测策略并实时推送到数以万计的边缘节点。边缘和云端不是竞争关系而是分工关系——边缘做快、做省、做稳;云端做深、做准、做全。(由于输出长度限制,剩余0721年7篇文章将
TDengine在写入吞吐和设备管理模型上具有专用时序数据库的天然优势,适合设备数量巨大、查询模式固定的场景。InfluxDB生态最成熟但写入性能在三者中偏弱,适合中小规模部署。ClickHouse的通用性最强,复杂Ad-hoc分析查询性能最佳,适合需要灵活数据探索的分析场景。没有绝对最优的时序数据库——选型需要基于实际场景的写入量、查询模式和预算约束做判断。
云安全学习软件介绍
为了让一个运行在云端的 Serverless 函数安全地读写同一个虚拟网络里的 Redis 缓存,你需要准备两份配置文件。第一份是云平台的 IAM 授权策略(Policy),声明了繁琐的 JSON ARN 路径;第二份则是本地开发环境的 Docker Compose 配置,用一行命令声明连接关系。很多技术团队盲目追求所谓的“无服务器(Serverless)”和“云原生”,以为从此能省去运维开销。然
# Agent Native Cloud:云原生架构的下一个十年,从 Agent Infra 开始> 2026年7月18日,上海WAIC,阿里云发布了Agent Native Cloud。这不是又一套"AI+云"的营销话术,而是宣告:**云原生架构正式进入"为智能体而生"的新时代。**##
本文介绍了Flutter三方库storage_client在鸿蒙系统的适配指南。该库提供了一套标准化的云存储API,支持高性能文件上传下载、权限控制和云端资产管理。文章详细讲解了其核心原理、适配方法、关键API及典型应用场景,并针对OpenHarmony平台的特殊性提出了优化方案。通过该库,开发者可以在鸿蒙应用中构建与云原生深度集成的数字化底座,实现极致的云端数据一致性和传输可靠性。文中还提供了完
飞算JavaAI炫技赛参赛作品突破AI编程工具仅能生成简单Demo的刻板印象,展现了在复杂企业级场景中的技术深度。参赛作品包括SpringCloud微服务供应链系统、并发事务处理积分商城、多级分销架构和行级权限CRM系统,覆盖微服务拆分、分布式事务、业务规则引擎等核心难题。关键发现:飞算JavaAI能结构化拆解需求,生成符合工程规范的代码框架,并通过十大专家Agent提供全链路支持。赛事证明AI编
容器化是操作系统级虚拟化的实现方式,通过内核命名空间(Namespace)和控制组(Cgroup)技术,将应用及其依赖环境封装为独立进程。对比维度容器虚拟机启动速度秒级分钟级镜像大小MB 级GB 级资源开销低(共享内核)高(完整 OS)隔离级别进程级隔离硬件级隔离容器共享主机系统的内核,每个隔离的工作负载都不需要整个操作系统实例,因此资源效率更高。Docker 镜像是通过镜像仓库进行存储和分发的。
云原生
——云原生
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区


 智能体开发者社区
智能体开发者社区



 微软开发者社区
微软开发者社区




 人工智能6S服务平台
人工智能6S服务平台




 深开鸿 技术专区
深开鸿 技术专区


 openEuler 社区
openEuler 社区




 DAMO开发者矩阵
DAMO开发者矩阵








 HarmonyOS开发者社区
HarmonyOS开发者社区




