- @m0_59162559
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细对比三大企业级AI Agent平台:Dify(企业知识库首选)、BuildingAI(快速商业闭环)和LangChain+LangGraph(高度定制化)。针对不同场景提供选型建议,涵盖RBAC权限系统、RAG知识库、多模型支持、商业化能力等企业级需求,帮助开发者根据团队规模和技术能力选择最适合的开源解决方案。
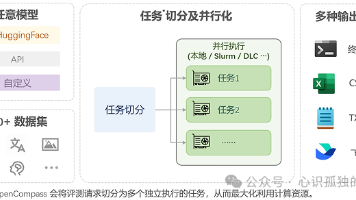
生成式大语言模型的性能评估是模型优化与应用落地的关键环节。通过系统化评估,可精准量化模型在多维能力指标上的表现,为技术迭代提供数据支撑。OpenCompass作为专业的评估平台,集成了完备的评估指标体系与大规模开源数据集,能够全面满足生成式大语言模型的多样化测评需求。本文将基于OpenCompass框架,详细解析生成式大语言模型的标准化评估方法论。
这篇文章介绍了大语言模型(LLM)的核心原理,重点讲解next token prediction机制。详细解释了token概念、tokenization过程、embedding和位置编码的添加方法,以及预训练和推理阶段的实现。还介绍了温度参数如何控制生成文本的随机性,并提供了nano-GPT的代码实现,帮助理解大语言模型的工作原理。

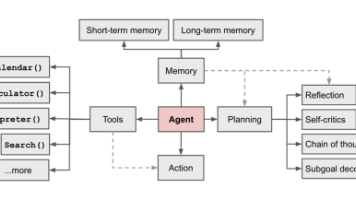
本文从功能、核心能力和工程三个维度介绍智能体(Agent)架构,详细讲解规划能力(思维链、思维树、自一致性等)、工具使用(Function call和MCP协议)及记忆模块(短期记忆和长期记忆及MIPS检索技术)。这些内容构成了智能体的核心知识体系,帮助开发者构建更强大、更智能的大模型智能体应用。
文章详细解析了AI领域的三大核心技术:MCP(模型上下文协议)作为"万能转换器"统一工具接口;RAG(检索增强生成)解决AI"幻觉"问题,提供知识支持;Agent作为智能体能主动完成任务。三者协同工作形成"黄金三角",使AI进化为智能助手,未来将广泛应用于生活和工作中,掌握这些概念有助于跟上AI时代步伐。

鸿蒙(HarmonyOS)这个名字似乎已成为科技圈内绕不开的话题热点。2024年,坊间关于鸿蒙开发的讨论热度持续发酵,不少声音称其为“就业新蓝海”。那么,这股热潮是否真如传闻般热浪滔天,为开发者带来广阔的就业金矿呢?

华为对于操作系统的发展可谓是孜孜不倦。今年以来,华为在鸿蒙系统的推进上达到了新的阶段,纯血鸿蒙系统的商用版本将于今年四季度与Mate 70系列手机一同面世。所谓"纯血鸿蒙",是指这一版本的鸿蒙系统将完全使用鸿蒙内核和应用,不再依赖安卓系统。据透露,纯血鸿蒙将减少40%的冗余代码,从而提升系统的流畅度、能效和安全性。为推进纯血鸿蒙系统的生态建设,华为已在今年4月宣布,目前已有超过4000个应用加入鸿

我必须坦言,我原先对鸿蒙的发展速度持有保守估计,而今却被其迅猛的增长势头深深震撼!今年年初,华为掷地有声地发布了HarmonyOS NEXT鸿蒙星河版开发者预览,并公开展示了鸿蒙生态系统的最新飞跃成就:令人惊叹的是,鸿蒙生态设备数在短短5个月内实现了从7亿台跨越到8亿台的里程碑式突破。现阶段,已有超过6000万用户完成了鸿蒙系统的升级,且这一数字每天还在以约120万人的速度稳健递增。截止至今年3月

去年9月,华为宣布鸿蒙鸿蒙原生应用全面启动,基于开源鸿蒙开发的 HarmonyOS NEXT 鸿蒙星河版将在今年秋天正式和消费者见面。该版本系统底座将由华为全线自研,去掉传统安卓 AOSP 代码。

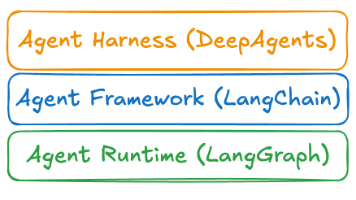
本文详细解析了企业级AI智能体的三种技术架构:AI智能体框架(如LangChain,提供抽象能力)、AI智能体运行时(如LangGraph,满足生产环境需求)和AI智能体工具集(如DeepAgents,开箱即用工具集合)。文章分析了三者的核心差异、适用场景及选择指南,帮助开发者根据需求选择合适的架构,快速构建大模型应用。