登录社区云,与社区用户共同成长
邀请您加入社区
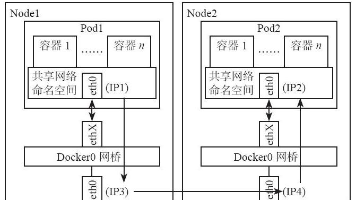
集群外部主机可以访问集群内部应用集群内部应用也可以访问集群外部主机各个namespace之间没有做任何的隔离策略如果希望在 IP 地址或端口层面控制网络流量, 考虑使用 Kubernetes 网络策略(NetworkPolicy)。NetworkPolicy 是一种以应用为中心的结构,允许你设置如何允许Pod与网络上的各类网络“实体” 通信。NetworkPolicy 适用于一端或两端与 Pod
Playwright MCP:它是一个“协议服务器”,作用是让支持 MCP 的 AI 应用(如 Cursor, Windsurf)“看到”并操控浏览器。它充当桥梁,将 Playwright 的能力打包成标准化的“工具”,供任何支持 MCP 的 AI 客户端调用。工作方式:AI 客户端通过 MCP 协议调用服务器暴露的“工具”,服务器执行操作后返回结构化的可访问性快照(Accessibility S
网络性能优化是Kubernetes集群优化的重要环节。通过选择合适的网络插件、优化配置、监控性能,可以显著提升集群的网络效率。希望这篇文章能帮助你优化Kubernetes集群的网络性能。如果你有任何问题或经验分享,欢迎在评论区交流!本文作者:侯万里(万里侯),致力于网络性能优化的工程师。
通过 Nginx 统一入口访问,具备高可用、负载均衡和 Web 管理能力。官方文档:https://min.io/docs/minio/linux/index.html。端口反向代理到任意一个 MinIO 节点的 Console 端口,并使用。如需扩展节点,请参考 MinIO 官方文档(分布式模式扩容需重建集群)。这些目录将作为 MinIO 节点的本地存储卷,每个节点挂载一个。,MinIO 节点会
本文详细分析了NAS环境下的Docker镜像拉取性能问题,通过多种技术方案的对比测试,提出了一套完整的优化解决方案。实测数据显示,优化后的方案能将镜像拉取时间从数小时缩短至3-5分钟,提升倍数达到15倍左右。文章包含了完整的配置代码、性能测试数据和适用场景分析,为NAS用户提供了实用的技术指导。Docker、NAS、群晖、威联通、容器、镜像加速、性能优化随着智能家居和个人服务器概念的普及,越来越多
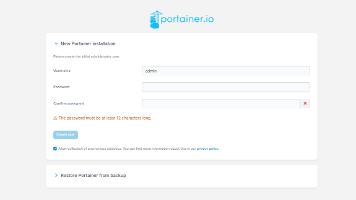
Docker服务增加后,仅靠docker ps和多条启动命令管理容器,容易出现参数记错、日志查找困难和服务状态不清晰等问题。尤其是在NAS、家庭服务器或小型业务主机中,一个统一的管理入口会更方便日常维护。Portainer是一套轻量级Docker可视化管理平台,可以在浏览器中查看容器、镜像、网络、存储卷和运行状态,也能完成容器启停、日志查看和基础配置管理。它适合Docker初学者、个人服务器用户和
Docker 只负责执行入口,真正决定环境是否正确的是 shell 初始化方式,而 Ascend NPU 强依赖 profile/basrc 中的环境变量配置,因此 login shell 与 non-login shell 的差异会直接导致运行结果完全不同。
公司的APP做久之后,很容易把APP做的臃肿,功能越来越多,体积也越来越大。原来只有商城、社区、聊天,后来要接生活缴费、打车出行、家政维修、票务预约、会员权益、附近商户,今天分享一下如何通过小程序管理平台的形式为来解耦优化APP,引入第三方生态
网络模式适用场景代理兼容性推荐度bridge(默认)大多数场景,容器需要独立网络⭐⭐⭐⭐⭐ 最佳最推荐host容器需要极致网络性能,不关心隔离⭐⭐ 可能冲突不推荐用于代理场景none完全离线容器❌ 不支持代理不适用自定义网络多容器互联⭐⭐⭐⭐ 良好高级用户环境变量传代理,别用YAML配置网络模式用bridge,别用host二选一别混用,环境变量最稳把这三点记住,基本就不会踩坑了。如果还不行,按上面
本文系统介绍了Docker的核心概念和实用技术。主要内容包括:1)Docker三大核心组件(镜像、容器、仓库)的特性和作用;2)CentOS/Ubuntu系统下的安装部署方法;3)常用容器管理命令及参数详解;4)底层技术原理(Namespace、Cgroup、OverlayFS);5)Dockerfile编写规范与镜像优化技巧;6)生产环境最佳实践(多容器编排、数据共享、监控方案等)。文章强调Do
容器 = 被隔离的进程容器不是虚拟机,它不像虚拟机那样拥有独立的操作系统内核。容器的本质是利用 Linux 内核的隔离机制,将一个进程及其依赖资源(文件系统、网络、进程空间等)打包在一起,使其看起来像在一台独立的机器上运行。│ 物理服务器 ││ │ 容器 A │ │ 容器 B │ ││ │ │ Libs/依赖 │ │ │ │ Libs/依赖 │ │ ││ │ 容器运行时 (Docker Engin
本章目标:在不同操作系统上完成 Docker 的安装、配置和验证,搭建后续学习的实验环境。
本文档中格式(如<USERNAME>)均为占位符,部署时需替换为实际环境的值。
默认情况,集群网络连通性如下:集群外部主机可以访问集群内部应用集群内部应用也可以访问集群外部主机各个namespace之间没有做任何的隔离策略如果希望在 IP 地址或端口层面控制网络流量, 考虑使用 Kubernetes 网络策略(NetworkPolicy)。NetworkPolicy 是一种以应用为中心的结构,允许你设置如何允许Pod与网络上的各类网络“实体” 通信。NetworkPolicy
Docker(五)_数据根目录空间不足的原因与解决方法
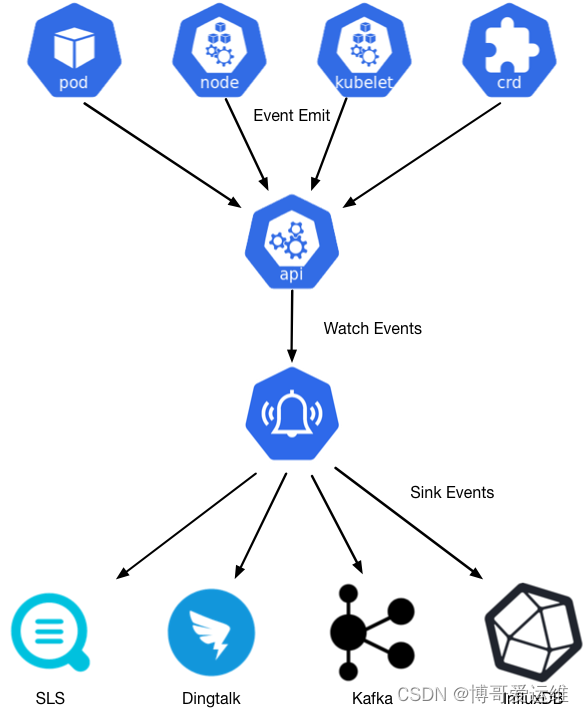
大家好,我是博哥爱运维。这节课给大家分析一款K8S上宝藏级秒级事件监控报警的开源软件`kube-eventer`,它是由阿里云开源的,并且难得的还一直有在更新。
(3) 末行模式:在命令模式下,用户按 : 键即可进入末行模式。此时的vim编辑器会在显示窗口的最后一行(通常也是屏幕的最后一行)显示一个 : 作为末行模式的提示符,等待用户输入命令。(2) 输入模式:在命令模式下按相应的键可以进入输入模式,输入插入命令 i 、附加命令 a 、打开命令 o 、修改命令 c 或替换命令 s 都可以进入输入模式。配置完成后,按下键盘上的 ESC 键退回到命令模式,然后
本文提供了Windows系统下Docker Desktop环境的完整迁移方案,包含镜像、容器和数据卷的备份恢复方法。主要步骤包括:1)确保两台电脑安装相同版本Docker并启用WSL2;2)通过批处理脚本备份所有Docker镜像到tar文件;3)使用PowerShell命令迁移数据卷;4)在新电脑恢复镜像和数据。文章特别强调了常见问题的解决方案,如Docker未启动导致的命令报错、权限问题修复等,
NMS 开发环境完整搭建指南(WSL + Docker 版)
Intel SGX(Software Guard Extensions)是Intel开发的一种硬件级机密计算技术,旨在保护敏感数据和代码在内存中的安全。它通过创建隔离的“enclave”(可信执行环境)来实现,确保即使操作系统或虚拟机被攻击,enclave内的数据也无法被外部访问。下面我将逐步解析其核心技术、应用场景与实践方法,确保内容真实可靠。Intel SGX的核心是硬件辅助的安全机制。CPU
系统需预存注册人脸的嵌入向量库。识别时,实时提取特征并计算与库中向量的最小距离,实现毫秒级响应。FaceNet 直接将人脸映射到欧氏空间,满足同一人距离小、不同人距离大的特性。
Docker客户端和Docker守护进程交流,而Docker的守护进程是运作Docker的核心,起着非常重要的作用(如构建、运行和分发Docker容器等)。达梦官方提供了DM 8在Docker容器中进行部署的镜像文件,下面通过具体的步骤进行演示。(1)在根目录下创建 /dm8 文件夹,用来放置下载的 Docker 安装包。(4)使用docker images命令来查看导入的镜像。(7)查看当前用户
解压文件为:dm8_20251203_x86_Ubuntu22_64.isodm8_20251203_x86_Ubuntu22_64.iso_SHA256.txtdm8_20251203_x86_Ubuntu22_64.README。对应教程进行配置https://eco.dameng.com/community/article/56885f5ce2c66511506f7c7968da84fe。新
原文链接:https://blog.csdn.net/qq_53961668/article/details/144240775。2. 设置 Docker 的 apt 仓库。3. 安装 Docker 包。
docker内的数据映射可以不通过数据卷,直接映射到本地的目录。下面将以mysql容器示例,完成容器的数据映射。
容器
——容器
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI硬件创业社区
AI硬件创业社区

 MCP技术社区
MCP技术社区
 深开鸿 技术专区
深开鸿 技术专区



 魔珐星云开发社区
魔珐星云开发社区
 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 人工智能6S服务平台
人工智能6S服务平台


 龙虾开发者社区
龙虾开发者社区


 openEuler 社区
openEuler 社区

 DAMO开发者矩阵
DAMO开发者矩阵





 葡萄城开发者空间
葡萄城开发者空间





 2048 AI社区
2048 AI社区



