登录社区云,与社区用户共同成长
邀请您加入社区
另外,如果你喜欢折腾各种游戏模拟器、工具软件,或者想找更全面的资源整合站,我推荐你常去 TopClaw(https://top.wokk.cn/)逛逛,那里不仅有 OpenClaw 的详细教程包,还有各种游戏资源、运行库一键安装包,甚至有些老游戏的兼容性补丁。别怕,跟着我的节奏,一步步来,保证你一次过。还有,你的杀毒软件可能会拦截某些文件,建议安装前暂时关闭实时防护,免得它把模拟器当病毒误杀。在游
——摘自我的测试笔记当然,性能提升也有代价——新版对内存的占用量比旧版多了约15%,但考虑到现在主流PC起步都是16GB,这点换算是值得的。唯一的建议是:刚升级完最好先重置一下配置文件(菜单里有“恢复默认设置”按钮),因为旧版的某些定制化参数在新版引擎下可能不兼容,会导致奇怪的渲染bug。但这次2026新版的界面优化,真的让我眼前一亮——它没走“为了炫酷而炫酷”的弯路,而是把“好用”放在了第一位。
放心,源码都是开源的,没有恶意代码。如果你觉得找数据太麻烦,或者想找到更完整的资源合集,不妨去 TopClaw(https://top.wokk.cn/) 看一眼,那上面不仅收录了 OpenClaw 各版本的快速直链,还有玩家整理的兼容性列表和常见问题 FAQ,省去你在各个论坛翻帖子的时间。如果你手里没有,我教你一个合法操作:去互联网档案馆(Archive.org)搜索“Claw - Sharew
摘要: GEO(生成式引擎优化)是针对AI搜索和问答系统的新型优化技术,旨在提升品牌信息在AI生成答案中的可见性、准确性和权威性。其核心目标包括:被看见(出现在AI答案中)、被引用(成为核心信息来源)、被信任(构建高可信内容)、被转化(提高用户转化率)和资产化(积累可复用的数字资产)。通过GEO,企业能更高效地触达AI交互场景中的潜在用户,抢占新一代流量入口。
你拿到需求后,第一个想的不应该是代码,而是:定故事 → 定角色 → 画流程 → 写一页纸。
7月上海,WAIC 2026世界人工智能大会释放了多个数据库行业的关键信号:星环科技发布全球首款GPU原生认知数据库,TPC-DS性能提升70倍;数据库正在从“存储工具”演变为AI Agent的“认知基础设施”;中国信通院发布2026数据库产业图谱,关键行业“AI数据库”攻坚计划启动。本文从三个信号出发,分析数据库行业正在经历的范式变革,帮助读者理解“数据库的下半场正在被AI重写”这一核心趋势。
本文实测金仓 KES MCP Server——把表结构查询、执行计划分析、健康检查、索引模拟等 9 个常用操作封装为标准工具,集成到 Cursor/Trae 等开发工具中。重点体验了 sys_hypo 零成本模拟索引功能,给出 Restricted 安全模式配置、日常巡检等实操建议。
时序数据是2026年增长最快的数据类型之一。据行业预测,工业物联网产生的时序数据量将占企业总数据量的75%以上,年复合增长率超过40%。时序数据已从“技术补充”升级为“核心资产”。本文从时序数据的基本概念出发,讲解时序数据的特征、应用场景,以及为什么传统数据库处理不了时序数据,帮助读者建立对时序数据的完整认知。
db2 "select TBSP_NAME, TBSP_TYPE, TBSP_USABLE_PAGES, TBSP_USED_PAGES from sysibmadm.TBSP_UTILIZATION"# 详细使用率。db2 get db cfg for <DB_NAME> | grep "LOG"# 检查日志配置(主/次日志数、路径)db2pd -db <DB_NAME> -hadr# 查看HA
参考如下的技术贴python - psycopg2 : cursor already closed - Stack Overflowhttps://stackoverflow.com/questions/35651586/psycopg2-cursor-already-closed[Solved] Python psycopg2 : cursor already closed - Code Red
查看数据库状态show。
core 是前后端主要代码,drivers 为动态加载的数据库驱动,mapFiles 为系统内使用的genJson地图资源,sdk 为项目公共库,staticResource 为后端的静态资源库。
liquibase执行的每一个changeSet都自动打tag
2025-08-05 18:14:44org.apache.flink.util.FlinkException: Global failure triggered by OperatorCoordinator for 'Source: PostgresParallelSource -> amos.time_captured-amos.billed_items-amos.pickslip_detai
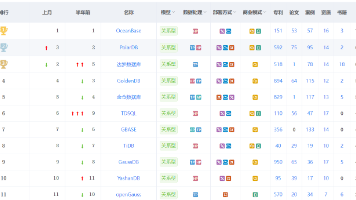
2026 年 1 月中国数据库 TOP10 榜单解析:OceanBase 持续领跑
来找我给你解决办法!
针对国产CPU不支持avx2及SSE指令集编译,目前在海光U上测试运行正常,与常规CPU性能对比待补充。因fe是java语言的且不参与数据查询计算,不依赖CPU指令集,所以只需要编译be即可,fe用官方的相同版本即可。通过docker环境进行编译。
jpa生成的sql语句in在oracle数据库超过1000后会报错,现在用一个简单办法来解决这个问题。hibernate拦截器。druid访问者工具。
NineData社区版是一款免费的数据管理工具,支持Docker一键部署(10分钟完成),提供数据库DevOps、数据复制和数据库对比三大核心功能。它适用于开发者、初创团队等用户,支持多种数据库类型的数据源管理和SQL查询,基于自研CDC技术实现高效数据同步,并能自动生成数据差异修复SQL。本地化部署保障数据安全,初始账号密码均为admin,建议部署后立即修改。
2月9日消息,阿里云Lindorm向量检索服务在权威榜单VectorDBBench中性能登顶,大幅超越主流竞品。其核心优势在于:在千万级数据规模下实现2.5ms稳定延迟与24000+超高QPS(每秒查询率),并在复杂混合检索场景中通过智能优化彻底规避了性能骤降问题。这一突破源于将向量检索重构为原生数据库系统,通过融合聚类、图索引和量化技术突破内存瓶颈,并以统一的标量-向量架构和智能路由优化器,在高
本文是MySQL避坑指南系列的第一篇,聚焦安装配置阶段的10个高频问题。主要内容包括:安装环节的系统源版本滞后、root密码获取、安全初始化失败;字符集设置不当导致的中文乱码和大小写敏感问题;配置文件修改无效、连接数耗尽等配置问题;以及用户权限管理中的远程连接和权限生效问题。文章针对每个问题提供了根因分析和解决方案,特别强调MySQL默认配置不适合生产环境,建议安装后必须调整字符集、连接数和账号权
达梦数据库中保留字介绍,保留字冲突问题处理方案等
MySQL 5.7到8.0升级核心注意事项 摘要:MySQL 5.7已停止维护,升级到8.0需注意以下关键变化:1)默认字符集从latin1变为utf8mb4,排序规则差异可能导致查询结果变化;2)认证插件改为caching_sha2_password,旧版驱动需升级或临时切换认证方式;3)SQL功能增强,新增窗口函数、CTE递归查询等特性;4)性能整体提升但个别查询可能变慢;5)数据字典改用In
《Redis避坑指南:安装配置9大常见问题解决方案》摘要 本文针对Redis安装配置过程中常见的9大问题提供解决方案,涵盖编译安装、版本选择、Docker部署、远程连接、密码认证、内存管理等关键环节。主要内容包括:1)编译安装后命令找不到的PATH配置问题;2)系统源版本过旧的解决方案;3)Docker数据持久化配置方法;4)远程连接和防火墙设置;5)密码认证常见错误排查;6)Redis7.x A
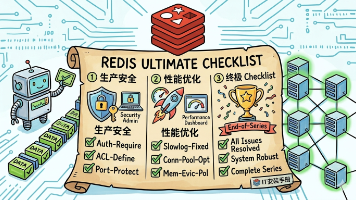
《Redis生产安全与性能优化终极指南》总结了Redis在生产环境中的关键注意事项。安全方面重点防范公网暴露风险,通过绑定内网IP、设置强密码、禁用高危命令等措施防止入侵;性能优化建议控制Pipeline批次大小(100-1000条)、使用Hash结构替代多个String键值。文章还提供了包含27个常见问题的终极Checklist,涵盖安全配置、内存管理、持久化设置等核心维度,帮助开发者在部署前全
摘要:Spring Boot + Oracle 批量操作性能测试报告 本文通过实测对比了Spring Boot项目中Oracle数据库的4种批量操作方式: 无事务循环单条插入(性能最差,1000条需3-4秒) 有事务循环单条插入(性能提升3-4倍) foreach批量拼接SQL(推荐<2000条数据) JDBC原生batch(大数据量最优) 关键结论: 小数据量(<2000条):推荐foreach
本文深入解析Redis中String和Hash两种核心数据类型的命令细节与应用场景。String类型部分详细介绍了基础SET/GET命令、带参数设置、数值操作及批量操作,重点分析了分布式锁、计数器等典型应用场景。Hash类型部分讲解了字段操作、数值增减等命令,并通过用户信息、购物车等案例展示其优势。文章特别强调了大value对性能的影响,并对比了Hash与String+JSON存储方式的差异。最后
Redis持久化机制深入解析 Redis作为内存数据库,其数据易失性要求必须通过持久化机制保证数据安全。文章详细分析了两种持久化方式:RDB和AOF。 RDB通过快照方式保存数据,具有文件紧凑、恢复快的特点,但存在数据丢失风险。触发方式包括自动配置、手动命令和特殊场景触发,核心流程通过fork子进程完成。 AOF以日志形式记录写命令,提供更高数据安全性,支持三种同步策略。AOF重写机制可压缩文件体
本文完整梳理了 MySQL 主从复制的搭建流程,以及基于 MyCat 中间件实现分库分表、读写分离的核心配置与验证步骤。通过主从复制可实现数据备份与读写分离的基础,而 MyCat 则进一步解决了单库单表的性能瓶颈问题,适用于高并发、大数据量的业务场景。实际应用中需根据业务特点选择合适的分片规则,并做好节点监控与故障转移配置。
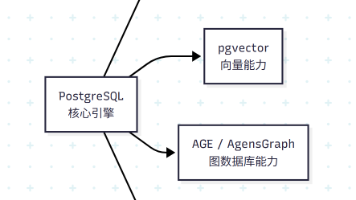
关键词:#PostgreSQL #多模数据库 #向量数据库 #pgvector #技术架构 #数据库选型;聚焦PostgreSQL:打破数据库界限的多面手 PostgreSQL凭借其开放的设计哲学和强大的扩展能力,突破了传统关系型数据库的局限。它通过插件机制实现了"一生万物"的转变:安装pgvector可变为向量数据库,支持AI语义搜索;集成TimescaleDB即成为时序数据库,处理监控和IoT
对于开发者而言,Oracle数据库最佳客户端工具非Oracle SQL Developer莫属。他是官方的,从常识来说,一定会比第三方做的好他是免费的,定期发布新版功能丰富强大,支持SQL,PL/SQL,SQL Plus,SQLcl多种语法支持MySQL,TimesTen,通过JDBC插件支持第三方数据库关联。支持数据库建模支持第三方数据库迁移提供VS Code插件SQL Developer的说明
database
——database
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区

 AI编程社区
AI编程社区



 AtomGit AI 社区
AtomGit AI 社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区