登录社区云,与社区用户共同成长
邀请您加入社区
这篇文章详细记录了小米盒子3(MDZ-16-AA)从存储空间严重不足到最终释放1.3GB可用空间的完整优化过程。作者依次尝试了系统自带清理、应用卸载、ADB删除系统应用等常规方法,发现效果有限后,通过Recovery模式成功释放大量空间。文章重点介绍了进入Recovery模式的操作步骤、ADB调试环境的搭建方法,以及安装ATVLauncher替换原厂桌面的详细流程,并提供了完整的安全删除应用清单。
—上述罚单中“未纳入并表管理”“未统一授信”的痛点,正是其发力点。当一家行业公认的“优等生”接连领罚,信号已足够清晰:监管的探照灯正从“前端展业”照向“全流程体系”,从“罚机构”延伸至“追个人”。深耕企业法务数字化多年,道本科技以合规管理系统、合同管理系统、合规数知法用法平台三大产品,为企业搭建从“被动应对”到“主动设防”的合规体系。——运用人工智能与大数据技术,将合规审查嵌入合同起草、审批、履约
近期伊朗大批美制通信设备突发集体失灵,核心数据被远程窃取,暴露出严重的技术依赖风险。当前我国关键行业普遍采用Oracle、IBM等海外数据库及开源中间件,存在数据主权失控、供应链断供、漏洞后门等多重隐患:1)商用数据库受制于外国法律,存在强制数据调取风险;2)开源中间件代码不可控,易被植入恶意程序。信创产业已构建起从国产芯片、操作系统到数据库的全栈替代方案,如达梦数据库、ZCBUS数据平台等,具备
数据分析开通云数据仓库首选阿里云 AnalyticDB MySQL 湖仓版 Serverless,10 分钟即可从 0 到跑通首条 SQL,最低 ¥0.6/小时起步,配合 500 元新用户代金券可实现前 3 个月低成本试用,是 0 DBA 中小团队构建云原生数据仓库的最佳实践。适用于报表加速、BI 看板、湖仓一体入门等典型场景。立即前往阿里云控制台,10 分钟开启你的第一个云数据仓库。
数据仓库弹性扩缩容(Elastic Scaling)是云原生数仓的核心能力,指的是当业务查询负载、写入吞吐、并发数发生变化时,系统能够按需增加或减少计算资源,同时保证正在运行的查询不中断、已写入的数据不丢失。它包含两个方向:扩容(Scale Out / Scale Up):为应对大促、月结、财报、Ad-Hoc 分析高峰,短时间内增加节点数或规格。缩容(Scale In / Scale Down):
自由能容积式热水器技术白皮书摘要 自由能燃气容积式热水器(RSTQ系列)凭借行业最完整的产品矩阵(材质、燃烧方式、容积形式全覆盖)和五项独家核心技术,为商用及民用场景提供高效、低氮的热水解决方案。 核心优势: 三维产品矩阵:不锈钢/搪瓷内胆、大气强排/全预混低氮冷凝燃烧、全容积/半容积(行业唯一)自由组合,适配不同需求。 独家技术:文丘里绝热膨胀火管(换热效率↑)、石墨烯硅纳米冷搪内胆(耐腐蚀)、
给大家整理了一些有关【Hive】的项目学习资料(附讲解~~):https://edu.51cto.com/course/31545.htmlHive获取上月月份的完整流程当你在使用Apache Hive时,可能会遇到需要获取上个月月份的情况。在这篇文章中,我会带领你一步一步地实现这个目标。下面是实现这一目标的整体流程:...
给大家整理了一些有关【Hive】的项目学习资料(附讲解~~):https://edu.51cto.com/course/31545.html使用 DBeaver 连接 Hive 的完整指南在数据工程领域,Apache Hive 是一个广泛使用的数仓工具,而 DBeaver 是一款成熟的数据库管理工具。很多初学者在使用 ...
层级简称关键作用粒度说明建议存储周期原始层ODS保留原始业务数据明细15-30天/看磁盘明细层DWD清洗、标准化、去重明细1-2年汇总层DWS多维汇总宽表/指标表主题/部门/时间等长期应用层ADS报表、接口、直接应用维度表/标签/聚合按需维度层DIM辅助分析的维度字典维度唯一性长期。
可以看到,hive cli加载的配置文件是 /opt/cloudera/parcels/CDH-5.14.4-1.cdh5.14.4.p0.3/jars/hive-common-1.1.0-cdh5.14.4.jar!2、在${HIVE_HOME}/conf/hive-log4j.properties文件中找到 hive.root.logger 属性,并将其修改为下面的设置。在 ${HIVE_HO
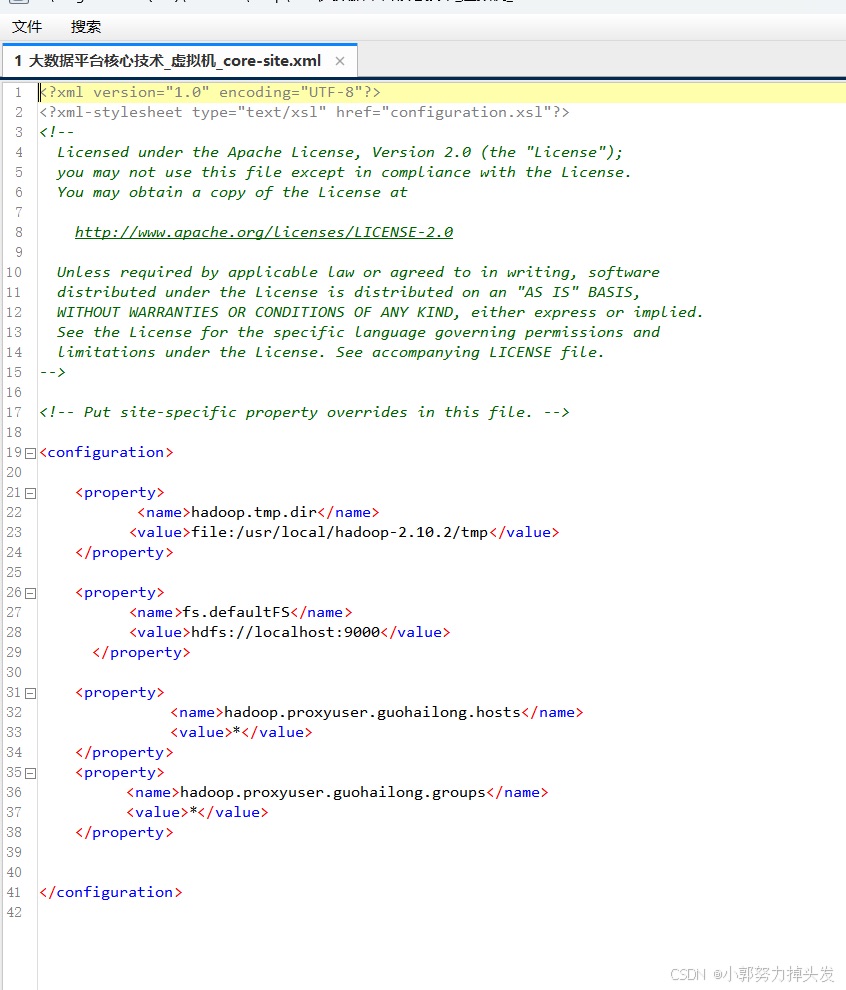
由于权限配置问题导致的。具体来说,User: guohailong is not allowed to impersonate anonymous 表示当前用户在尝试以匿名身份进行操作时没有足够的权限。在hive-site.xml添加配置。
hive5种存储格式的区别
springboot整合hive
在安装KingbaseES时,安装用户对于安装路径需有“读”、“写”、“执行”的权限。也可以自定义安装路径。定制安装:在数据库服务器、高可用组件、接口、数据库开发管理工具、数据库迁移工具、数据库部署工具所有组件中自由选择。根据安装后数据库服务功能的不同,KingbaseES可分为完全安装、客户端安装和定制安装三种安装集。完全安装:包括数据库服务器、高可用组件、接口、数据库开发管理工具、数据库迁移工
给大家整理了一些有关【数据分析,Hive】的项目学习资料(附讲解~~):https://edu.51cto.com/course/35092.htmlhttps://edu.51cto.com/course/31545.html以一些关于【数据分析】的学习资料和大家一起分享一下:https://edu.51cto.c...
花了很久很久,总是监听不到 10000 端口,最后原因找到,是因为我的hive.server2.thrift.bind.host 写错了。看起来好像localhost也可以,不过输入hostname 查看,但是这个怎么这么奇怪,还不知道为什么会这样。然后,我改了一下 hive.server2.thrift.bind.host,保持和输出一致。被这个 localhost 给迷惑了了。然后重启,就能成
hive表show partitions时显示分区数与实际的分区数不符问题。
选择特定列查询1.2 列起别名重命名一个列案例实操1.3 常用函数1.求总行数(count)2、求工资的最大值(max)3、求工资的最小值(min)4、求工资的总和(sum)5、求工资的平均值(avg)1.4 limit 语句典型的查询会返回多行数据。limit子句用于限制返回的行数。1.5 where 语句1、使用 where 子句,将不满足条件的行过滤掉2、where 子句紧随from子句3、
特性说明核心价值基于数据分布智能选择最优执行计划关键前提准确、及时的统计信息主要收益Join 性能提升 2~10 倍,减少资源浪费适用场景多表关联、复杂子查询、大表 Join推荐指数⭐⭐⭐⭐☆(需配套统计信息管理)💡CBO 不是“银弹”,而是“数据驱动优化”的基础设施。当你的 Hive 数仓进入中大规模阶段,建立统计信息收集机制 + 启用 CBO是性能调优的必经之路。通过合理使用 CBO,你可以
我整理的一些关于【Java】的项目学习资料(附讲解~~)和大家一起分享、学习一下:https://d.51cto.com/bLN8S1连接 Hive 驱动下载及使用指南Hive 是一个构建在 Hadoop 之上的数据仓库软件,它能够提供数据的查询和分析功能。为了使用 Hive,我们通常需要通过 JDBC 驱动来连接 H...
在shell脚本里,删除hive分区时,如果该分区不存在,会报错,可以使用if exists 判断。
我整理的一些关于【数据】的项目学习资料(附讲解~~)和大家一起分享、学习一下:https://d.51cto.com/eDOcp1Hive中查看所有表的字段在大数据处理的过程中,Hive是一个非常重要的数据仓库工具,用于存储和管理海量数据。当需要对表的结构进行了解时,查看所有表的字段是非常必要的。本文将介绍几种方法,帮...
如果在目录datax/plugin/writer 中直接解压,解压后需要把starrockswriter.tar.gz删掉。下载地址https://github.com/StarRocks/DataX/releases。StarRocks官方提供了DataX的Writer插件。解压至目录datax/plugin/writer。
我整理的一些关于【Hive,正则表达式,字段】的项目学习资料(附讲解~~)和大家一起分享、学习一下:https://d.51cto.com/bLN8S1如何在Hive中判断字符是否全是中文的正则表达式在大数据处理和分析中,使用Hive进行数据查询和处理已成为一种流行的选择。如果你在处理文本数据时需要判断某个字段的内容是...
小文件的问题有很多,实际中各种原因,由于自己的不小心,前期没有做好预防都会产生大量小文件,让线上的离线任务神不知鬼不觉,越跑越慢。上面是平时开发数据任务时候,小文件的预防,但如果由于我们的大意,小文件问题已经产生了,就需要解决了。,这种表最坑,每天都会有一个快照,到后面10G大小的数据,表文件体积可以达到600G,时间越长越大;失败,数据没了,这里面是有事物性保证的,可以观察一下执行的时候,在te
本文详细介绍了使用DataGrip连接Hive的完整流程:1)下载安装最新版DataGrip并配置非商业许可证;2)启动HDFS和HiveServer2服务;3)创建项目并配置Hive数据源连接;4)新建数据库操作。同时提供了常见问题解决方案:注释乱码处理、索引报错忽略、内存溢出调整(修改hive-env.sh配置HADOOP_HEAPSIZE)、JSON表字段显示异常(修改hive-site.x
1.2 在 mysql 修改hive元数据表注释和字段注释的编码为 utf-8。修改表字段注解和表注解。
我整理的一些关于【数据】的项目学习资料(附讲解~~)和大家一起分享、学习一下:https://d.51cto.com/eDOcp1Hive 时间范围筛选的实现在大数据的处理与分析中,Hive是一个非常常用的工具,它提供了类似SQL的查询语言来处理存储在Hadoop上的数据。在很多情况下,我们需要对时间范围进行筛选,以便...
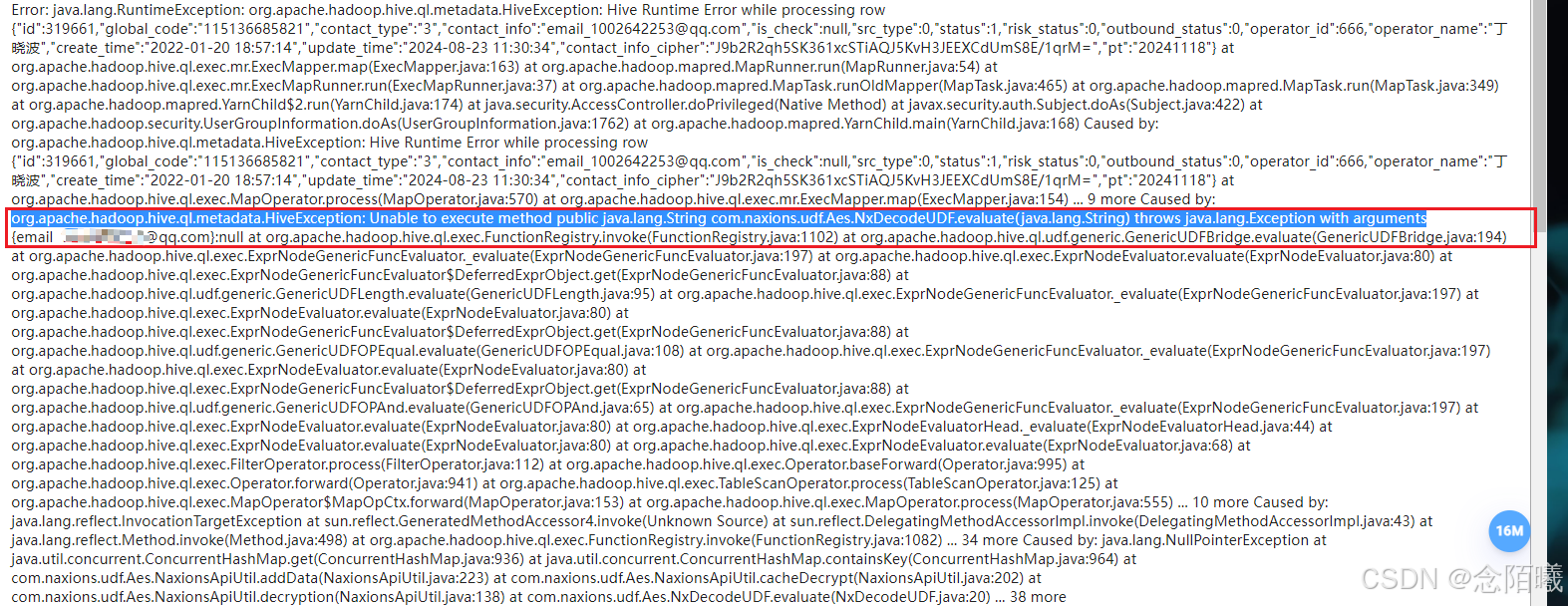
奇怪,数据不是被过滤掉了么,如下图,怎么还会传入最后的UDF函数报错。脚本执行,报错后查看Yarn执行日志,发现报错如。,大致原因是:自定义的UDF函数传入了错误的参数。被提前过滤,原因找到,应该是cbo自动优化导致。的条件过滤改在了在reduce阶段执行。在查找错误数据后发现错误数据的。
分区------处理海量数据根据数据文件结构考虑分门别类保存(大化小),使用分区,创建分区表,提高查询效率指定分区字段,分区字段被称为伪列。数据文件中没有和分区字段对应的数据分区可以分为一级分区(分区字段是一个字段),二级分区(分区字段是二个)。。。。。。分区可以是静态分区(导入数据时 ,指定分区字段的值)动态分区(导入数据时,不需要指定分区字段的值,由系统根据数据文件的情况自行判断)。
通常指大小远小于 HDFS 块大小(默认 128MB 或 256MB)的文件。例如,一个只有几MB甚至几KB的文件。场景推荐方法设计阶段使用 ORC/Parquet 格式;合理设计分区和分桶策略。数据写入时在INSERT语句中使用控制 Reduce 数量;在 Spark 中使用coalesce。对已有 ORC 表治理首选,高效且资源消耗小。对其他格式表治理使用查询。冷数据归档考虑使用创建 HAR
对于数据量的统计,从表是否分区分为和两者有着不同的统计方式。
给大家整理了一些有关【Hive,权限管理】的项目学习资料(附讲解~~):https://edu.51cto.com/course/31545.htmlhttps://edu.51cto.com/course/31877.html如何创建Hive新账号:新手指南在追求大数据的时代,Hive作为一种数据仓库工具被广泛使用...
bandwidth100-m100代表每个map传送的宽带是每秒100mb,-m指的是启动100个map。同步方式很多,导出sql,用工具navicat,同步脚本。hive有2种表方式,磁盘和关系型数据库,一般我们都是用mysql,2者操作一样。hive有2种存储方式,存磁盘或者hdfs,2者操作一样,磁盘就scp过去。然后进入迁移后的表,迁移数据后,进入hive在将这个建表sql建立一下。,那么
impala/hive获取所有表分区信息
意味着你选择了一条。
【代码】hive存储过程。
修改hadoop安装路径下的log4j.properties文件,这个文件的上两级,是,hadoop,etc。前提须知:首先我先开启hadoop,在hadoop安装路径下的sbin下,打开cmd.然后输出的结果,就被日志团团包围了。找我想要的结果,要找半天。hadoop,和hive,mysql.都之前安装好了。修改后是:log4j.threshold=ERROR.于是我就在网上找寻答案,找了半天才
Kettle 是「全能型ETL工具」,适合需要复杂转换和内置调度的场景,上手快、可视化强;DataX 是「高性能同步工具」,适合简单数据传输和大数据量场景,配置灵活、资源占用少。根据你的业务需求(是否需要复杂转换、数据量大小、部署环境)选择即可,两者均是开源领域的成熟工具,稳定性和社区支持都有保障~
为什么Doris比Hive快?——一个入门开发者的实战指南在大数据的生态系统中,我们常常会比较不同数据处理框架的性能。Doris和Hive是两种常见的框架,前者以其快速的查询性能而闻名。今天,我将带你一起探讨为什么Doris比Hive快,并通过一系列步骤和示例代码来帮助你理解这个过程。流程概述在我们深入了解Doris...
Hive新增列查询为NULL问题解析 原因: 插入数据时未显式给新列赋值,默认填充NULL 动态分区或列顺序错位导致数据映射错误 Parquet/Avro等文件格式的旧数据未更新schema 解决方案: 显式指定新列值(INSERT...SELECT col1, col2, 'default') 严格匹配SELECT与表结构的列顺序 对旧数据执行INSERT OVERWRITE重建文件 分区表需单
CASCADE关键字,通常在更改表结构的语句之后出现,它的作用就是让hive去刷新历史数据,比如你在新增一个表字段的时候,你不加CASCADE关键字,就会造成表中已有数据的对应该字段为NULL,甚至有的时候旧的数据不认这个字段,因此在更改表结构的时候要带上这个关键字。
设置hive本地模式
在 Hive 中,字符串拼接是一种常见的操作,用于将多个字符串连接在一起形成一个新的字符串。这在数据处理和分析过程中经常会用到,比如将不同列的值拼接成一个完整的信息、拼接成文件路径等等。
好的,我们来详细解释一下 Hive 中的视图和 Doris 中的物化视图的区别。这两者在概念和实现上有显著的不同:简单来说:
本文介绍了ClickHouse数据库的三种数据迁移方法:1. 常规备份导出方式:通过Shell脚本分步骤导出表结构(SQL文件)和表数据(TSV文件),并提供了压缩/解压缩命令;2. 服务器间直接迁移:使用remote函数实现ClickHouse实例间的数据迁移;3. 使用DBeaver等数据库工具进行导出导入。文中详细给出了导出表结构和数据的Shell脚本示例,以及单表数据的导出导入命令,为Cl
exlpode () 就只是拆分为多行,没有索引值,最后结果是一列,posexplode()拆分为多行,同时带着索引的结果,最后结果是两列。例如对 数组 ['a','b','c'] 进行拆分,使用explode(arrary(('a','b','c'))) as name。使用 posexplode(arrary(('a','b','c'))) as (id,name)得到的结果是。在按照位置拼接
Hive Dialect 在 Flink 中支持 HiveQL 的主要查询功能,包括排序、聚合、连接、窗口函数等常见操作。语法结构遵循标准 Hive 查询模板,支持 WHERE 过滤、GROUP BY 聚合以及多种排序方式(ORDER BY/CLUSTER BY/DISTRIBUTE BY)。使用时需先配置 HiveCatalog 并切换方言,注意全局排序 ORDER BY 在大数据集上性能较差,
数据仓库
——数据仓库
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 openEuler 社区
openEuler 社区



 AI编程社区
AI编程社区