登录社区云,与社区用户共同成长
邀请您加入社区
谷云ETLCloud通过轻量化数据底座与AI智能体融合,实现数据自动流转与业务闭环,搭载AI异常分析、Java/SQL自动生成三大功能,降低开发运维门槛,助力企业低成本快速完成智能化转型。
本实验基于助睿Max蓝图编辑器,将MySQL数据库中的数据动态接入浏览器市场分析大屏的各图表组件。实验首先创建数据库连接,将静态布局的图表组件导出至蓝图编辑器,通过SQL请求节点查询browser_coverage等6张数据表。利用并行数据处理节点实现查询结果的分发转换,最终将格式化数据绑定至柱状图、饼图等可视化组件。实验重点训练了数据源配置、SQL查询编写、数据处理逻辑实现等技能,使学生掌握零代
本文针对ETL过程中多源异构文件数据抽取的难点,基于助睿ETL平台,以零代码方式演示了CSV、TXT、Excel三种文件数据的读取、解析与加工流程,涵盖日期差值计算、绩效等级评定、字段筛选与剔除等典型操作。实验结果表明,平台对多类型文件具有良好的兼容性与处理效率,各组件协同顺畅,业务规则落地准确,为数据集成初学者和企业快速数据加工场景提供了可复用的实践参考。
本次实验以助睿数智(Uniplore)ETL一站式零代码平台为工具,从实践角度系统覆盖了CSV、自定义分隔符文本(TXT)以及 Excel三种异构文件格式的数据抽取与预处理全流程。1. 掌握了多种文件输入组件的核心配置方法CSV文件输入组件不仅可读取逗号分隔的标准CSV,还可通过自定义分隔符读取分号、制表符等分隔的文本文件;Excel输入组件需要依次完成文件选择、工作表定位和字段解析的正确操作流程
摘要 本文介绍了助睿ETL平台中文件数据抽取组件的使用方法,重点演示了从CSV、文本和Excel文件读取数据的操作流程。案例通过项目绩效评估的实际场景,展示了完整的ETL处理流程:从CSV文件读取项目数据,计算项目执行天数,并根据天数区间自动生成绩效等级,最终输出处理结果。实验基于助睿在线平台完成,涵盖文件获取、字段解析、数据计算(日期差)、条件判断(数值范围)和结果输出等关键ETL操作步骤,体现
本文介绍了基于助睿ETL平台的文件数据处理实验,包含CSV、TXT和Excel三类文件的抽取与转换流程。实验通过零代码操作实现了数据读取、字段筛选、计算处理和结果输出,验证了平台在数据预处理中的功能完整性。文章详细说明了各类型文件的操作步骤、配置要点和问题解决方法,并总结了平台优势(可视化操作、多格式支持等)和优化建议(路径简化、字段同步等)。实验结果表明该平台适合ETL入门教学,能有效培养数据集
如果你是一名数据工程师,一定经历过这样的早晨:打开邮箱,发现供应商丢过来一个.csv;五分钟后,财务同事又传来一个.xlsx,里面还藏着合并单元格;紧接着,运维同学扔给你一个.txt日志文件,分隔符是"肉眼不可见"的制表符……数据抽取(Extract),这个ETL流程中最"简单"的第一步,往往成为整个数据链路中最耗时、最磨人的环节。传统做法是什么?写Python脚本用,调Java的POI库解析Ex
摘要:在使用Datax运行ETL脚本时遇到字段错误,虽检查确认字段拼写、类型和数量均正确,但问题仍存在。最终发现是某些特定字段名(如"index"、"percent")导致冲突,将其重命名后问题解决。目前官方未说明具体原因,建议避免使用这些关键字作为字段名。
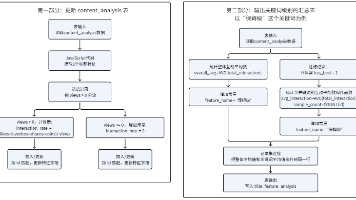
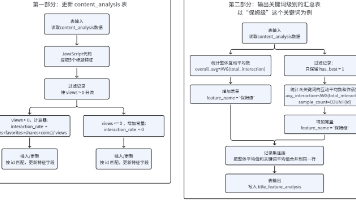
特征工程是数据分析与可视化前置的关键环节。原始明细表仅能记录基础数据,想要挖掘标题文案对作品互动效果的影响,就需要构造衍生指标、文本标签特征。本文基于实验 7-1 清洗完成的 content_analysis 明细表,使用助睿 ETL 完成指标计算、关键词识别、数据回填、关键词分组统计两套加工流程。全程零代码拖拽,附带 JavaScript 文本匹配实操方案。二元标签特征:文本关键词转为 0/1
PS:经查询资料,-XX:MaxMetaspaceSize 可替换掉原来旧版本的参数 (MaxPermSize),不替换所造成的影响可自行评估,我因为要直接用,就先删掉了。解决方案:编辑如下 Spoon.bat文件,将 "-XX:MaxPermSize=256m"删掉即可。经查询日志(如下截图)后,发现如果JDK板块在>=8时,”MaxPermSize“参数无法识别。
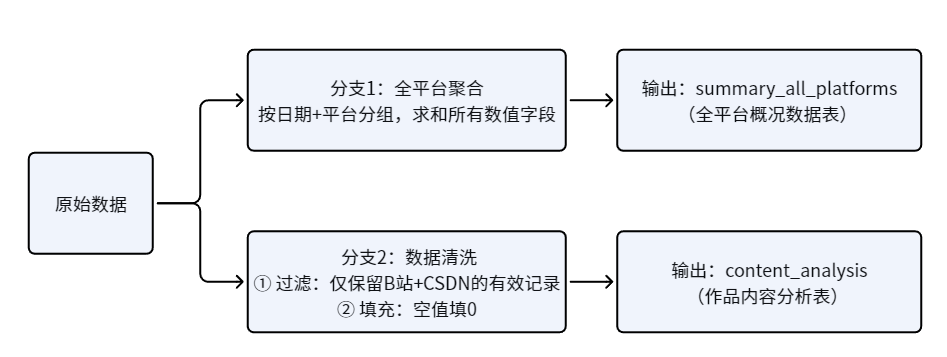
全程使用助睿ETL零代码操作,不用写一行代码,就能完成多源自媒体数据的过滤、填充、聚合、分支处理等核心操作,最终输出两张标准数据表,为后续数据可视化、特征工程、深度分析打下坚实基础。,只有规范干净的数据,才能产出精准、有价值的分析结论,为后续的自媒体内容特征分析、互动规律挖掘、可视化大屏搭建做好了充足铺垫。
谁懂大数据人做完数据清洗又遇新难题!好不容易把 B 站、CSDN 作品脏数据处理干净,看着一堆纯文本标题干瞪眼,想搞清楚什么标题更容易爆、哪些关键词拉高互动,总不能手动一条条标记统计吧?这次实训直接解锁完整流水线,不用手写复杂 Python、SQL,拖拽组件就能把文字标题变成可对比的数字指标,精准扒出平台流量关键词,作业直接拿高分,运营人拿来做选题复盘也巨好用!
在人工智能领域,有一条颠扑不破的铁律。喂给模型的是“垃圾数据”,得到的必然是“垃圾答案”。因此,数据质量是决定AI项目成败的。一个被低质量数据污染的系统,会因频繁出错而彻底失去用户的信任。如何将“垃圾”变为“黄金”?与。它们是我们构建可靠AI系统的第一道,也是最重要的一道防线。
作为专业智能创作助手,我将逐步引导您了解如何使用 PySpark 实现大数据 ETL(Extract, Transform, Load)任务。PySpark 是 Apache Spark 的 Python API,专为大规模数据处理设计,特别适合高效处理分布式数据。ETL 过程包括数据提取、转换和加载,是数据仓库和数据分析的核心环节。本指南将从基础环境设置开始,逐步讲解每个步骤,并提供可运行的 P
照片由 Produtora Midtrack 拍摄并从 Pexels.com 获得的照片当构建一个新的 ETL 管道时,考虑三个关键要求至关重要:泛化性、可扩展性和可维护性。这些支柱在数据工作流程的有效性和持久性中
本文提出了一种基于DeepSeek的智能ETL架构,通过认知驱动替代传统规则驱动,解决非结构化数据处理难题。。这种架构可广泛应用于日志解析、简历处理、合同提取等多种非结构化数据转换场
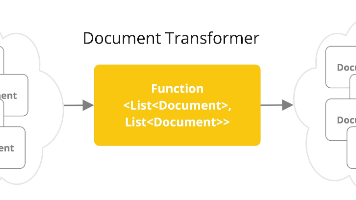
本文介绍了Spring AI中的ETL(提取、转换、加载)管道框架,该框架是构建检索增强生成(RAG)应用的基础组件。主要内容包括: ETL管道的三个核心接口: DocumentReader:从各种数据源(如PDF、JSON、文本文件)读取文档 DocumentTransformer:对文档进行转换处理(如文本分割) DocumentWriter:将处理后的文档写入存储(如向量数据库) 典型ETL
本文介绍了助睿ETL平台处理多种文件数据的实操案例,包括CSV、文本和Excel三种常见格式。案例演示了从数据获取、字段筛选到结果验证的完整流程:通过「CSV文件输入」组件计算项目绩效,利用「字段选择」组件处理足球比赛文本数据,以及使用「Excel输入」组件筛选购房者关键字段。平台支持零代码操作,实现从数据接入到输出的全链路处理,验证了ETL核心的数据抽取、转换能力,为后续数据分析奠定基础。该教程
Ware-Smith 是一套基于 [AI IDE] Skill 体系的开源数据建模骨架(Skeleton),它解决的是:当你把数据开发交给 AI 时,如何保证它不乱来。
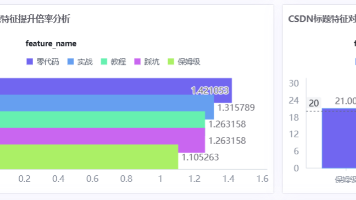
常量字段的作用就是为每行统计结果附加一个"身份标签",向数据下游明确标识"这一行是保姆级关键词的统计结果"。接着,依次接入"排序记录"和"分组"组件,按id升序排列后,分别计算AVG(total_interaction)得到avg_interaction(关键词平均互动量),以及COUNT(id)得到sample_count(样本数量)。第二类:标题特征标签。首先,从表输入组件引出另一条并行分支,
重点演示了三种常见文件格式(CSV、TXT、Excel)的数据抽取与处理流程。实验包含三个模块:1)CSV项目文件处理,计算工期并分级绩效;2)TXT足球赛事数据精简,移除无关字段;3)Excel购房者信息筛选。通过可视化拖拽组件,完成数据读取、字段选择、计算转换等操作,验证了零代码平台处理结构化文件的能力。实验结果表明该平台能有效支持企业数据交换场景,为后续复杂数据处理奠定基础。
摘要: 本次实验基于已清洗的自媒体运营数据(实验7-1),通过助睿ETL平台完成特征工程构建,目标包括: 衍生指标:计算单作品总互动量(点赞+收藏+分享+投币),量化内容热度; 文本特征:利用JavaScript组件匹配标题关键词(如“保姆级”“零代码”),生成0/1二分类标签; 数据分层输出:增量更新原作品明细表(新增特征字段),并新建关键词汇总表(统计各标题词的平均互动效果); 核心技巧:通过
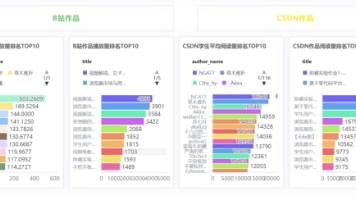
摘要: 本次实验利用助睿ETL零代码工具对多平台自媒体互动数据进行清洗与预处理。通过双分支处理设计,分别输出全平台汇总统计表(保留原始数据)和重点平台(B站、CSDN)精细化明细表(剔除无效记录、填充缺失值)。实验解决了数据冗余、字段缺失等问题,并采用多条件筛选、字段精简等操作,确保数据质量。核心收获包括掌握ETL分支处理逻辑、缺失值标准化方法及宽表设计理念,为后续特征工程和可视化分析奠定数据基础
💡 "插入/更新"与"表输出"的本质区别:如果使用"表输出",每次运行都会追加新行,日积月累会造成大量重复数据。聚合完成后,接入"增加常量"组件,新增 feature_name 字段并赋值为"保姆级",为这一行数据标记上名称标签,便于后续与关键词分支的数据做关联。完成一个关键词的完整流程后,其余四个关键词(零代码、实战、教程/指南、踩坑)的处理方式完全相同——直接复制整个转换流分支,只需修改两处
互联网的文字海里,最不缺的就是自嗨。最近深扒内容运营的数据黑盒,我一直死磕一个灵魂拷问:标题里到底塞什么词,才能让数据好看得令人心动?于是,我顺手爬了5702条B站和CSDN的野生数据,来了一场蓄谋已久的“特征工程”实战。从抽丝剥茧提取词根,到互动指标的暴力聚合,再到最后用Lift提升度看透爆款真相——全程零代码ETL丝滑跑通,没敲一行SQL。踩过坑,也见过光,权当一份数据人的深夜告白,且看且分享
完成「字段选择」组件的配置后,拖拽「计算器」组件至画布,建立从「字段选择」组件到「计算器」组件的连接,此时弹出的提示框中有两个可选值:主输出步骤和错误步骤。新字段是指计算逻辑输出的字段,计算公式指数据的计算方法,字段A/B/C是指计算逻辑的输入数据。该平台覆盖数据接入、ETL数据加工、AI机器学习建模、数据可视化展示全业务链路,全程支持零代码可视化拖拽操作,操作门槛低、实用性强,既适配高校大数据、
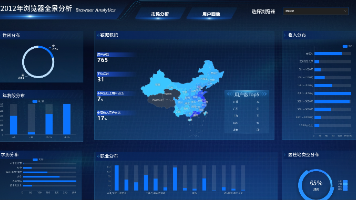
本文是Uniplore助睿实验平台「浏览器用户画像分析」实验的全流程指南,主要包含三大模块:静态布局制作、数据接入与交互联动配置。指南提供了可复用的SQL和蓝图节点代码,适配零代码开发,帮助用户快速搭建企业级数据大屏。实验基于用户画像统计表,通过蓝图编辑器实现筛选器联动、数据刷新和地图下钻等交互功能,涵盖从组件布局到动态交互的全链路开发。文中详细介绍了各模块的实现步骤、避坑技巧和常见问题解决方案,
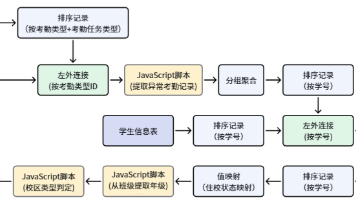
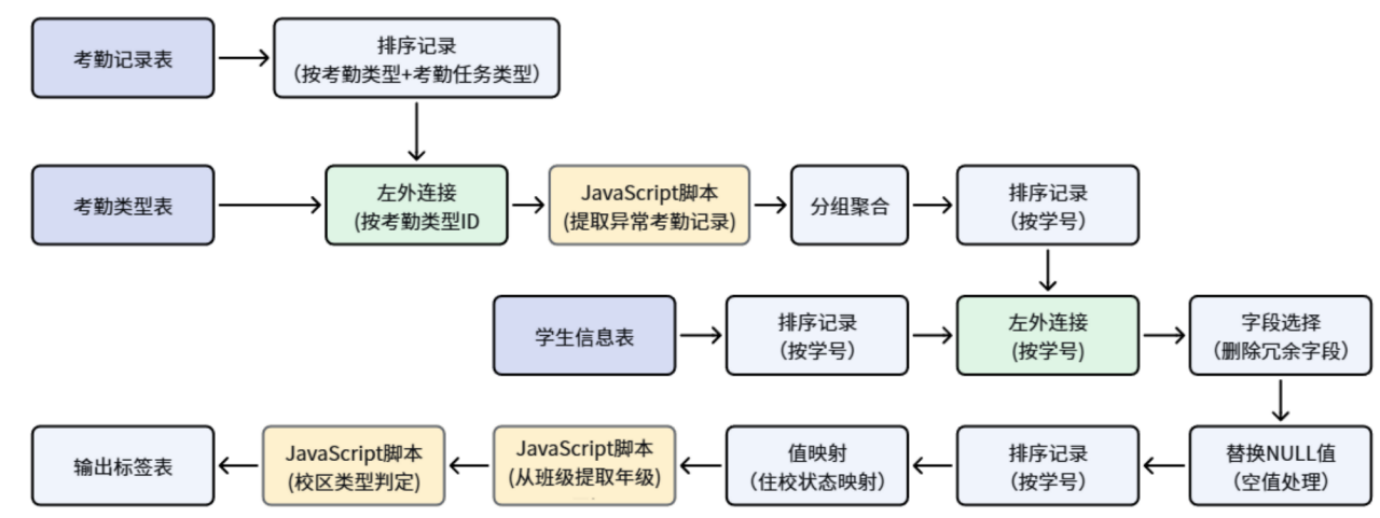
本文介绍了使用助睿数智平台构建学生考勤主题标签的实验过程。实验通过零代码ETL工具完成数据接入、清洗、关联和标签计算全流程,包括:1) 创建原始数据表并导入CSV数据;2) 对学生基础信息进行标准化处理;3) 关联考勤记录与考勤类型数据;4) 使用JavaScript脚本识别异常考勤行为;5) 分组统计各类考勤指标;6) 输出最终标签宽表。实验解决了字段提取、空值处理等常见问题,验证了平台在数据处
本文是基于零代码 ETL 平台的电商订单利润分流实训笔记,完整记录了从数据读取、多表关联、字段清洗到条件分流、结果导出的全流程,并整理了新手高频踩坑点与解决方案,适合大数据入门 / ETL 新手参考学习。
坑现象怎么爬出来的JavaScript自赋值报错"找不到字段[has_best]"删掉var和,直接赋值字段名混淆插入/更新U=0计算器输出叫,表字段叫,映射时别写反过滤条件不匹配过滤记录W=0确认上游数据已正确写入,数值类型才能用,字符串要用""分组字段为空为NULL检查是不是字符串,是的话先转数字字段重名platform_1报错记录集连接后加"字段选择"把platform_1扔掉保留关键字ra
其自主研发的SharkData平台,作为覆盖企业数据资产全生命周期管理的全局数据智能一体化底座,为企业提供集数据采集、研发、服务、管控和运维为一体的解决方案。传统数据集成与处理架构中,特定厂商工具在过去发挥了重要作用,但随着信创合规标准的严格执行,寻找具备对等技术实力的信创ETL软件以平滑接替原有架构,满足国产化认证与自主可控要求,已成为行业的必然方向。同时,SharkData配套专属的数据校验工
摘要 本实验基于助睿数智平台,系统性地展示了自媒体运营数据分析全流程。实验分为三个阶段:1) 数据清洗与预处理,通过ETL工具完成多源数据过滤、填充和聚合;2) 特征工程构建,利用JavaScript代码实现标题关键词自动标注并计算互动指标;3) 可视化分析,使用BI工具创建多维度仪表盘,包含指标卡、排名图和趋势分析。实验采用分支处理设计,同时支持全平台概览和重点平台深度分析,最终形成数据驱动的运
本文介绍了基于"数智教育"大赛数据集的学生多维度考勤统计ETL实验。实验使用助睿零代码平台,通过7张核心业务表构建考勤分析模型,重点处理3张关键表(考勤主表、考勤类型码表、学生信息表)形成星型结构。实验设计了基础属性、画像维度和考勤行为三类标签,详细说明了字段处理口径和统计逻辑,如迟到次数需排除请假记录等。实验步骤包括创建项目、导入数据、配置ETL流程等,最终实现自动化考勤统计,解决人工统计效率低
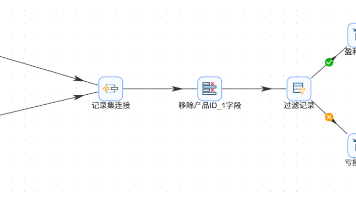
本文记录了在助睿数智(Uniplore)一站式数据科学实验平台上完成的ETL入门实验。实验通过零代码拖拽方式,将订单明细表与产品信息表关联,计算利润后按正负值分流为盈利订单和亏损订单,并分别输出到Excel文件。实验详细介绍了平台登录、团队管理、项目创建、数据同步等准备工作,以及转换流设计的具体步骤,包括表输入、记录集连接、字段选择、过滤记录等组件的配置方法。该实验帮助初学者掌握数据集成平台的基本
本实验基于自媒体多平台数据,使用助睿ETL与BI工具完成数据清洗、特征构建到可视化分析的全流程。通过分支处理输出全平台概况与重点平台分析表,量化标题关键词对互动的提升效果。实验验证了零代码ETL的高效性,核心收获是确立了“数据驱动运营决策”的思维,从数据清洗到可视化提炼可落地策略。
本文提出了一种基于JDBC DatabaseMetaData接口的统一元数据同步方案,用于解决ETL/数据集成平台中多源数据库元数据管理难题。方案核心思路是通过标准JDBC接口获取元数据,替代传统直接查询各数据库系统表的方式,实现"一次编写、多库通用"。系统采用三层元数据结构(Schema-Table-Column/Index/PK/FK),通过异步线程池和增量更新机制实现高性
摘要: 本实验基于全班同学在多个自媒体平台的作品互动数据,利用助睿ETL工具完成数据清洗与预处理,生成两张核心数据表:全平台概况表(保留所有平台原始数据)和内容分析表(聚焦B站、CSDN有效数据)。实验重点包括:理解数据清洗的必要性,掌握ETL工具的筛选、填充、聚合等操作,通过分支处理满足仪表盘对不同数据的需求。关键步骤包括过滤无效记录、填充缺失值、字段选择及分平台聚合统计。最终输出结构化数据表,
本文介绍了基于助睿BI平台搭建自媒体运营可视化仪表盘的实验过程。实验利用预处理后的三张数据表,从整体概况、学生排名、标题关键词、平台对比和时间趋势五个维度进行分析。通过指标卡、排名图表、关键词提升倍率分析和趋势折线等可视化方式,对比B站和CSDN平台的运营数据差异,重点分析标题关键词对流量的影响。实验过程中解决了数据字段缺失、指标计算异常等问题,最终形成了包含顶部指标卡和左右分栏平台分析的完整仪表
etl
——etl
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 EazyDevelop社区
EazyDevelop社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区








 龙虾开发者社区
龙虾开发者社区






 科技大视野开发者社区
科技大视野开发者社区